本文主要是介绍【论文 | 联邦学习】 | Towards Personalized Federated Learning 走向个性化的联邦学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Towards Personalized Federated Learning
标题:Towards Personalized Federated Learning
收录于:IEEE Transactions on Neural Networks and Learning Systems (Mar 28, 2022)
作者单位:NTU,Alibaba Group,SDU,HKUST,WeBank
链接:https://arxiv.org/pdf/2103.00710.pdf
简述:
本文提供了一个FL的概述,并讨论了PFL的关键动机。
提出了一种独特的PFL技术分类法,根据PFL中的关键挑战和个性化策略进行分类,并强调了这些PFL方法的关键想法、挑战和机遇。
最后,讨论了PFL文献中普遍采用的公共数据集和评价指标,并概述了将启发PFL进一步研究的开放问题和方向。
1. 背景
我们在进入个性化联邦学习(Personalized Federated Learning, PFL)的介绍之前,我们首先抛弃“个性化”这个关键词,回顾联邦学习(Federated Learning, FL):
什么是联邦学习?为什么要做联邦学习?
1.1. 联邦学习的背景
在有监督学习中,模型的泛化能力依赖于标注数据的规模。
虽然我们的世界每天有海量的数据被创造出来,但是他们有这样的特点:
- 分布的:数据是分散在不同的终端或者数据中心。
- 打个比方,今天你和你的好友小Y捡到一包辣条,为了庆祝,你们分别用自己的手机和这包辣条进行了合照,这些照片被分布地储藏在你和小Y的手机中,而不是集中的出现在某一人的手机中。在这个场景下手机就是构成了终端,同时同时也可以把每一台手机当成一个数据中心。
- 隐私的:因为隐私性,端和端(或者数据中心)之间的数据共享变得困难。
- 同时,法律法规对于数据隐私性的限制也在日益完善,诸如欧盟出台的《General Data Protection Regulation》等。
- 特别的数据隐私性在医疗场景下收到了诸多关注。还是以上面的例子,或许你也不希望你和辣条的合照出现在第三方平台被用于训练AI模型。
- 高昂的数据传输成本:海量数据的传输成本是高昂的。
为什么我们不用隐私的数据在每个数据中单独训练一个模型?
因为一个数据中心的数据规模太小,不足以训练出一个鲁棒的模型。
把数据收集到同一个数据中心或者云端,虽然可以增大训练数据集的规模,但是数据隐私性和通讯成本的问题没有被解决。
如下图所示:中心化的训练:分布的数据被上传至云端,共同训练一个模型
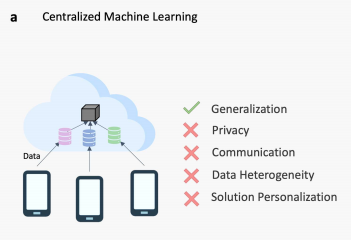
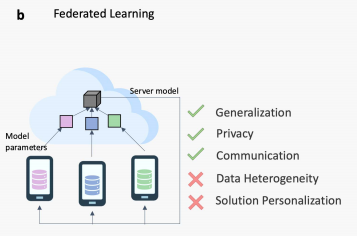
联邦学习在这个场景下,应运而生。经典的FedAvg首次由Google在2017年提出。
核心思路就是:隐私的数据不上传至云端,将模型下载到每个数据中心训练后上传到云端进行aggregate,重复上述步骤直到模型收敛。
保护了分布数据数据隐私性;同时避免了数据的传输,转而使用相对规模更小的模型的传输,节约了计算的通讯开销。
这里对于联邦学习其介绍的目的,可以参考这篇文章: King James:通俗易懂讲解联邦学习
1.2. 联邦学习的缺陷
联邦学习的成功依赖于一个重要的假设:每个数据中心的数据是独立同分布(IID)。
还是你和小Y,如果你们分别对于卫L品牌和W龙品牌的辣条随机的进行拍照,产生的照片就不是IID的,因为他们所属的数据分布不同(一个是卫L牌,一个是W龙牌)。实验表明在non-IID的数据上,联邦学习模型的表现非常差[1]。
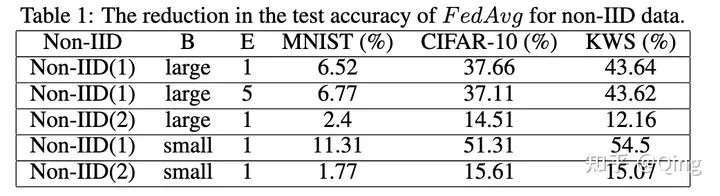
理想(数据的IID)是美好的,但是现实是骨感的。
实际场景中,数据通常以 non—IID 形式呈现的,包括如下形式[2]:
- 特征分布偏斜(feature distribution skew,covariate shift):你和小Y拍的是不同品牌的辣条。
- 标签分布偏斜(label distribution skew,prior probability shift):你拍的是辣条,小Y拍的是辣子鸡。
- 相同标签,不同特征(Same label but different features,concept shift):你和小Y拍虽然拍的是同一个品牌的辣条,但是用的滤镜不一样。
- 相同特征,不同标签(Same features but different label,concept shift)
- 数量不均,分布不平衡:你每拍100张辣条拍1张辣子鸡;小Y每拍1张辣条就拍100张辣子鸡。
我们把这些统称为数据的异质性(heterogeneity)。
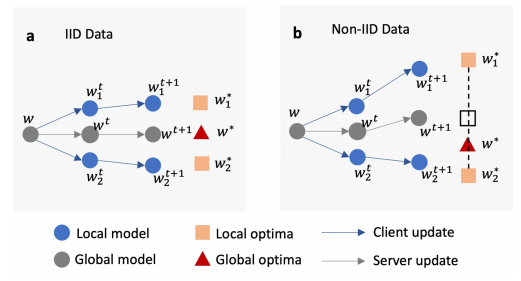
在Non-IID设定下,每个数据中心的优化方向不一致,这就好比是每个分力方向迥异,最终的合力就小于每个分力,文献中称之为weight divergence。
因为weight divergence模型收敛慢,并且泛化能力差。
PS:感慨一下,这也印证了俗话说的“劲往一处使”,每个client如果各自目标不一致,最终也会造成整体性能的下降。
联邦学习除了对于数据异质性表现差,也缺失了模型(对于本地任务或者数据集的)个性化。比如,通过某水果公司用过联邦学习训练了一个英语版的语音模型Siri Plus,但是其用户需要的不止是英语版,还有是中文版、法文版、韩文版等等的Siri Plus。
个性化联邦学习就是为了解决联邦学习中的:
- 在异质性强(non-IID)的数据上收敛慢,性能差。
- 模型对于本地任务或者数据集缺乏个性化。
个性化联邦学习解决了联邦学习对于non-IID性能的下降。
包含(1)全局模型个性化;(2)学习个性化模型
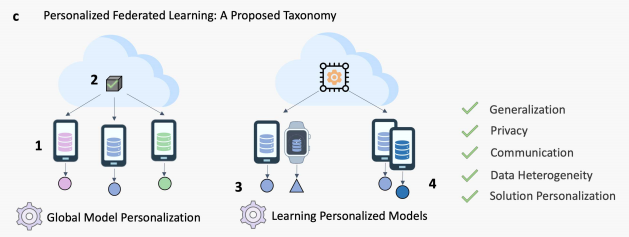
2. 个性化联邦学习分类
“Towards Personalized Federated Learning”一文将个性化联邦学习(PFL)分为两类:
- 全局模型个性化(Global Model Personalization):
- 第一阶段,训练一个共享的全局FL模型;
- 第二阶段,在本地的数据上进行额外的训练,达到适应个性化的目的。
- 在这一类模型中,关注与第一阶段全局FL模型在non-IID数据上的训练能力。
- 学习个性化模型(Learning Personalized Model):
- 在训练阶段,就达到模型个性化的效果。
- 个人理解:区别于上种二阶段的PFL,这一类方法在一阶段就实现了PFL(但这样理解的话似乎把Regularization based的方法归入architecture更合理)。
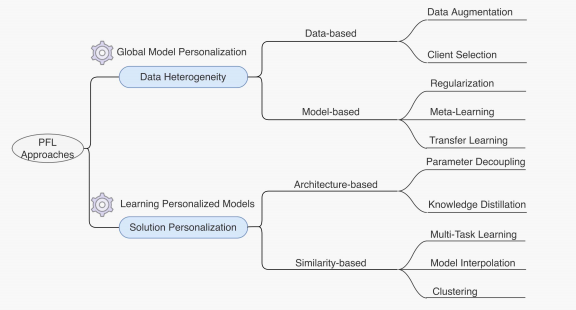
原文的分类标准是根据(i)解决数据异质性和(ii)达成模型个性化这两个需求进行划分的。但是或许这种划分并不是绝对的:Learning Personalized Models也可也解决数据异质性,反之亦然。
Survey of personalization techniques for federated learning
一文提供了另一种分类方案,也就是从使用的技术层面对个性化联邦学习进行分类。
2.1. 全局模型个性化
全局模型个性化目标是解决FL在non-IID数据上训练的难点。
包含(i)基于数据的方法和(ii)基于模型的方法。
2.1.1. 基于数据的方法
这一类方法目标是消除数据中心之间数据分布不均衡,从而将non-IID转化为IID的设定。
把未解决的问题(non—IID)reduce到已经解决的问题的设定下(IID),这样就可以通过已经有的方法(FedAvg等FL)进行处理。
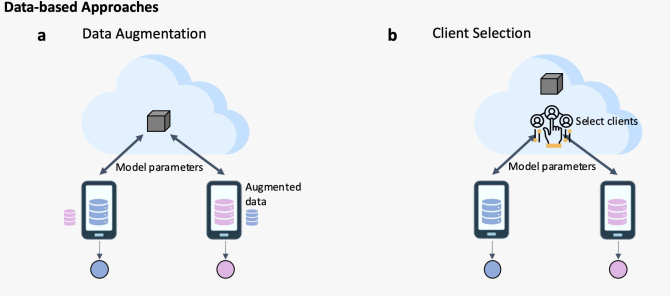
基于数据的全局模型个性化包含:(1)数据增强;(2)client选择
- 数据增强:通过在云端建立proxy dataset 或者通过每个数据中心分享数据获得对整体数据分布的估计。随后在训练共享的用于数据增强的模型(比如对抗生成网络),并下载到每个数据中心用于增强。但是这个方案可能存在数据隐私泄漏的风险。
- client(数据中心)选择:比起基于数据增强,这类方法适应与数据异质性更弱一些的设定,目标是提升全局模型的泛化能力。通过在每轮federated epoch最“合适”当前轮次的client进行模型训练。这一类研究的重点就在度量client对于训练状态的“合适”度上。
2.1.2. 基于模型的方法
基于模型的PFL方法包含三类:通过正则化,元学习(meta learning),和迁移学习(transfer learning)。
这一类方案包含两种优化目标:(i)优化全局FL用于潜在的下游个性化需求;(ii)提升从全局FL模型个性化的表现。
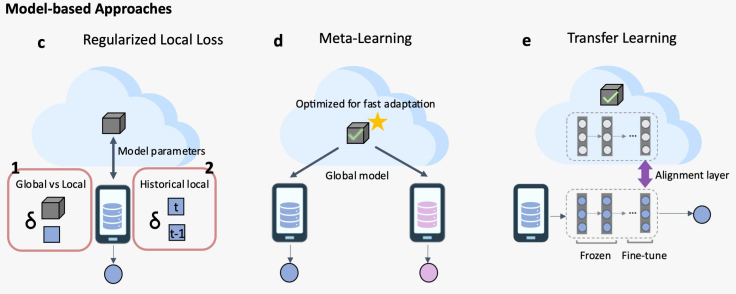
- 正则化:我是一颗小蘑菇:联邦学习个性化小小小综述 详细地介绍了基于正则化的PFL技术。在优化的全局模型的过程中,同时也训练了每个数据中心本地个性化的模型参数,并且通过正则化项将两部分参数进行关联。
- 元学习:元学习和联邦学习有非常相似的数学表述形式。将FL的训练阶段视作为元学习的训练阶段,将FL模型个性化阶段视作为元学习的测试阶段,可以很自然的将元学习模型迁移到个性化联邦学习中。
- 迁移学习:首先训练一个全局FL模型,在本地数据上训练一个本地模型,最后通过全局FL模型对于本地模型精调。其目标是降低本地模型和全局FL模型之间的不一致性。
基于全局模型个性化的各类方法的优缺点比较:

2.2. 学习个性化模型
这一类的PFL方法目标是达成个性化的下游任务。包含(i)基于结构和(ii)基于相似度的方案。
2.2.1. 基于结构的方法
这类方法通过为每个数据中心设置个性化的结构达到模型个性化的目的。
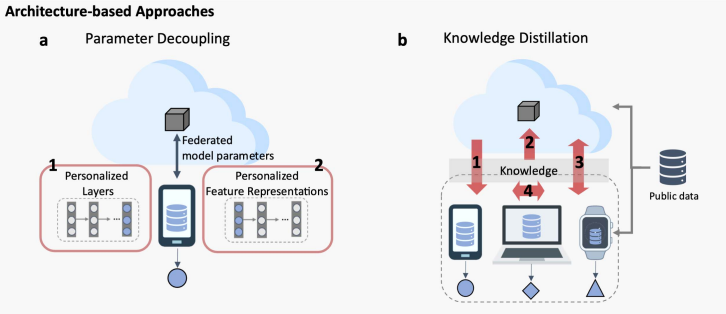
基于结构的个性化方案。包含参数分解和知识整理。
- 参数分解:为每个数据中心设置个性化层,个性化层只在本地训练,而其余的层参数需要上传至云端。这类方法的模型结构是一样的,但是每个数据中心的参数不一样。
- 知识蒸馏:通过知识蒸馏进行信息传递,数据中心之间的模型结构可以是不一致的。如上图所示,共有4种知识蒸馏的方向。
2.2.2. 基于相似性的方法
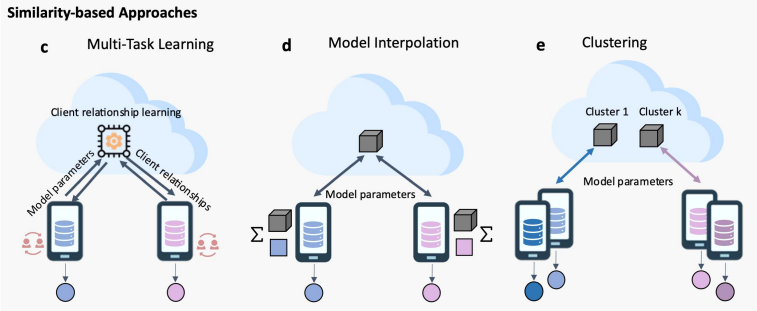
基于相似性的PFL方法:(1)多任务学习;(2)模型差值;(3)聚类
- 多任务学习:把联邦学习中的每个数据中心看成是一个任务。
- 模型差值:每个数据中心学一个本地模型,通过准许本地模型和全局模型存在一定偏差产生模型的个性化。
- 聚类:将数据中心之间聚类,并且对每一个类训练一个模型。
基于学习个性化模型的各类方法的优缺点比较:
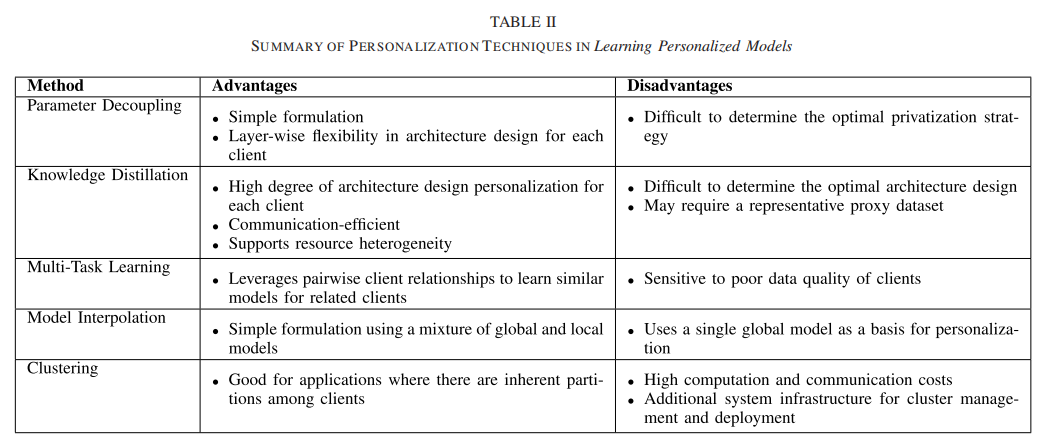
全文摘录于
个性化联邦学习:综述 - 知乎
这篇关于【论文 | 联邦学习】 | Towards Personalized Federated Learning 走向个性化的联邦学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









