本文主要是介绍目前开发进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我按照之前的仿真框架更新了自己的代码。重新梳理了结构,有一说一,这对一个新手来说一点也不容易,中间遇见各种的问题,所幸,花了很多的时间的终于改好了,对所有的函数基本上实现了封装。main函数变成了
#include <iostream>
#include <vector>
#include <random>
#include <chrono>#include "Neuron.h"
#include "Synapse.h"
#include "Params.h"
#include "KernelClass.h"
#include "Time.h"int main()
{KernelClass::create_kernel();// 创建种群int group1 = kernel().conn_manger.create(2);int group2 = kernel().conn_manger.create(2);//种群之间的连接kernel().conn_manger.connect(group1, group2, 1.0);int min_delay = 10;int max_delay = 10;kernel().conn_manger.set_min_delay(min_delay);kernel().conn_manger.set_max_delay(max_delay);//所有管理类的参数和变量的初始化kernel().initialize();//神经元和突触的实例化kernel().conn_manger.local_instantiate();//设置仿真的参数double dt = 0.1; //时间戳double sim_time = 300; //仿真时间(ms)int slice = static_cast<int>(sim_time / min_delay);//总共要执行循环数double current_time = 0;Time clock; //模拟时钟,每个切片更新一次int from_step = 0,to_step = kernel().conn_manger.get_min_delay();//开始仿真for (int timestep = 0; timestep < slice; timestep++){std::cout << "---------------------------------------" << std::endl;//更新神经元const std::vector< Neuron* >& local_nodes = kernel().conn_manger.get_local_nodes();for (auto node : local_nodes){(*node).update(clock, from_step, to_step);}//设置目前的时间kernel().sim_manager.set_slice_origin(clock);// 传递脉冲kernel().event_manager.gather_spike_data();//管理时间clock.advance_time(min_delay);//更新双缓冲kernel().event_manager.update_moduli();}KernelClass::delete_kernel();
}执行结果
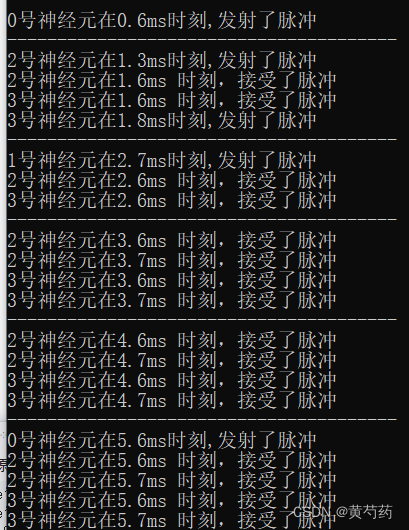
基本上没有什么大问题了,但是很多缺点,比如不能指定神经元的参数,突触的参数等,还有那个最大和最小延迟的问题。不过我最不满意的还是时间类的设计,我原本是打算写成类似于现实时间的那种机制,但是想了很久,没想到如何实现,如果有大佬会,请教教我。
说完了缺点,来说一下下一步准备干什么,下一步准备写MPI方面的代码了,MPI的管理类我也实现了,我一直在思考一个问题,我怎么判断我是否开启了MPI呢,其实也不是什么大问题,我把这个版本的保存一下,以后的设计都向mpi上边考虑,感觉这是一种比较稳妥的办法,所以先完成mpi的初始工作,包括对神经元的循环分配等。
这篇关于目前开发进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









