本文主要是介绍xxl-job(分布式调度任务),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
针对分布式任务调度的需求,市场上出现了很多的产品:
1)TBSchedule:淘宝推出的一款非常优秀的高性能分布式调度框架,目前被应用于阿里,京东,支付宝,国美等很多互联网企业的流程调度系统中。但是已经多年未更新,文档缺失严重,缺少维护。
2)xxl-job:大众点评的分布式任务调度平台,是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
3) Elastic-job:当当网借鉴TBSchedule并基于quartz二次开发的弹性分布式任务调度系统,功能丰富强大,采用zookeeper实现分布式协调,具有任务高可用以及分片功能。
4)Saturn:唯品会开源的一个分布式任务调度平台,基于Elastic-job,可以全域统一监控,具有任务高可用以及分片功能。
xxl-job是一个分布式任务调度平台,其核心设计目标是开发迅速,学习简单,轻最级,易扩展。现已开放源代码,并接入多家公司线上产品线,开箱即用。
源码地址
文档地址
特性
- 简单灵活
提供web页面对任务进行管理,管理系统支持用户管理,权限控制;
支持容器部署;
支持通过通用http提供跨平台任务调度; - 丰富的任务管理功能
支持页面对任务crud操作;
支持在页面编写脚本任务,命令行任务,java代码任务并执行;
支持任务级联编排,父任务执行结束后触发子任务执行;
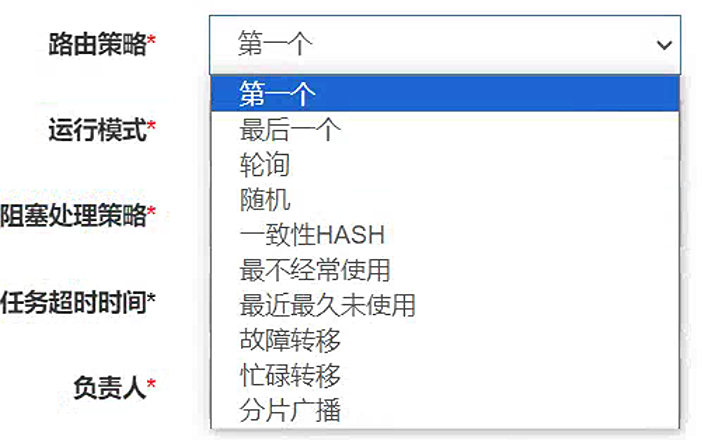
支持设置指定任务执行节点路由策略,包括轮询,随机,广播,故障转移,忙碌转移等;
支持cron方式,任务依赖,调度中心api接口方式触发任务执行 - 高性能
任务调度流程全异步化设计实现,如异步调度,异步运行,异步回调等,有效对密集调度进行流行削峰; - 高可用
任务调度中心,任务执行节点均集群部署,支持动态扩展,故障转移
支持任务配置路由故障转移策略,执行器节点不可用是自动转移到其他节点执行
支持任务超时控制,失败重试配置
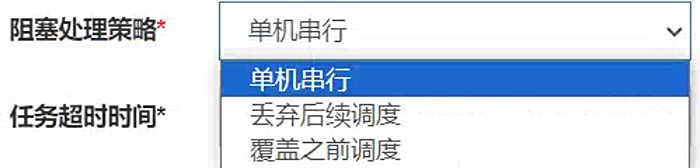
支持任务处理阻塞策路:调度当任务执行节点忙碌时来不及执行任务的处理策略,包括:串行,抛弃,覆盖策略 - 易于监控运维
支持设置任务失败邮件告警,预留接口支持短信,钉钉告警;
支持实时查看任务执行运行数据统计图表,任务进度监控数据,任务完整执行日志;
快速入门
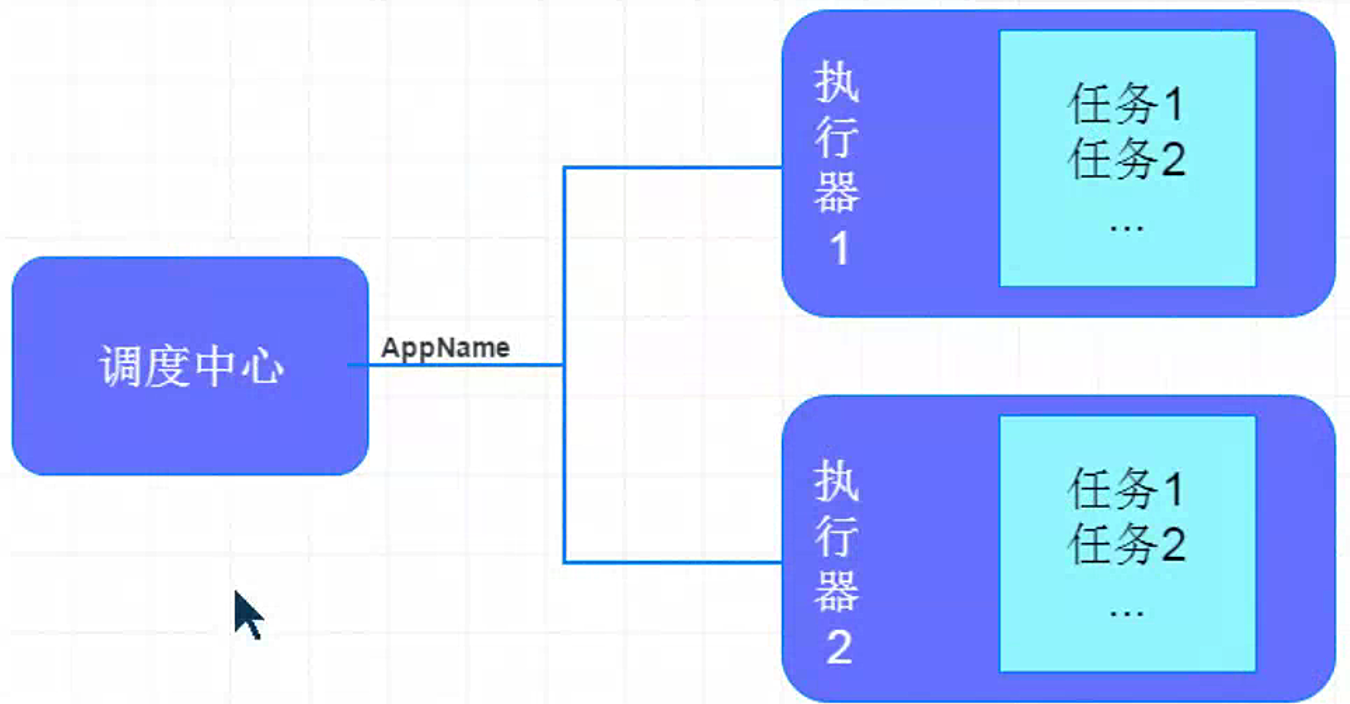
- 调度中心:负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。
- 任务执行器:负责接收调度请求并执行任务逻辑
- 任务:专注于任务的处理。
- 调度中心会发出调度请求,任务执行副接收到请求之后会去执行任务,任务则专注于任务业务的处理。
环境搭建
调度中心环境要求
- Maven 3+
- jdk1.8+
- MySQL 5.7+
源码仓库地址
- GitHub - xuxueli/xxl-job: A distributed task scheduling framework.(分布式任务调度平台XXL-JOB)
- 许雪里/xxl-job
初始化调度数据库
执行这个sql文件

建完后的表:
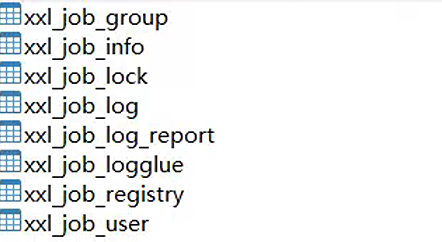
表解释:
- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表:用于保存xxl-job调度任务的扩展信息,如任务分组,任务名,
- 器地址,执行器,执行入参和报警邮件等等;
- xxl_job_log:调度日志表:用于保存xxl-job任务调度的历史信息,如调度结果,调度机器和执行器等等;
- xxl-job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
调度中心支持集群部署,集群情况下各节点务必连接同一个mysdl实例;
如果mysql做主从,调度中心集群节点务必强制走主库;
编译源码
解压源码,按照Maven格式导入IDE,使用Maven编译即可。

修改配置为自己的:admin项目application.properties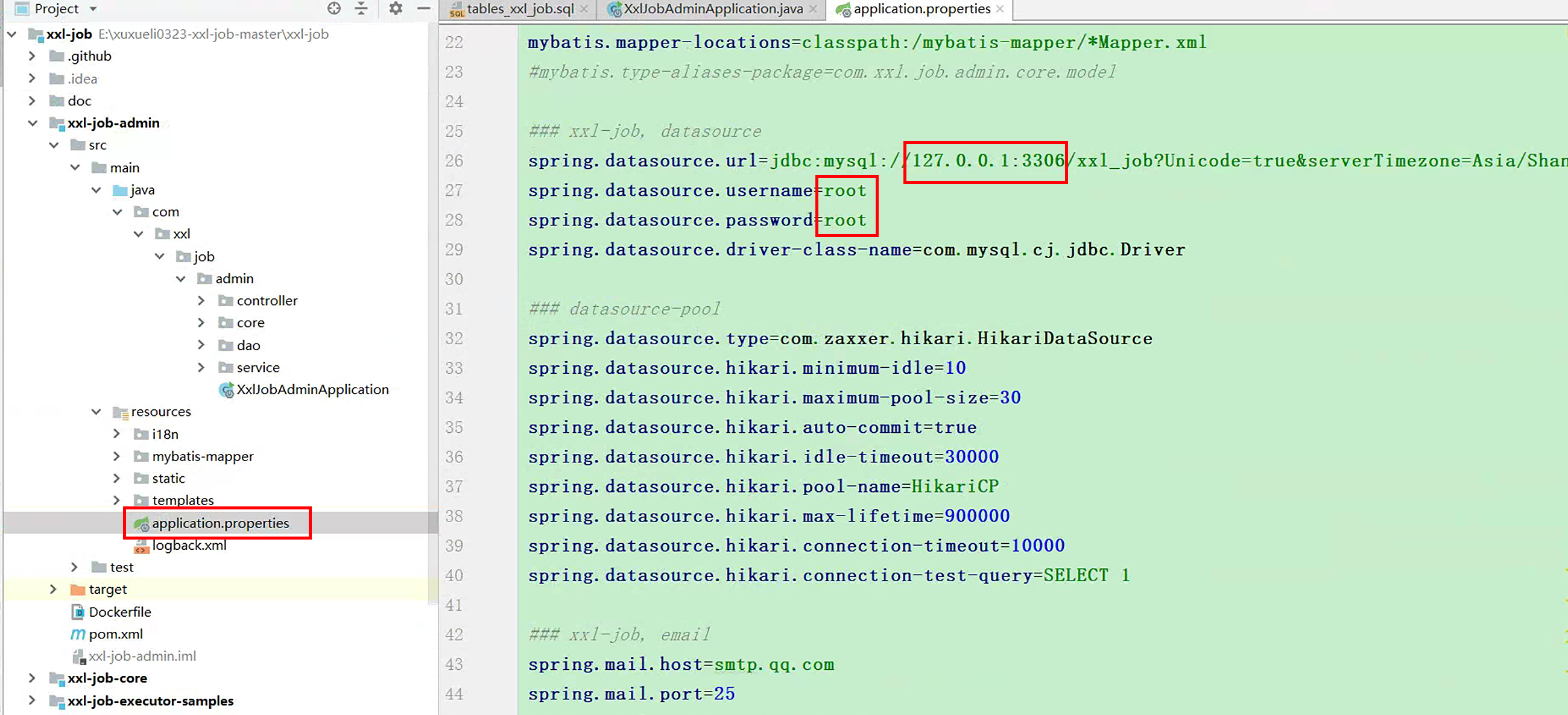
启动admin项目,如果出现报错,则解决对应的报错即可。
登录xxl-job 的admin控制台
默认账密:
账号:admin
密码:123456
进入首页
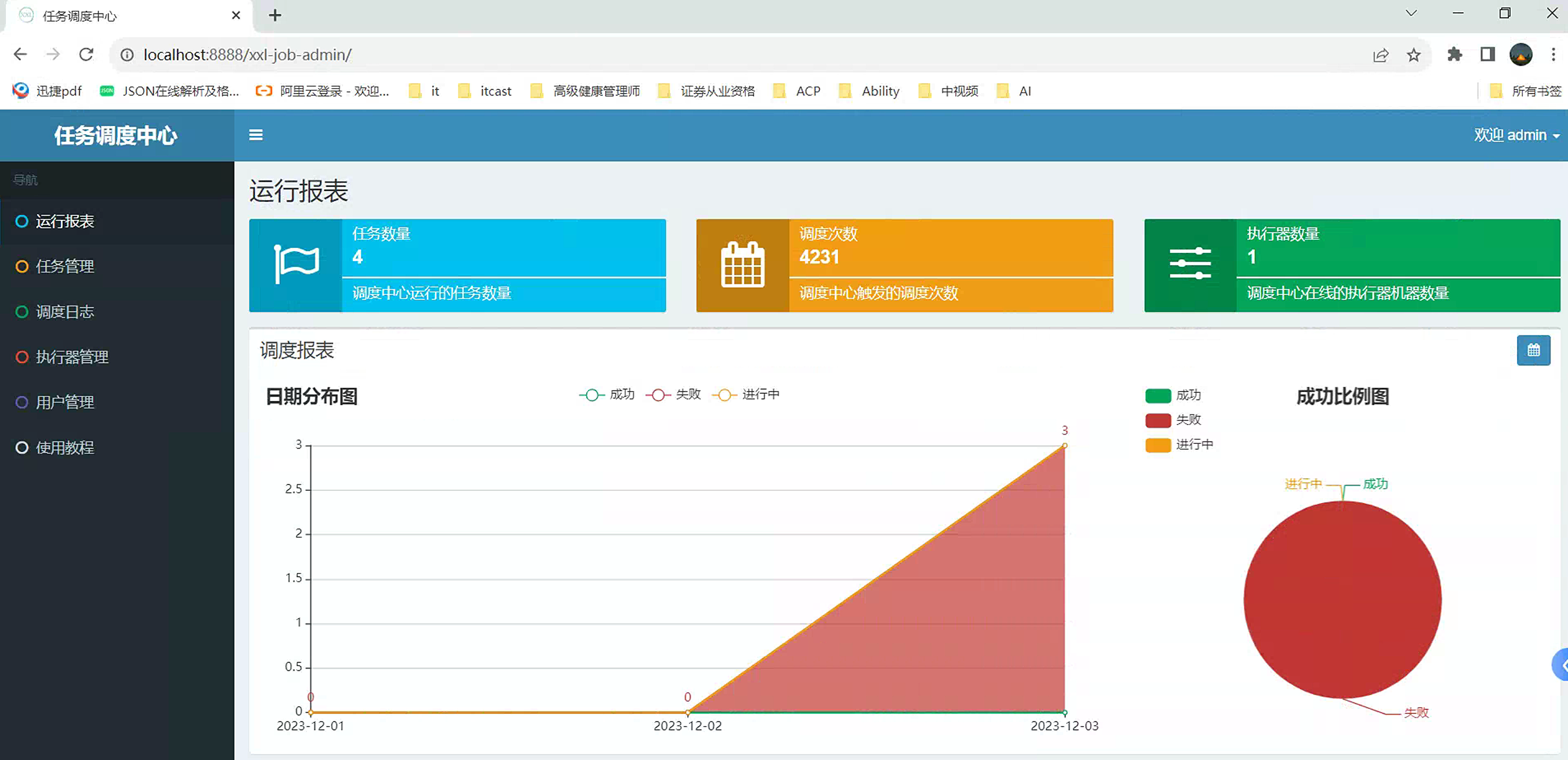
也可以使用package去打包为jar包,然后通过java -jar xxl-job-admin.jar的方式去启动
创建执行器和任务
执行器中可以有具体的任务去执行。
执行器负责接收调度中心的调度并去执行里面的任务。
创建执行器
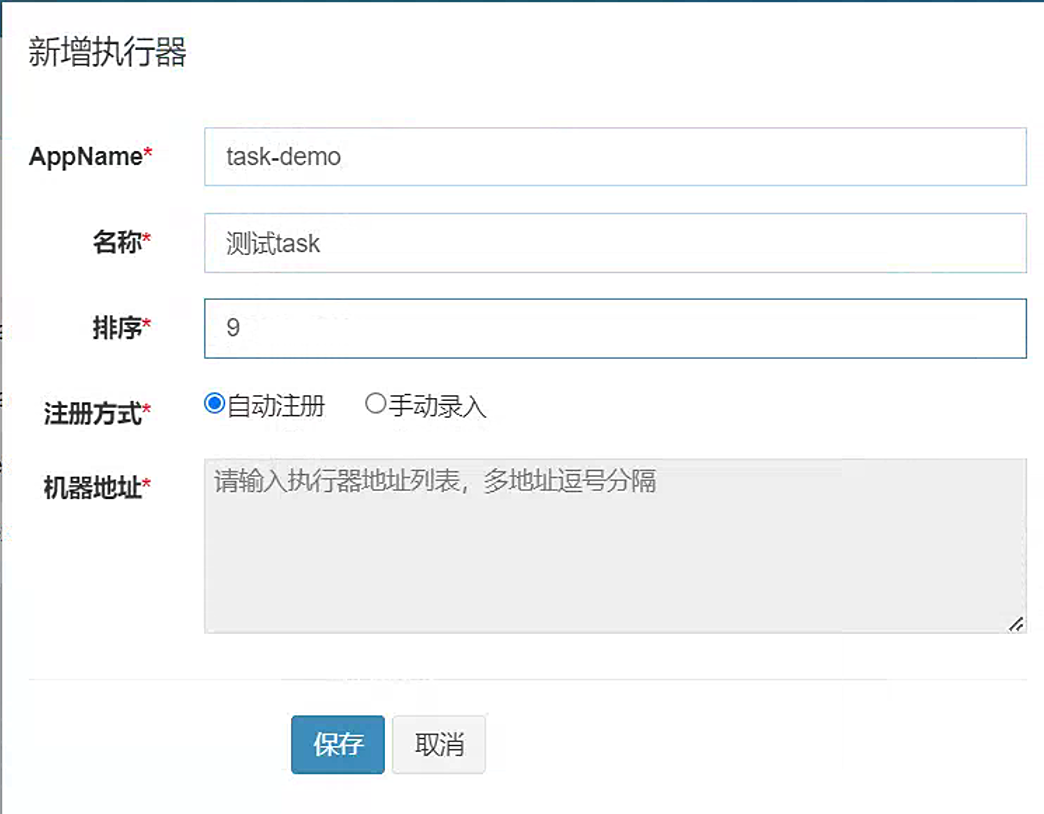
自动注册:调度中心会通过底层注册表去自动发现机器的地址。
创建执行器后,要在当前执行下指定具体的任务。
新增任务
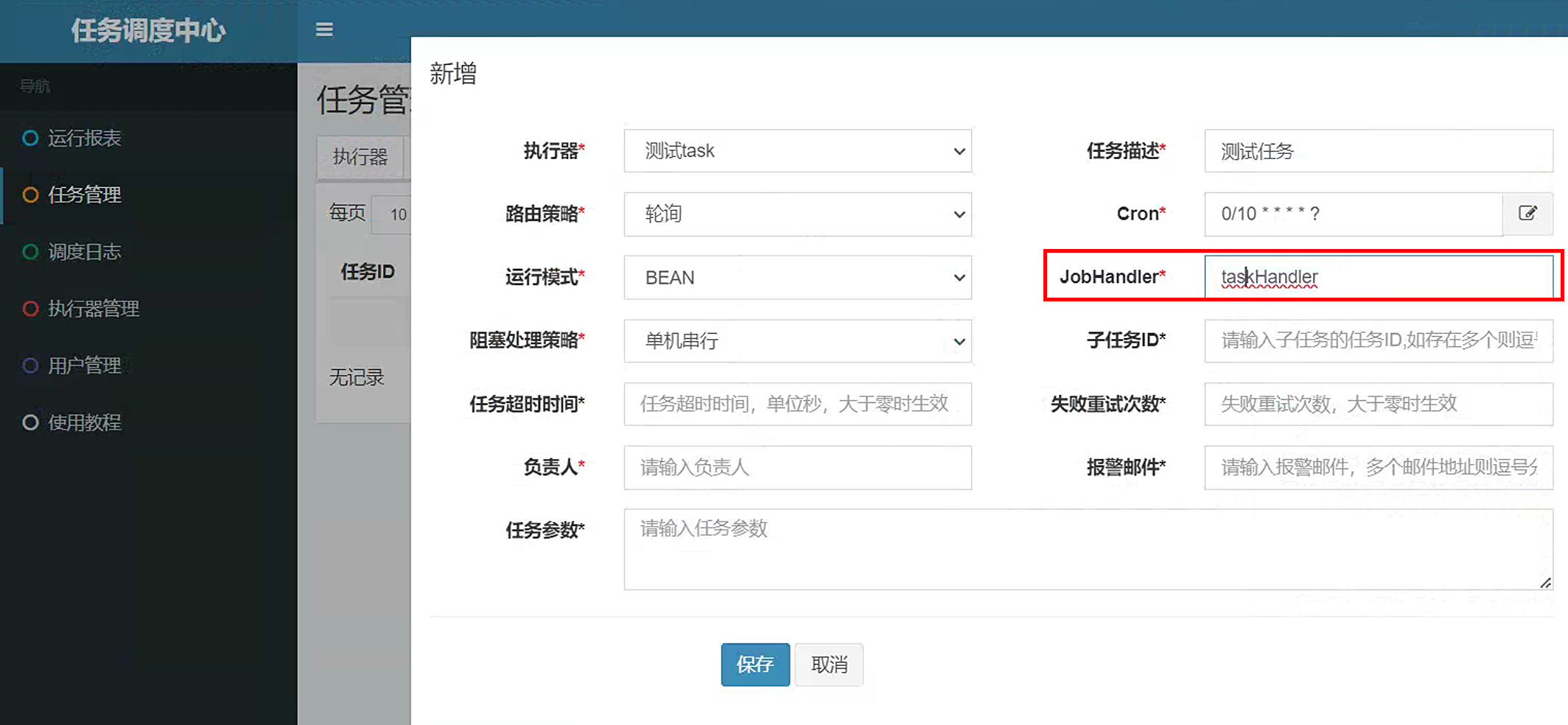
路由策略:
阻塞处理策略:调度过于密集,执行器没资源去处理当下的请求,咋整?
JobHandler:用来关联后台的java代码
SpringBoot集成
可以直接使用这个项目,也可以自己单独创建一个SpringBoot项目。

先安装到本地,后续要依赖这个包
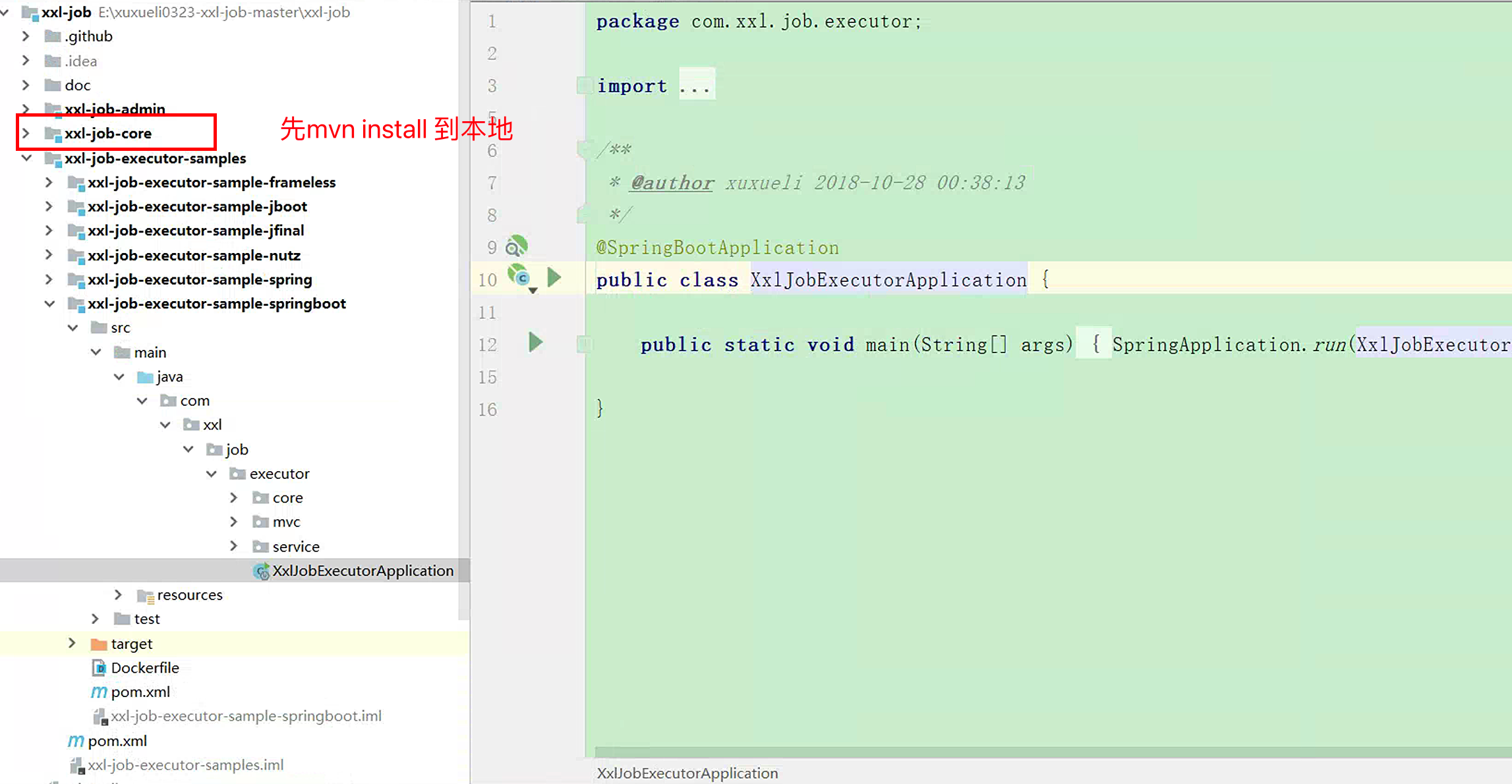
新建一个SpringBoot项目:xxl-job-core的版本可以看示例代码中的core版本
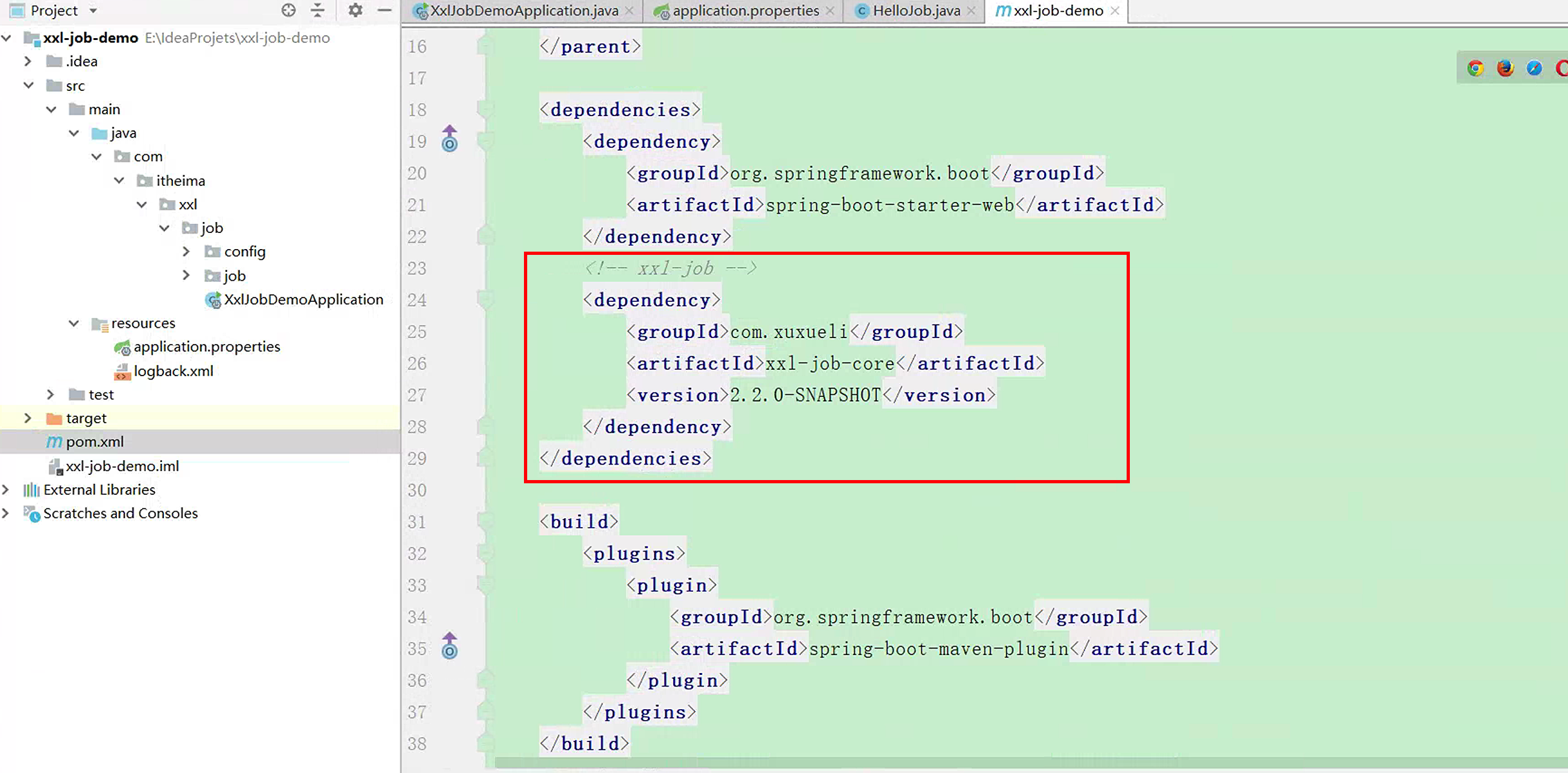
application的配置文件可以直接参考
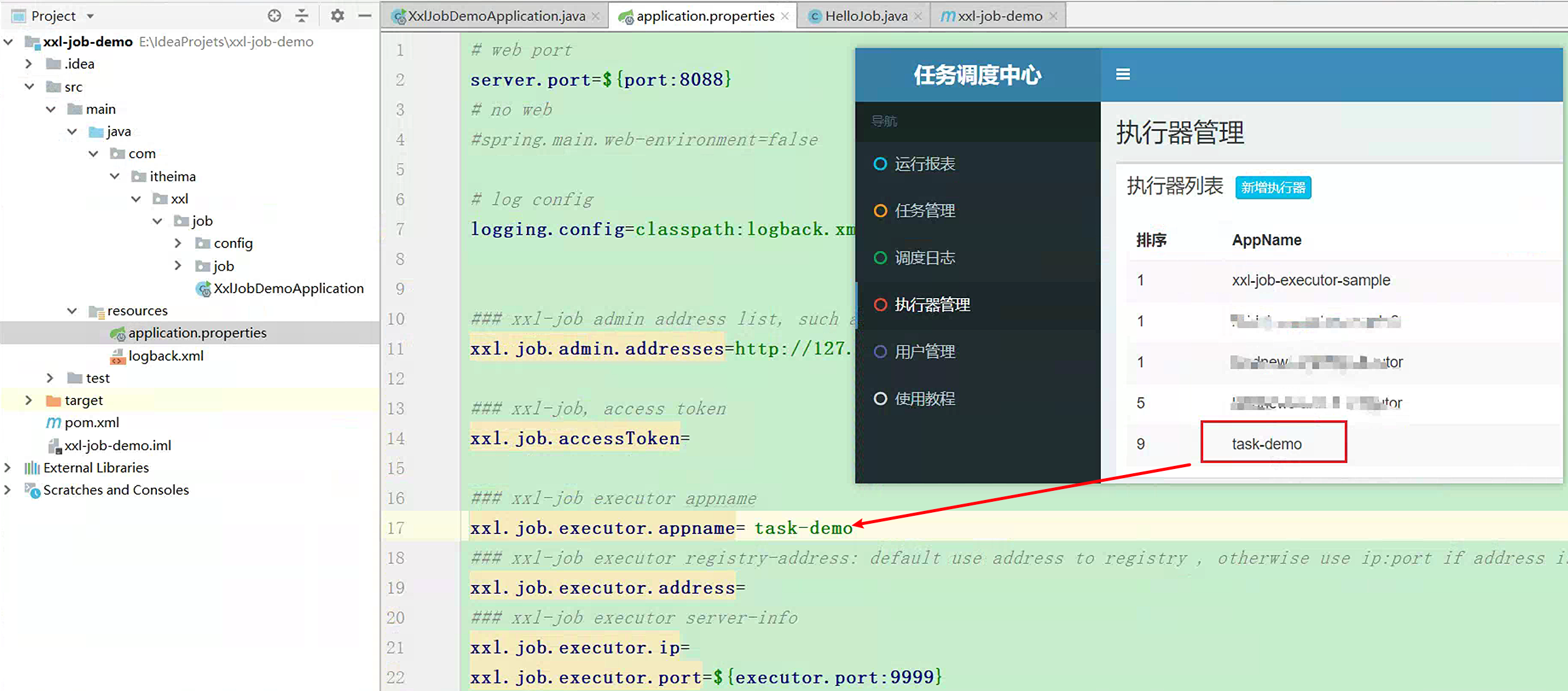
执行器名称需要修改为之前我们自己创建的执行器
port在集群模式下需要注意,不要重复。
核心配置:
可以参考,xxl-job的代码示例:
package com.itheima.xxl.job.config;import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** xxl-job config** @author xuxueli 2017-04-28*/
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appName;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppName(appName);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}/*** 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;** 1、引入依赖:* <dependency>* <groupId>org.springframework.cloud</groupId>* <artifactId>spring-cloud-commons</artifactId>* <version>${version}</version>* </dependency>** 2、配置文件,或者容器启动变量* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'** 3、获取IP* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();*/}
JobHandler中的名称写到XxlJob中注解的value位置,否则找不到这个任务。

application配置文件
# web port
server.port=8088
# no web
#spring.main.web-environment=false# log config
logging.config=classpath:logback.xml### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8888/xxl-job-admin### xxl-job, access token
xxl.job.accessToken=### xxl-job executor appname
xxl.job.executor.appname= task-demo
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port= 9999
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30
这篇关于xxl-job(分布式调度任务)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







