本文主要是介绍GAN:SNGAN-谱归一化GANs,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:https://arxiv.org/pdf/1802.05957.pdf
代码:GitHub - pfnet-research/sngan_projection: GANs with spectral normalization and projection discriminator
发表:2018 ICLR
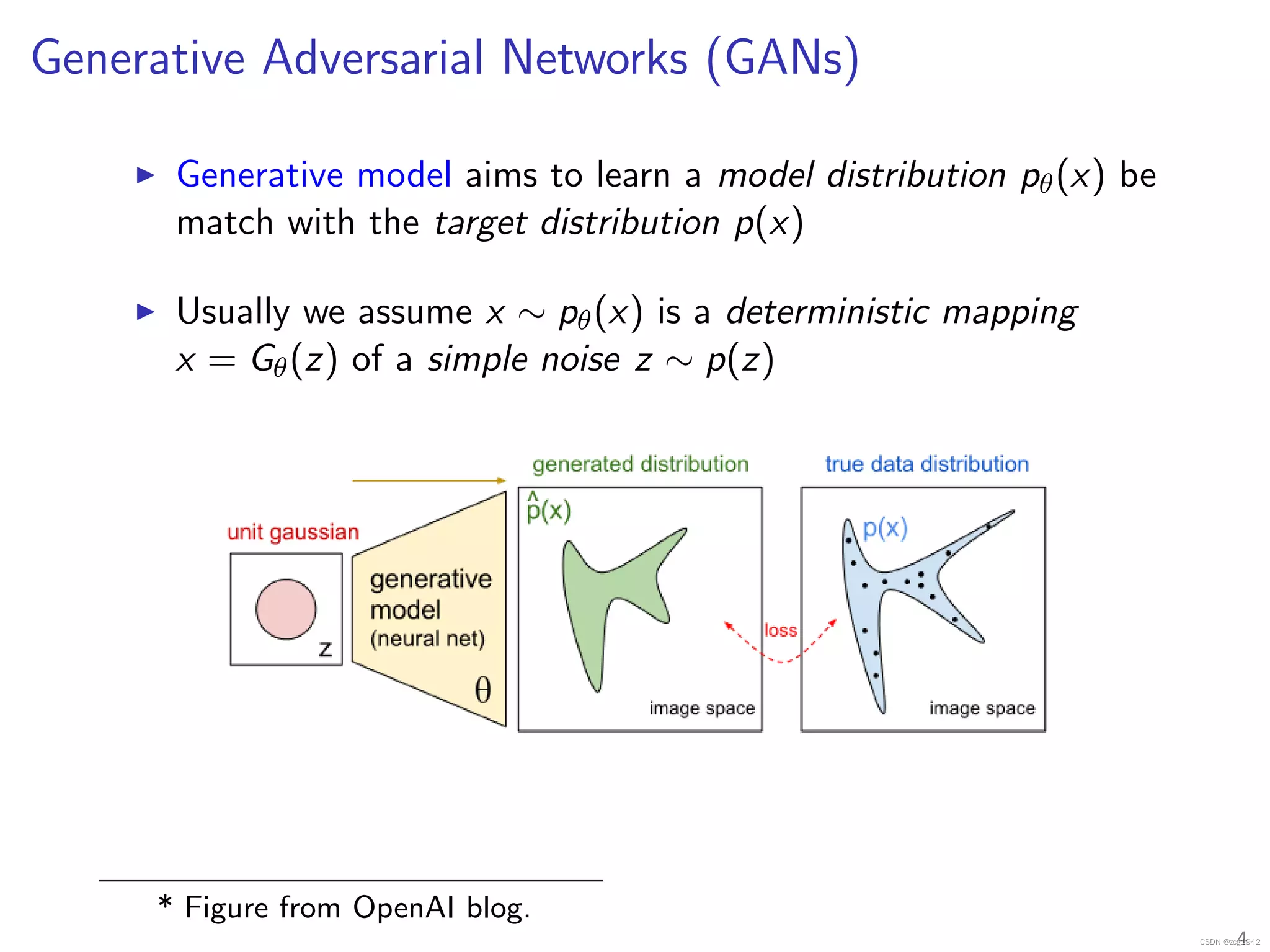
摘要
GANs的主要挑战是:训练的稳定性。本文作者提出一种新的权重归一化:spectral normalization(谱归一化)来帮助稳定训练GANs。SN-GAN只需要改变判别器权值矩阵的最大奇异值,这种方法可以最大限度地保存判别器权值矩阵的信息,这个优势可以让SN-GAN使用类别较多的数据集作为训练数据,依旧可以获得比较好的生成效果。此外,SNGAN使用power iteration(迭代法),加快训练速度。

本文方案的优点:仅有一个超参数,调整简单。并且实现简单,计算量小。

谱归一化的引入
这篇文章给出了比较好的解释:我这里借鉴一下
生成模型的训练可以作为 W 距离下的一个最小-最大问题:

第一个 arg max 试图获得 W 距离的近似表达式,而第二个 arg min 则试图最小化 W 距离。然而,T 不是任意的,需要满足 ‖T‖L≤1,这称为 Lipschitz 约束(L 约束),该怎么施加这个约束呢?
L约束:目前有3种方案
- 权重裁剪
这是 WGAN 论文提出的方案:在每一步的判别器的梯度下降后,将判别器的参数的绝对值裁剪到不超过某个固定常数。这是一种非常朴素的做法,现在基本上已经不用了。其思想就是:L 约束本质上就是要网络的波动程度不能超过一个线性函数,而激活函数通常都满足这个条件,所以只需要考虑网络权重,最简单的一种方案就是直接限制权重范围,这样就不会抖动太剧烈了。
这篇博文的观点:WGAN利用Wasserstein距离代替原始GAN中的JS距离,但是为了去衡量Wasserstein距离判别器必须要满足Lipschitz假设,Lipschitz就是让模型对输入的细微变化不敏感。在WGAN中是直接对判别器的参数做裁剪,迫使参数在[−c,c][−c,c]之间,这种操作的方法算是改变了权值矩阵的最大奇异值,多少会造成信息损耗。
- 梯度惩罚
这是 WGAN-GP 论文提出的方案:这种思路非常直接,即 ‖T‖L≤1 可以由 ‖∇T‖≤1 来保证,所以干脆把判别器的梯度作为一个惩罚项加入到判别器的 loss 中:

但问题是我们要求 ‖T‖L≤1 是在每一处都成立,所以 r(x) 应该是全空间的均匀分布才行,显然这很难做到。所以作者采用了一个非常机智(也有点流氓)的做法:在真假样本之间随机插值来惩罚,这样保证真假样本之间的过渡区域满足 L 约束。显然,它比权重裁剪要高明一些,而且通常都 work 得很好。但是这种方案是一种经验方案,没有更完备的理论支撑。
这篇博文的观点:WGAN-GP中使用gradient penalty 的方法来限制判别器,但这种放法只能对生成数据分布与真实分布之间的分布空间的数据做梯度惩罚,无法对整个空间的数据做惩罚。这会导致随着训练的进行,生成数据分布与真实数据分布之间的空间会逐渐变化,从而导致gradient penalty 正则化方式不稳定。此外,WGAN-GP涉及比较多的运算,所以训练也比较耗时。
- 谱归一化
这是 SNGAN 论文提出的方案:本质上来说,谱归一化和权重裁剪都是同一类方案,只是谱归一化的理论更完备,结果更加松弛。而且还有一点不同的是:权重裁剪是一种“事后”的处理方案,也就是每次梯度下降后才直接裁剪参数,这种处理方案本身就可能导致优化上的不稳定;谱归一化是一种“事前”的处理方案,它直接将每一层的权重都谱归一化后才进行运算,谱归一化作为了模型的一部分,更加合理一些。
尽管谱归一化更加高明,但是它跟权重裁剪一样存在一个问题:把判别器限制在了一小簇函数之间。也就是说,加了谱归一化的 T,只是所有满足 L 约束的函数的一小部分。因为谱归一化事实上要求网络的每一层都满足 L 约束,但这个条件太死了,也许这一层可以不满足 L 约束,下一层则满足更强的 L 约束,两者抵消,整体就满足 L 约束,但谱归一化不能适应这种情况。
GANs的难点
GANs训练中的一个持续挑战是鉴别器的性能控制。在高维空间中,鉴别器的密度比估计通常是不准确的,并且在训练过程中不稳定,所以生成器网络无法有效学习目标分布的模式结构。更糟糕的是,当模型分布和目标分布是不相交的,存在一个可以完全区分模型的鉴别器目标的分布。一旦这种情况发生:生成器的训练会完全停止,因为此时判别器的导数总会为0。
训练速度
SNGAN:使用power iteration(迭代法),加快训练速度。
WGAN-GP:使用gradient penalty后,模型在梯度下降的过程中相当于计算两次梯度,计算量更大,所以整体训练速度就变慢了。
参考
1:SN-GAN论文解读 | TwistedW's Home
2:WGAN-div:默默无闻的WGAN填坑者(附开源代码) - 知乎
3:为什么spectral norm对应的SNGAN未使用WGAN的loss? - 知乎
4:GAN的优化(四):奇异值与SNGAN - 知乎
这篇关于GAN:SNGAN-谱归一化GANs的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!