本文主要是介绍elasticsearch es 字段值类型为集合,怎样过滤集合为空或集合不为空的记录?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考链接:
- https://stackoverflow.com/questions/15543308/elasticsearch-filtering-by-the-size-of-a-field-that-is-an-array
- https://stackoverflow.com/questions/32949321/best-way-to-check-if-a-field-exist-in-an-elasticsearch-document
- https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-exists-query.html
今天想要过滤集合 [] 为空的情况,搜了下国内的资料,没找到,我搬运一下 stackoverflow 上的回答,方便大家参考。
- 可以写脚本来过滤:
"filter" : {"script" : {"script" : "doc['fieldname'].values.length > 0"}
}
"filter" : {"script" : {"script" : "doc['fieldname'].values.length == 0"}
}
- 另外评论中 weixin_42003550 同学说,也可以用下面的方法 :
{"query": {"bool": {"must_not": [{"exists": {"field": "faith"}},{"exists": {"field": "children"}}]}}
}
- 我试了下也是可以的,这种方式可以的话,比用 painless 脚本效率要高。我原来以为,像这种空集合
"fieldName" : []
用 exists 也能查出来,后来试了下,这种空集合用 exists 查不出来,所以第二种方式也可以用,并且效率更高。
- es 官方文档 https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-exists-query.html 中明确说了 :
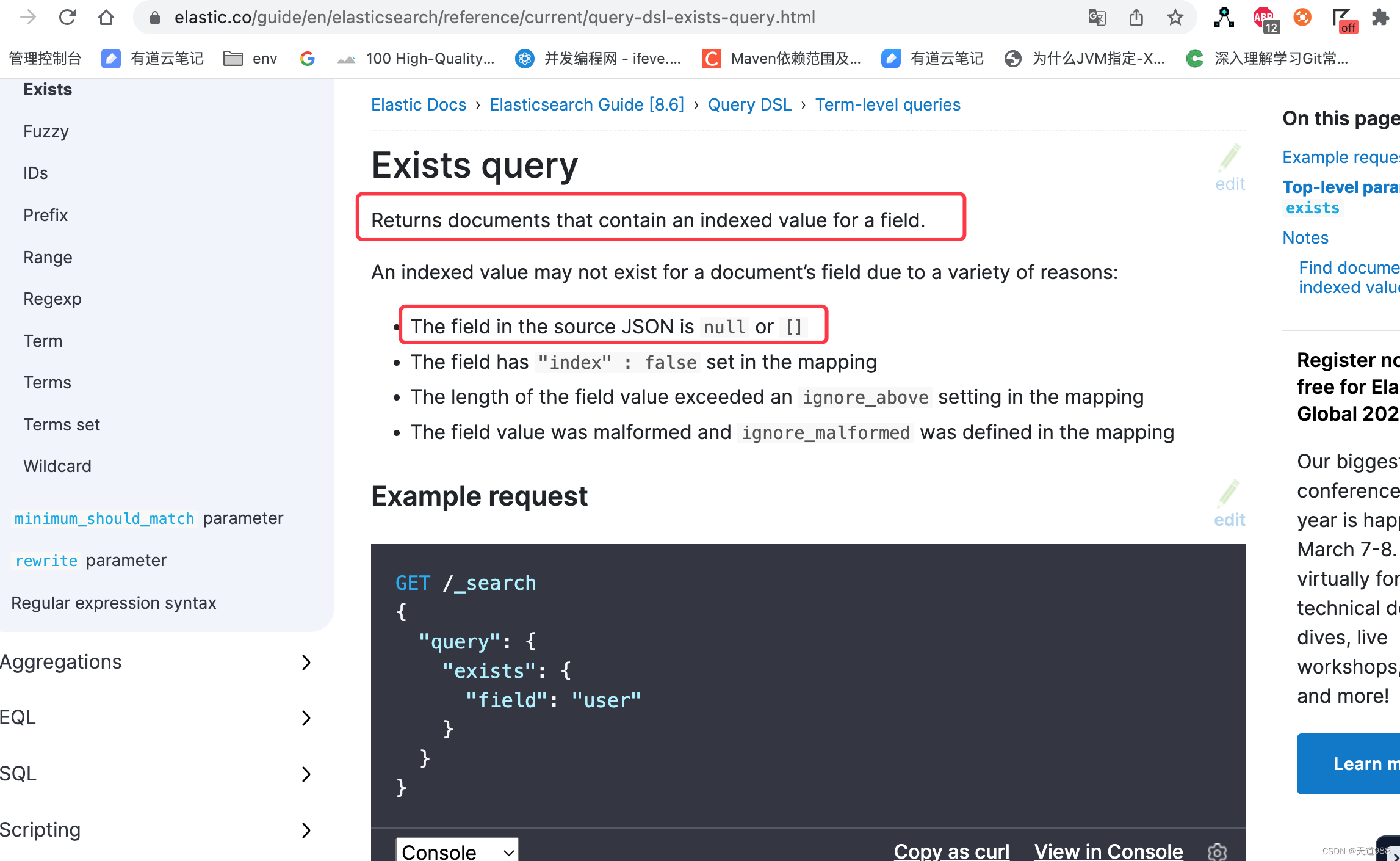
exists 查询会返回索引了某个字段的文档。而 null 、[] 空集合不会被索引。所以用 exits 是查询不出来 [] 空集合的文档的。
这篇关于elasticsearch es 字段值类型为集合,怎样过滤集合为空或集合不为空的记录?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



