本文主要是介绍盲猜等下会考一致性哈希算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一致性哈希算法(Consistent Hashing)在分布式系统的应用
- 现在数据 很多都上 缓存
- 但是一台缓存 服务器肯定 不够
- 东西多了 总是要上 集群
- 通过 哈希%服务器个数 可以 分配一台机器存储
- 但是 服务器宕机了 数量变了 所有的数据都要重新 哈希
- 通过 一致性哈希算法 可以解决这个问题
一致性哈希的思想
- 使用哈希空间组成一个圆环,所有节点 分在环上,数据哈希后打到环上,通过这个环 往下找 找到的第一个节点 就是缓存的服务器。
- 容错性: 这样断掉了一个节点 只需要 迁移到前一个节点就行
- 扩展性: 加入新机器 只需要放到 哈希环上 就行
- 虚拟节点: 一台机器 占一个节点,可能分配的 范围过大 或 过小,但是把一台缓存节点 虚拟成 许多 节点,打撒了 分排在 哈希环上 就会 做到更均匀的分部。
字节跳动2018校招后端方向(第二批)笔试设计题
【设计题】今日头条会根据用户的浏览行为、内容偏好等信息,为每个用户抽象出一个标签化的用户画像,用于内容推荐。用户画像的存储、高并发访问,是推荐系统的重要环节之一。现在请你给出一个用户画像存储、访问方案,设计的时候请考虑一下几个方面:
用户画像如何存储
如何保证在线高并发、低延迟地访问
机器宕机、负载均衡问题
如果用户增长很快,在你的方案下,该如何做扩容
将存储用户画像的数据经过哈希函数运算后得到一个key值,然后用key%服务器机器数,得到的就是该用户画像数据归属的服务器,对该数据增添,查询删除都在此机器上进行。
但此设计会有一个问题,就是在对机器进行扩容或删减时,要对每一个数据重新获取哈希值,然后再对新的机器数进行取模运算,这样会造成大规模的数据迁移。
一致性哈希则可以解决这种问题。将数据经过哈希函数计算后得到的输出域想象成一个首尾相接的环形,将机器的数据经过哈希函数计算对应在环上,每一个数据经过哈希函数计算后也都会在环上有对应的位置。
此时每个数据对应的机器就是从此处顺时针向前找,最近的机器就是该数据的归属。当对机器进行增加时,只需将逆时针距离新加服务器最近的机器到此机器之间的数据进行迁移,删除机器时同理。
此时还会有负载不均衡的问题:若机器数太少,就会在环上分布不均匀,此时会造成机器负载不均衡的问题,可以引入虚拟节点技术解决,即同一机器经过不同的哈希函数计算出多个哈希值分布在环上,节点数变多了。平衡性自然会好。
找了一篇文章 摘录一部分
- 字节跳动2018校招后端方向(第二批)笔试设计题
- 3 容错性和扩展性
- 3.1 容错性
- 3.2 扩展性
- 4 虚拟节点
- 总结
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
一致性哈希是将整个哈希值空间组织成一个虚拟的圆环,如假设哈希函数H的值空间为0-2^32-1(哈希值是32位无符号整形)
整个空间按顺时针方向组织,0和2^32-1在零点中方向重合。
接下来,把服务器按照IP或主机名作为关键字进行哈希,这样就能确定其在哈希环的位置。
然后,我们就可以使用哈希函数H计算值为key的数据在哈希环的具体位置h,根据h确定在环中的具体位置,从此位置沿顺时针滚动,遇到的第一台服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:
根据一致性哈希算法,数据A会被定为到Server 1上,数据B被定为到Server 2上,而C、D被定为到Server 3上。
3 容错性和扩展性
那么使用一致性哈希算法的容错性和扩展性如何呢?
3.1 容错性
假如RedisService2宕机了,那么会怎样呢?
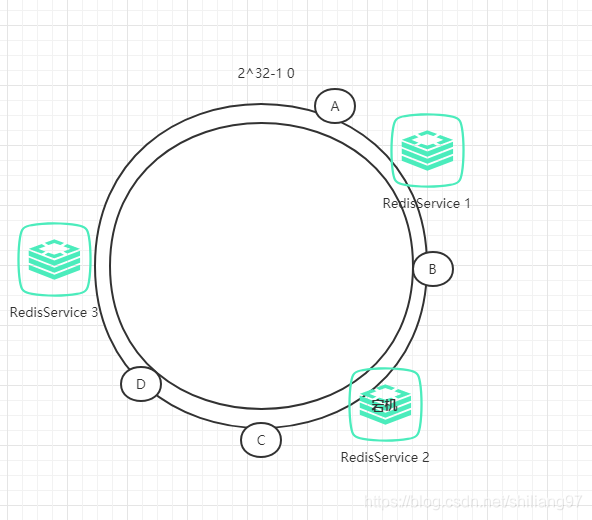
那么,数据B对应的节点保存到RedisService3中。因此,其中一台宕机后,干扰的只有前面的数据(原数据被保存到顺时针的下一个服务器),而不会干扰到其他的数据。
3.2 扩展性
下面考虑另一种情况,假如增加一台服务器Redis4,具体位置如下图所示:
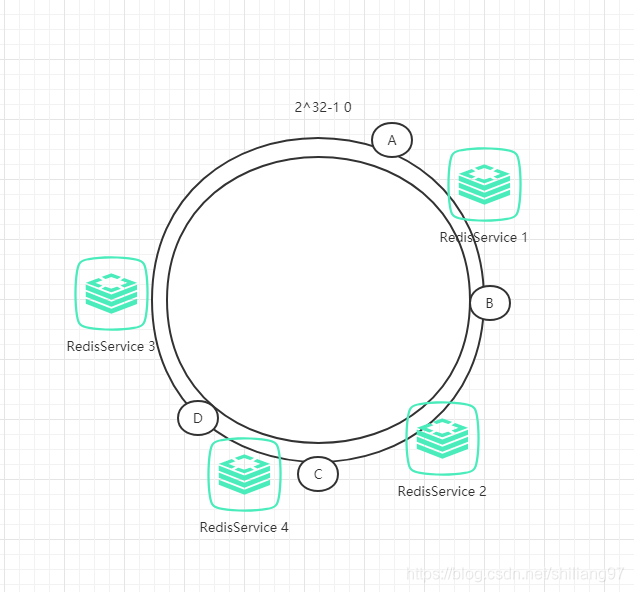
原本数据C是保存到Redis3中,但由于增加了Redis4,数据C被保存到Redis4中。干扰的也只有Redis3而已,其他数据不会受到影响。
因此,一致性哈希算法对于节点的增减都只需重定位换空间的一小部分即可,具有较好的容错性和可扩展性
4 虚拟节点
前面部分都是讲述到Redis节点较多和节点分布较为均衡的情况,如果节点较少就会出现节点分布不均衡造成数据倾斜问题。
例如,我们的的系统有两台Redis,分布的环位置如下图所示:
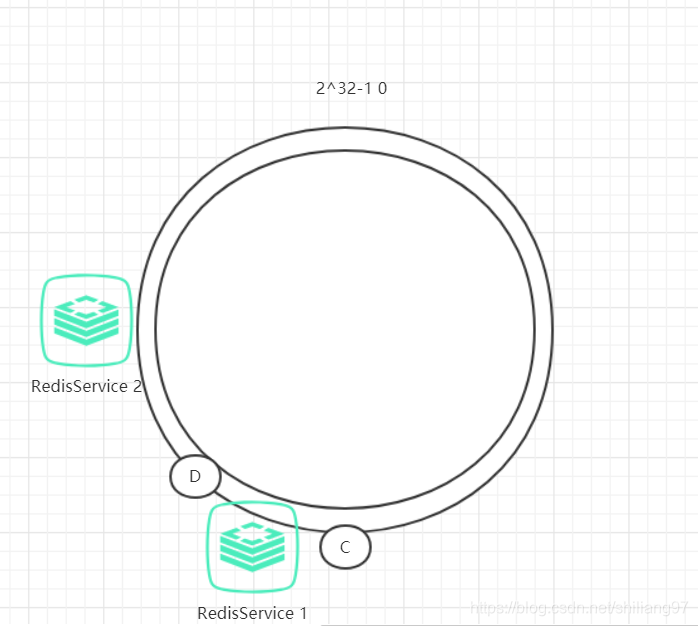
这会产生一种情况,Redis1的hash范围比Redis2的hash范围大,导致数据大部分都存储在Redis1中,数据存储不平衡。
为了解决这种数据存储不平衡的问题,一致性哈希算法引入了虚拟节点机制,即对每个节点计算多个哈希值,每个计算结果位置都放置在对应节点中,这些节点称为虚拟节点。
具体做法可以在服务器IP或主机名的后面增加编号来实现,例如上面的情况,可以为每个服务节点增加三个虚拟节点,于是可以分为 RedisService1#1、 RedisService1#2、 RedisService1#3、 RedisService2#1、 RedisService2#2、 RedisService2#3,具体位置如下图所示:
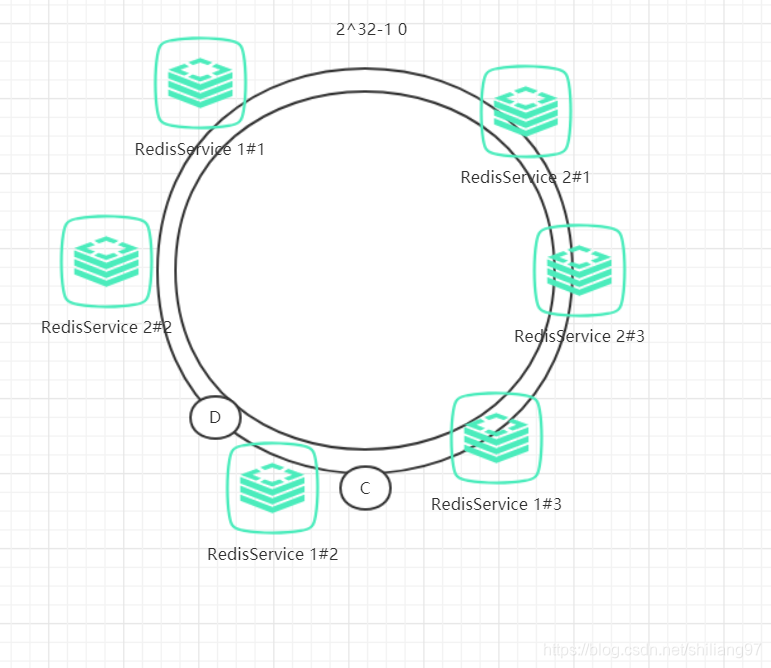
对于数据定位的hash算法仍然不变,只是增加了虚拟节点到实际节点的映射。例如,数据C保存到虚拟节点Redis1#2,实际上数据保存到Redis1中。这样,就能解决服务节点少时数据不平均的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
总结
本文简要的介绍了一致性哈希算法,目前一致性哈希算法基本成为了分布式系统组件的标准配置,因此,我们十分有必要了解该算法。
作者:广州芦苇科技Java开发团 链接:https://juejin.cn/post/6844903750860013576 来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这篇关于盲猜等下会考一致性哈希算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









