本文主要是介绍论文阅读[2022sigcomm]GSO-Simulcast Global Stream Orchestration in Simulcast Video,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GSO-Simulcast Global Stream Orchestration in Simulcast Video
作者:

1 背景
1视频会议成为全球数十亿人远程协作、学习和个人互动的核心,这些不断增长的虚拟连接需求推动视频会议服务的蓬勃发展
2当前用户越来越希望在低延迟下看到更高质量的视频,对大型会议的需求越来越多,同时希望服务要容易获得
3视频停顿、声音停顿和视频模糊成为当前视频会议服务的前三大问题
2 挑战
1在大规模多方视频会议中提供高质量的实时媒体流
2会议的流畅性受到网络条件最差(慢链接)的参与者的严重影响
3现有方法例如转码会给服务器带来很大的负担,SVC存在编解码器兼容性问题,当前Simulcast存在视频和网络不匹配、易受上行链路拥塞的影响、在大规模会议中可管理性差的问题
3 贡献
1提出了第一个在全球范围内广泛部署的视频会议系统GSO-Simulcast,在大规模部署中显著改善了所有关键的QoE指标
2提出Knapsack-Merge-Reduction算法,大大减小计算消耗
4 关系工作与问题介绍
4.1 用户报告的问题
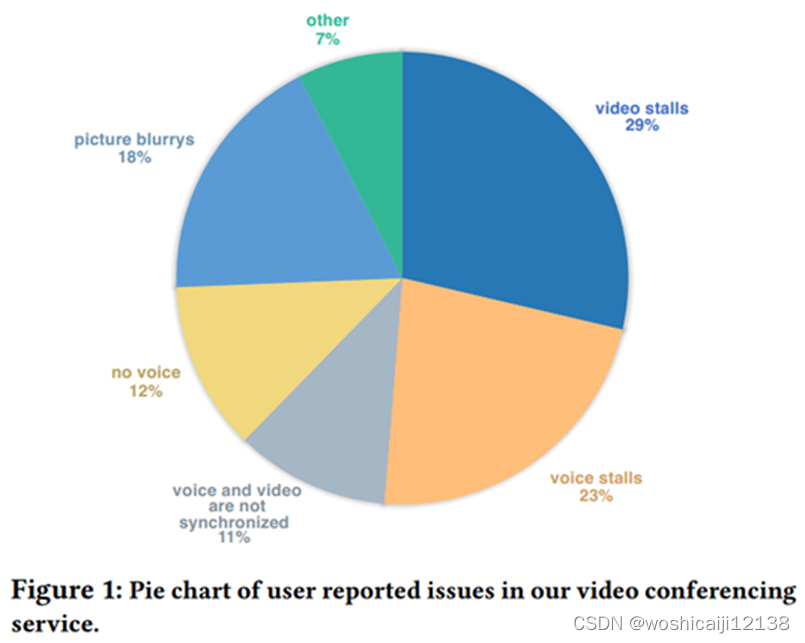
报告的前三大问题是视频停顿video stalls (29%)、声音停顿video stalls (23%)和视频模糊blurred videos (18%)
所有这些问题都是由慢链接问题引起的。
4.2 慢链接问题
多方视频会议面临的最大挑战之一是不同参与者所面临的异构网络条件
客户端以不同的比特率对视频源进行多次编码,并将这些流并行发送到SFU(selective-forwarding unit)服务器。SFU服务器根据接收方的网络约束为每个接收方选择一个流来转发。
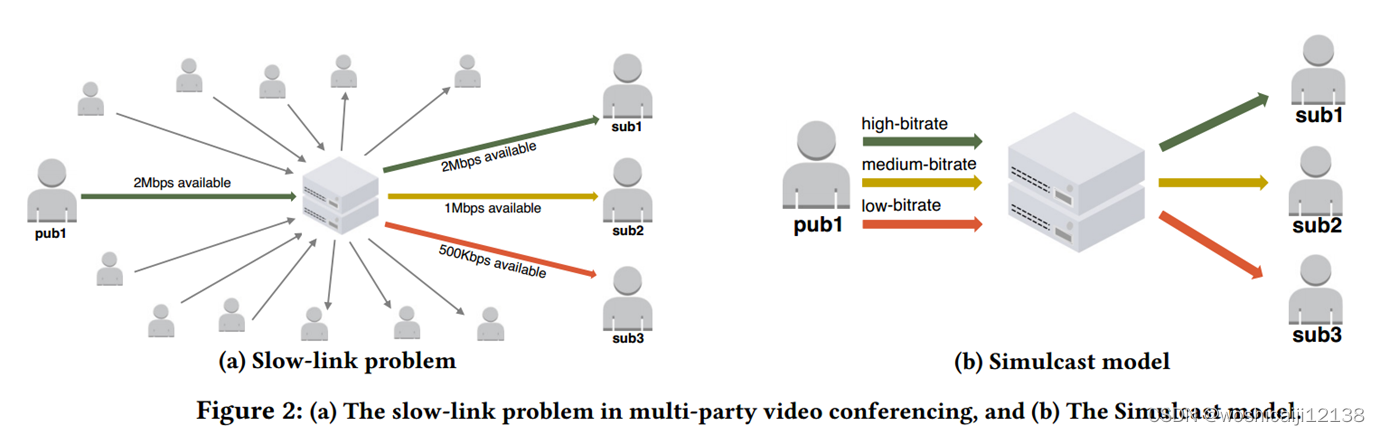
具体而言:
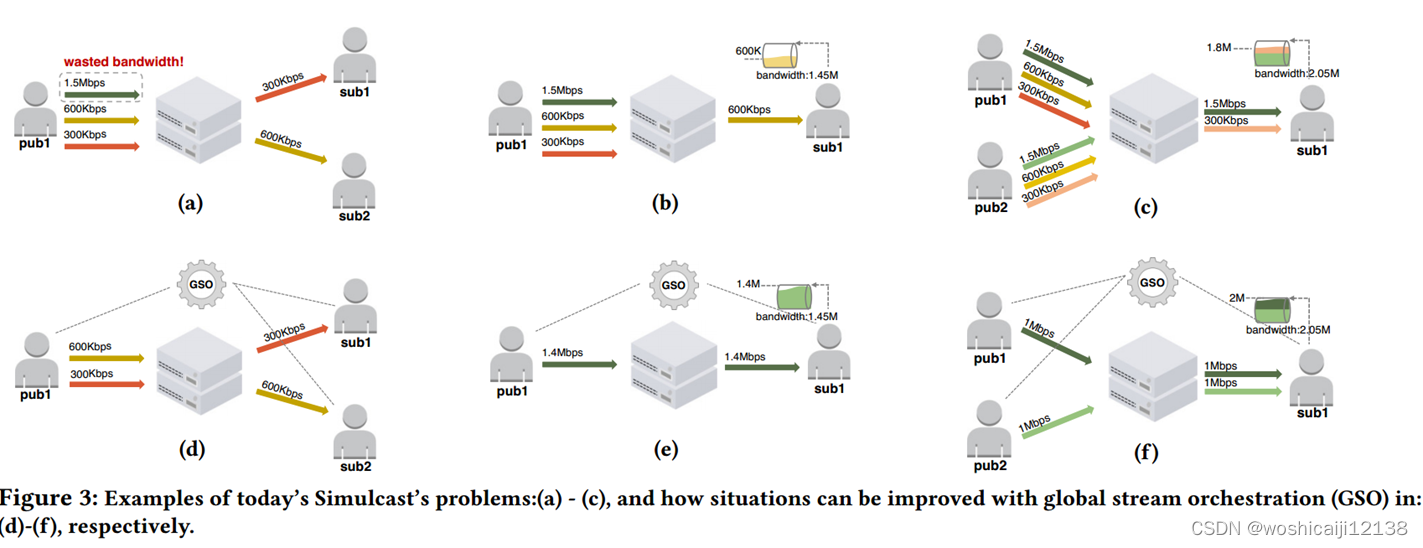
A.当发送者推送一个没有人订阅的流时,宝贵的网络资源就被浪费了
B.发送方不知道接收方的网络约束时,容易出现视频和网络不匹配
C.当接收方的下行带宽有限时,来自不同发送方的流被迫相互竞争
5 系统建模
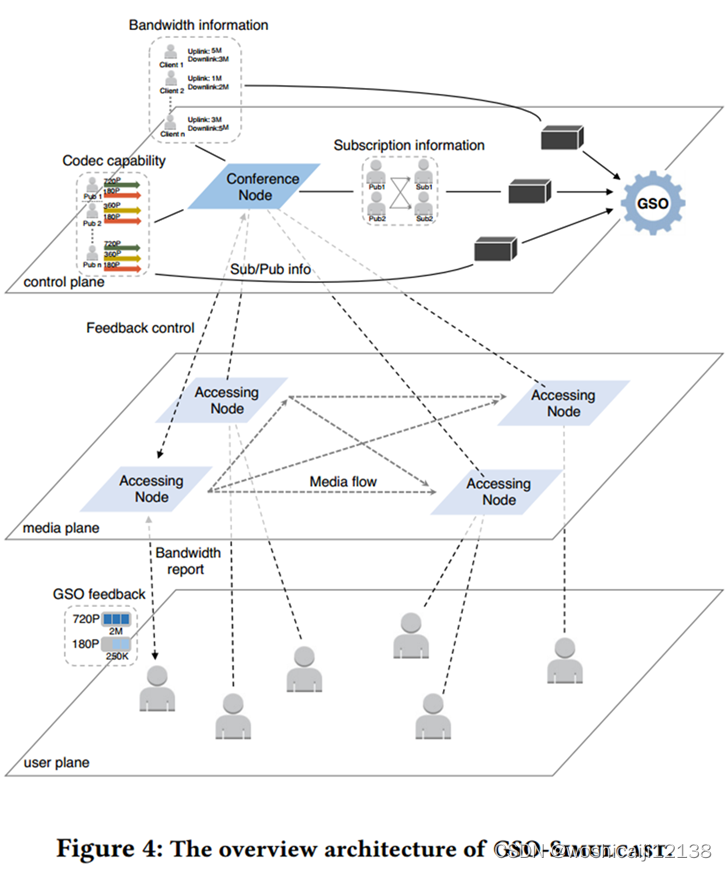
5.1 服务架构

5.2控制算法
算法在 (Knapsack-Merge-Reduction背包-合并-缩减)操作的迭代循环中执行,每一步处理一组特定的约束
目标:控制算法的目标是以最大的QoE效用满足每个订阅者的需求,同时遵守三组约束:网络带宽约束、编解码器能力约束和订阅约束。
网络带宽约束:对客户端i,订阅的流比特率之和不得超过 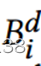
,而发布的流比特率之和不得超过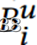
编解码器能力约束:对于每种分辨率,publisher可以以不同的细粒度比特率发送流,但一次只能发送一个流
订阅约束:一个订阅者(subscriber) 只允许从每个发布者(publisher) 中订阅至多一个流
A. Knapsack
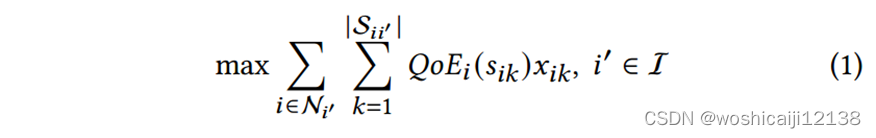
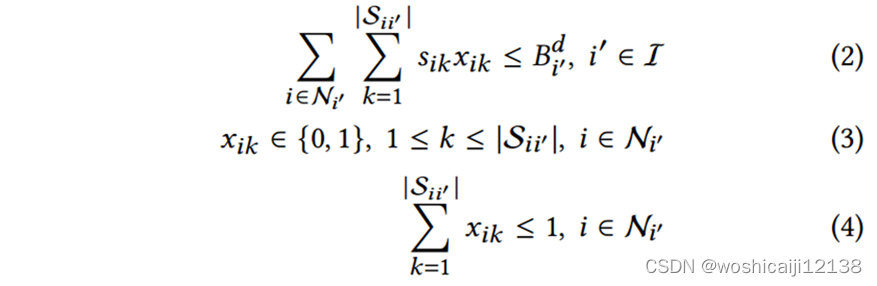

B. Merge
Step1的结果也等价地确定了包含要求每个发布者端i提供服务的订阅者和流对的集合
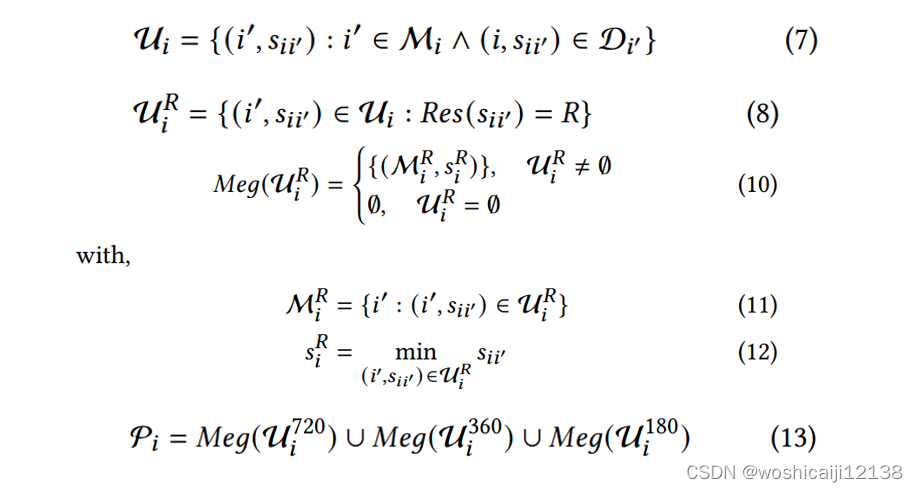
C. Reduction
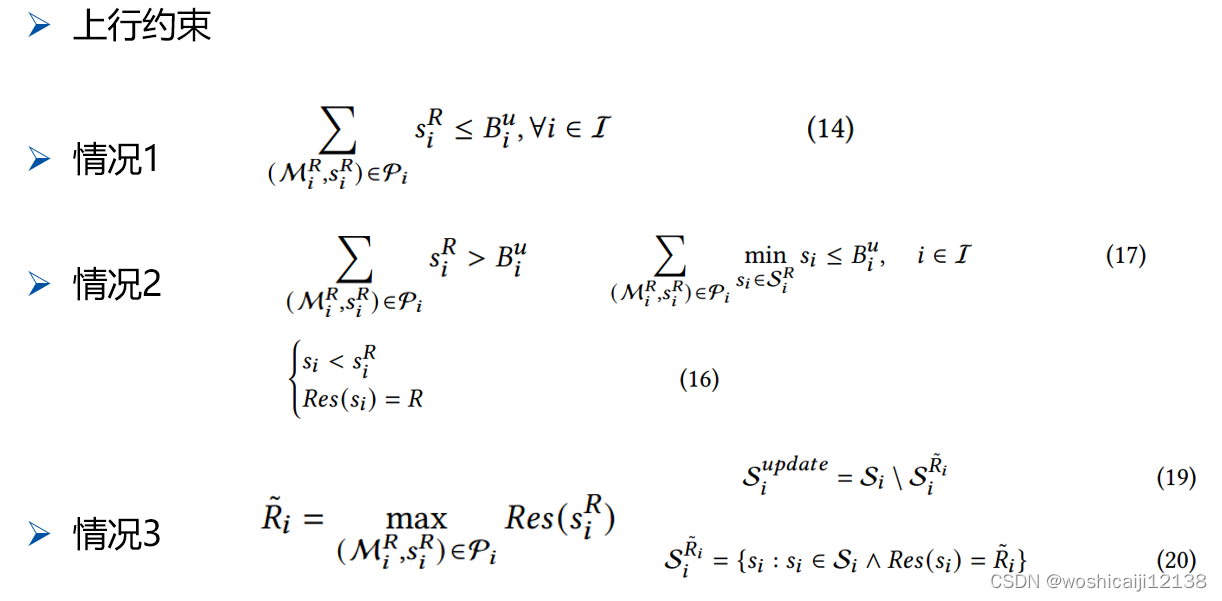
5.3 获取全局状况
订阅信息:参与者通过信令通道将其订阅意图传递给会议节点。
编解码器能力信息
编解码能力信息是通过SDP协商过程收集的;
会议节点收集视频编解码器类型和支持的流数量、流分辨率和每种分辨率下的最大比特率
在协商中我们为每个流解析分配一个不同的同步源(SSRC),以促进反馈控制。
带宽信息
在GSO中依赖于发送端带宽估计,它比接收端估计提供更好的精度
下行网络带宽直接从接入节点上报给会议节点
上行带宽在客户端测量的,每个客户端在RTCP数据包中报告带宽信息
带宽根据[27](RTCP message for Receiver Estimated Maximum Bitrate)
5.4 反馈控制
GSO-Simulcast的控制器找到了一个新的解决方案,就会发送控制反馈来为每个发送参与者配置流
控制反馈采用临时最大媒体流比特率请求(TMMBR)消息格式
如果为了不同的目的重用TMMBR,就会产生潜在的歧义。为了消除这种歧义,我们在应用程序定义的类型为204的RTCP数据包中发送TMMBR以进行流编排
因为我们将不同的SSRC分配给不同分辨率的流,所以TMMBR消息中的SSRC字段允许我们指定要配置哪个流
在接收到TMMBR后,发送方会发出相应的临时最大媒体流比特率通知(TMMBN)消息。如果接入节点没有收到相应的TMMBN消息,则重新发送TMMBR消息,从而触发另一个TMMBN的传输
5.5 管理流
A.流优先级
通过为来自不同参与者的流分配不同的QoE效用权重来轻松合并流优先级。例如,我们可以给主持人或演讲者的流更高的QoE权重。
B.对一个发布者的多流订阅
有时接收参与者需要订阅来自发送参与者的多个流。
将一个虚拟发布者X '添加到发布者集合中,通过将X和X '视为不同的发布者,使用相同的问题公式来解决下行链路约束。在Step2的开始将X '与X合并,以便我们再次将它们视为相同的发布者。
6实验结果
6.1控制算法
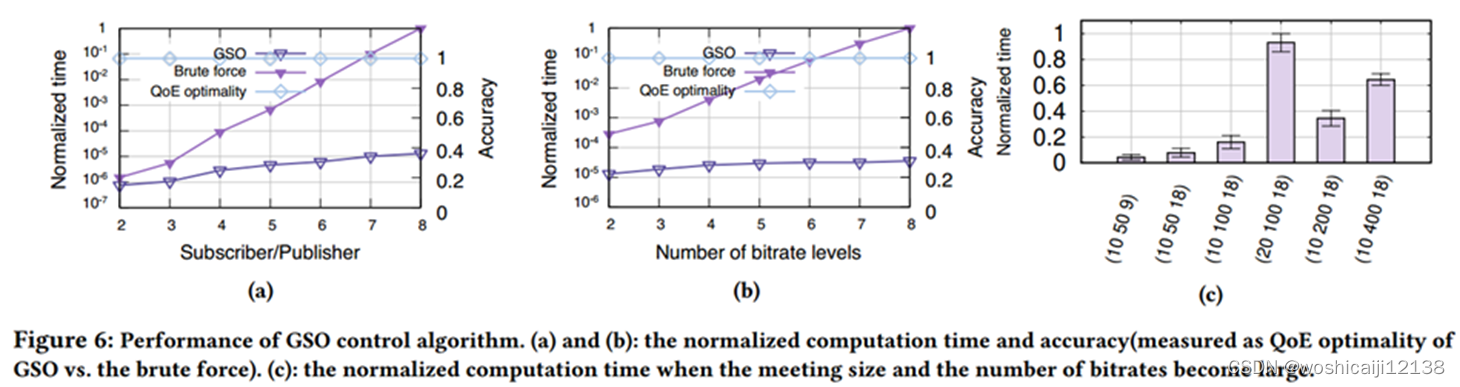
对比暴力算法
指标:计算时间和QoE optimality
QoE最优性是用GSO控制算法与暴力破解算法在Eq.(1)中QoE总和的比值来衡量的。
6.2实时瞬态响应
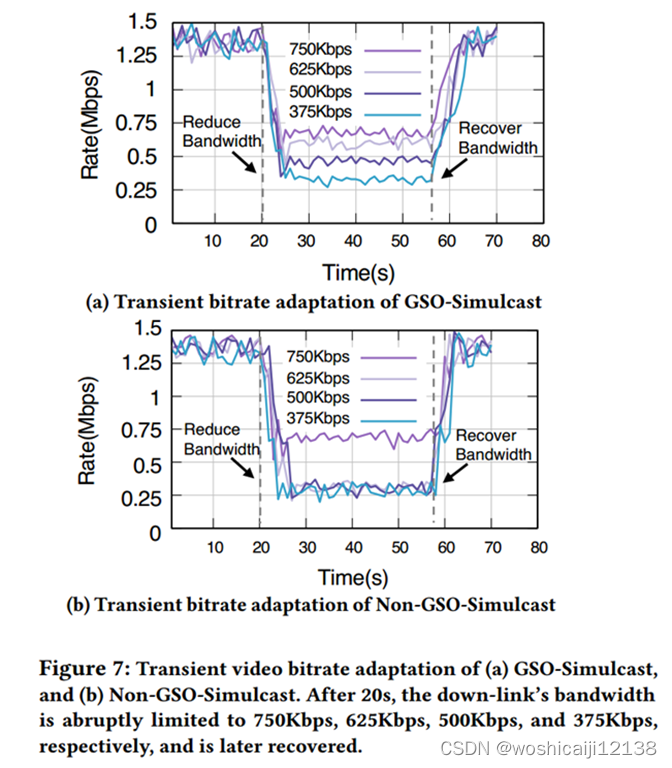
实验方法:20s之后我们将下行带宽限制分别设置为750Kbps、625Kbps、500Kbps和375Kbps,57s后带宽恢复。
GSO-Simulcast能够快速适应带宽的突然变化。
GSO-Simulcast支持的细粒度比特率的好处,在所有情况下,它都完美地符合带宽限制下的视频比特率,从而实现高带宽利用率。
6.3慢连接实验
高丢包、有限的带宽和抖动
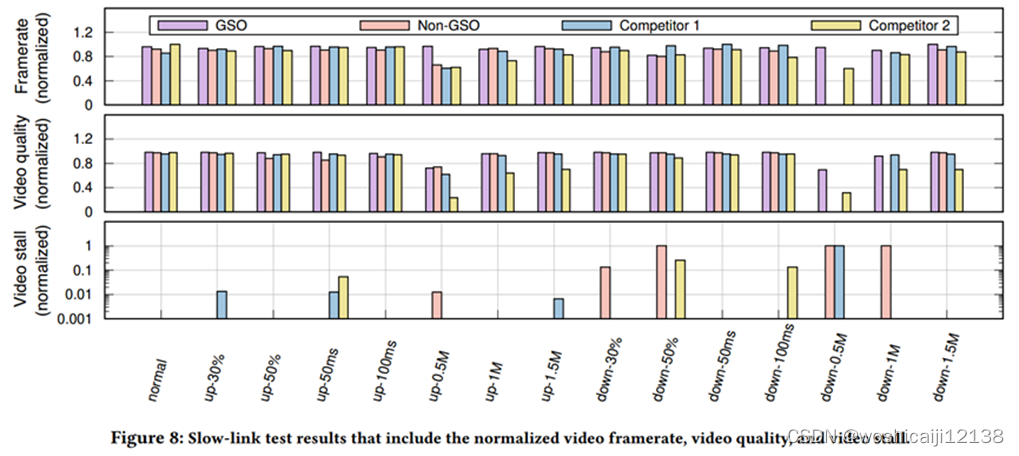
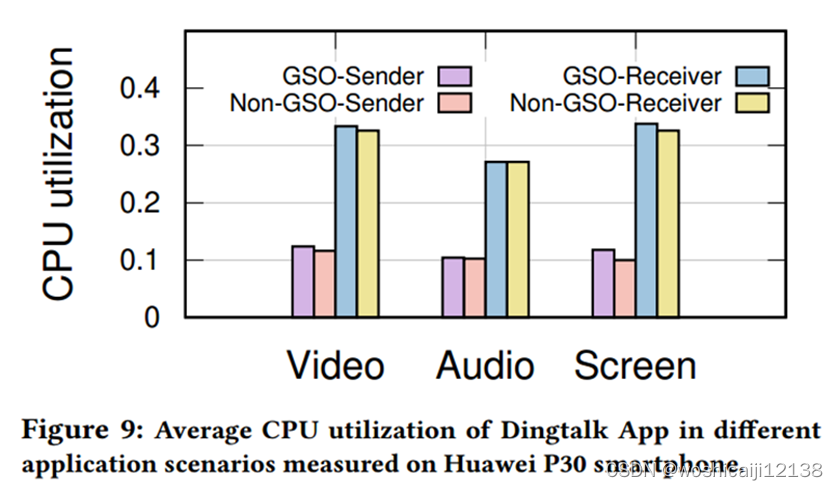
6.4客户端的CPU使用率
钉钉App在华为P30上测量的三种不同应用场景(视频会议、音频会议、屏幕共享)下(GSO版本与非GSO版本)的平均CPU利用率
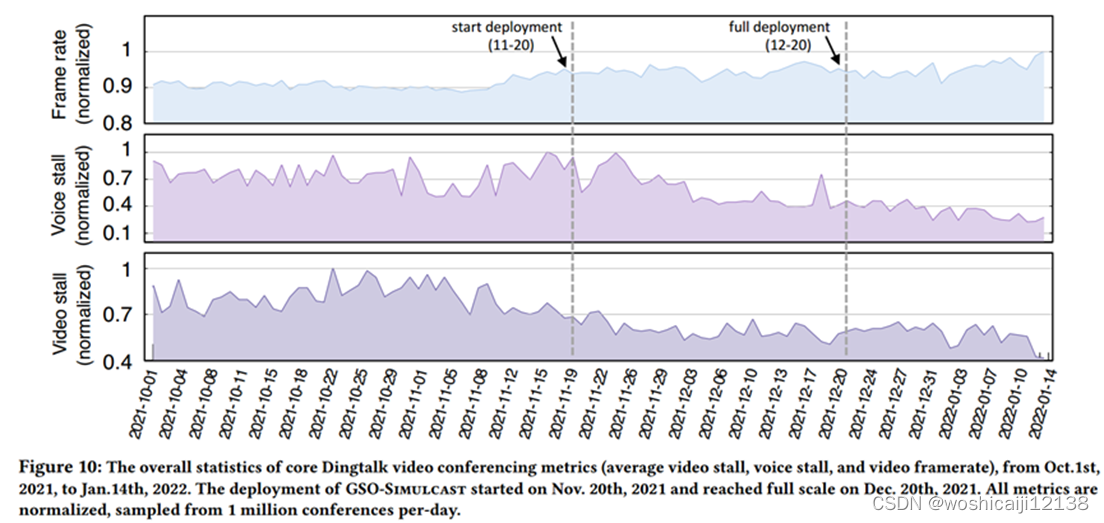
6.5部署
统计数据每天抽取100万个会议样本,总数据集超过1亿个会议样本
Video stall, voice stall, and video framerate
随着GSO-Simulcast的部署,这三个指标都得到了改善。随着部署规模的扩大,改进变得更加显著
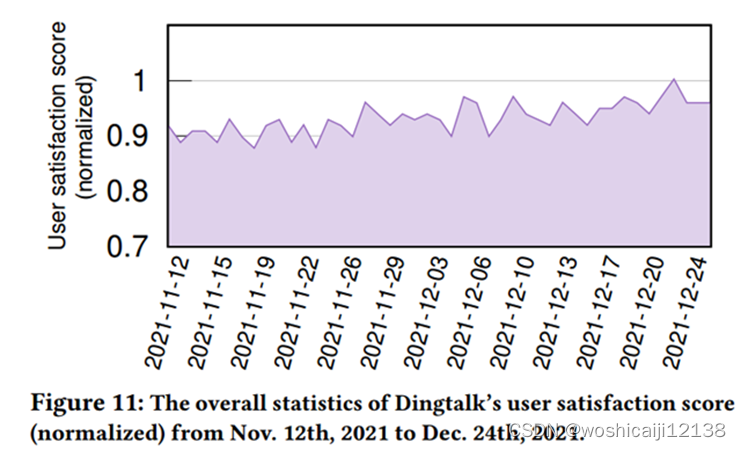
用户满意度得分(用户积极反馈的百分比)随着部署显著提高(7.2%)
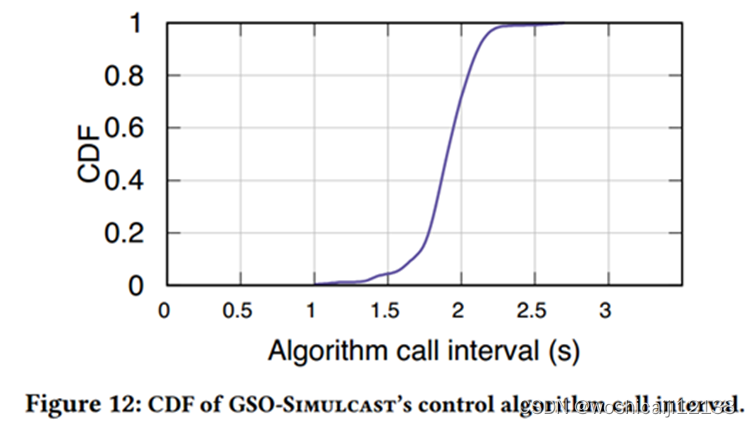
编排频率:GSO-Simulcast控制算法呼叫间隔的CDF,呼叫间隔是两个连续控制事件之间的时间间隔。平均每1.8秒编排一次流。
7部署的经验和教训
避免视频质量波动
慢速链路的带宽波动可能导致GSO-Simulcast频繁地来回调整视频比特率,从而导致视频质量振荡,只有对带宽测量有足够的信心时才升级比特率。
寻址带宽高估
类似GCC拥塞控制往往高估了一个小流的链路带宽;通过发送探测数据包,以探测带宽的上限。
减少消息报告频率
实现了一个时间触发器和一个事件触发器。时间触发器定期更新测量值,而事件触发器仅在带宽发生重大变化时才触发更新带宽。
保护音频
需要为音频信号留下足够的带宽空间。当获得带宽测量时,从中减去一个保护带宽,以进一步避免视频流占用音频流的带宽。
8评价
8.1优点
该系统成功在全球范围内广泛部署,扩展性优秀、服务易得
原理较简单,计算开销并不大
8.2缺点
缺乏对会议延迟指标的实验结果
缺乏针对特定场景的深入实验分析,例如用户处于移动状态的情况
对目标QoE建模没有介绍
这篇关于论文阅读[2022sigcomm]GSO-Simulcast Global Stream Orchestration in Simulcast Video的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







