本文主要是介绍【Python从入门到实战】太过瘾了,最全的Python数据结构总结,赞赞赞~,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
我是栗子——专为小白准备《Python从入门到实战》内容。

这不是上一期刚讲完循环判断,还给大家出了很多新手的题目,边学边练习才有效果嘛。
时隔几天,大家都吼完了叭~实在没写完的慢慢复习,我更新文章也挺慢的!哈哈哈哈
今天想一想:要学数据结构啦~

一、Python有那几种数据结构?
Python 有四种数据结构,分别是:列表、字典、元组,集合。每种数据结构都有自己的特点,并且都有着独到的用处。为了避免过早地陷入细枝末节。
我们先从整体上来认识一下这四种数据结构:从最容易识别的特征上来说,列表中的元素使用方括号扩起来,字典和集合是花括号,而元组则是圆括号。其中字典中的元素是均带有 ‘:’ 的 key 与 value 的对应关系组。

1)列表(list)
1.1 什么是列表?
最显著的特征是:
- 列表中的每一个元素都是可变的;
- 列表中的元素是有序的,也就是说每一个元素都有一个位置;
- 列表可以容纳 Python 中的任何对象。
列表中的元素是可变的,这意味着我们可以在列表中添加、删除和修改元素。
输入:
Weekday = ['Monday','Tuesday','Wednesday','Thursday','Friday']
print(Weekday[0])第三个特征是列表可以装入 Python 中所有的对象,往下看:
all_in_list = [1, #整数1.0, #浮点数'a word', #字符串print(1), #函数True, #布尔值[1,2], #列表中套列表(1,2), #元组{'key':'value'} #字典
]1.2列表的增删改查
对于数据的操作,最常见的是增删改查这四类。从列表的插入方法开始,输入:
fruit = ['pineapple','pear']
fruit.insert(1,'grape')
print(fruit)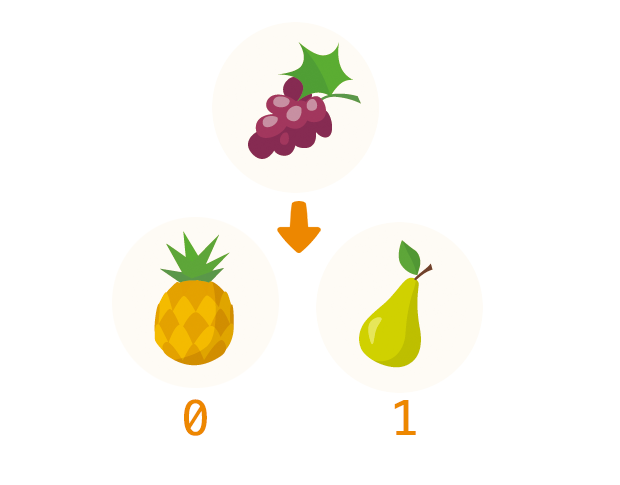
在使用 insert 方法的时候,必须指定在列表中要插入新的元素的位置,插入元素的实际位置是在指定位置元素之前的位置,如果指定插入的位置在列表中不存在,实际上也就是超出指定列表长度,那么这个元素一定会被放在列表的最后位置。
- 其他方法达到“插入”的效果:
fruit[0:0] = ['Orange']
print(fruit)- 删除列表中元素的方法是使用 remove():
fruit = ['pinapple','pear','grape']
fruit.remove('grape')
print(fruit)- 替换修改其中的元素:
fruit[0] = 'Grapefruit'- 删除还有一种方法,那就是使用 del 关键字来声明:
del fruit[0:2]
print(fruit)2)字典(Dictionary)
2.1 什么是字典?
字典这种数据结构的特征也正如现实世界中的字典一样,使用名称-内容进行数据的构建,在 Python 中分别对应着键(key)-值(value),习惯上称之为键值对。
字典的特征总结如下:
- 字典中数据必须是以键值对的形式出现的;
- 逻辑上讲,键是不能重复的,而值可以重复;
- 字典中的键(key)是不可变的,也就是无法修改的;而值(value)是可变的,可修改的,可以是任何对象。
举个小栗子:
这是字典的书写方式:NASDAQ_code = {'BIDU':'Baidu','SINA':'Sina','YOKU':'Youku'
}一个字典中键与值并不能脱离对方而存在,如果你写成 {'BIDU':} 会引发语法错误。
记住这两个特征: key 和 value 是一一对应的,key 是不可变的。
同时字典中的键值不会有重复,即便你这么做,相同的键值也只能出现一次:
a = {'key':123,'key':123}
print(a)2.2 字典的增删改查
首先我们按照映射关系创建一个字典:
NASDAQ_code = {'BIDU':'Baidu','SINA':'Sina'}与列表不同的是,字典并没有一个可以往里面添加单一元素的“方法”,但是我们可以通过这种方式进行添加:
NASDAQ_code['YOKU'] = 'Youku'
print(NASDAQ_code)列表中有用来添加多个元素的方法 extend() ,在字典中也有对应的添加多个元素的方法 update():
NASDAQ_code.update({'FB':'Facebook','TSLA':'Tesla'})删除字典中的元素则使用 del 方法:
del NASDAQ_code['FB']需要注意的是,虽说字典是使用的花括号,在索引内容的时候仍旧使用的是和列表一样的方括号进行索引,只不过在括号中放入的一定是——字典中的键,也就是说需要通过键来索引值:
NASDAQ_code['TSLA']同时,字典是不能够切片的,也就是说下面这样的写法应用在字典上是错误的:
chart[1:4] # WRONG!3)元组(Tuple)
元组其实可以理解成一个稳固版的列表,因为元组是不可修改的,因此在列表中的存在的方法均不可以使用在元组上,但是元组是可以被查看索引的,方式就和列表一样:
letters = ('a','b','c','d','e','f','g')
letter[0]4)集合(Set)
4.1什么是集合?
每一个集合中的元素是无序的、不重复的任意对象,我们可以通过集合去判断数据的从属关系,有时还可以通过集合把数据结构中重复的元素减掉。
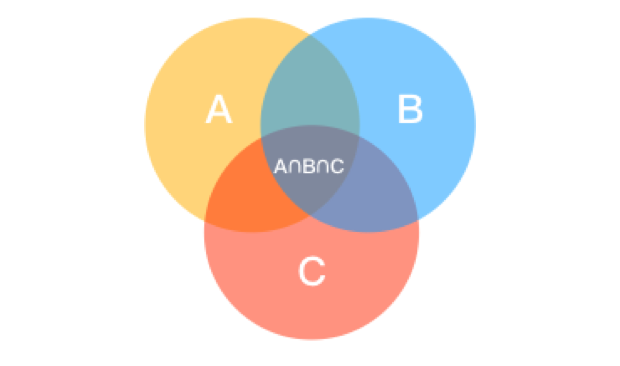
集合不能被切片也不能被索引,除了做集合运算之外,集合元素可以被添加还有删除:
a_set = {1,2,3,4}
a_set.add(5)
a_set.discard(5)5)番外——数据结构的一些技巧
5.1多重循环
举个栗子:比如,在整理表格或者文件的时候会按照字母或者日期进行排序,在 Python 中也存在类似的功能。
num_list = [6,2,7,4,1,3,5]
print(sorted(num_list))sorted 函数按照长短、大小、英文字母的顺序给每个列表中的元素进行排序。这个函数会经常在数据的展示中使用,其中有一个非常重要的地方,sorted 函数并不会改变列表本身,你可以把它理解成是先将列表进行复制,然后再进行顺序的整理。
在使用默认参数 reverse 后列表可以被按照逆序整理:
sorted(num_list,reverse=True)在整理列表的过程中,如果同时需要两个列表应该怎么办?这时候就可以用到 zip 函数,比如:
for a,b in zip(num,str):print(b,'is',a)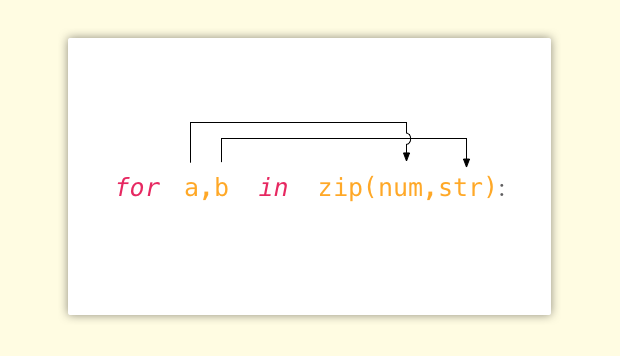
5.2推导式
数据结构中的推导式,也许你还看到过它的另一种名称叫做列表的解析式。
现在我有10个元素要装进列表中,普通的写法是这样的:
a = []
for i in range(1,11):a.append(i)下面换成列表解析的方式来写:
b = [i for i in range(1,11)]列表解析式不仅非常方便,并且在执行效率上要远远胜过前者,我们把两种不同的列表操作方式所耗费的时间进行对比,就不难发现其效率的巨大差异:
import timea = []
t0 = time.clock()
for i in range(1,20000):a.append(i)
print(time.clock() - t0, seconds process time")t0 = time.clock()
b = [i for i in range(1,20000)]
print(time.clock() - t0, seconds process time")得到结果:
8.999999999998592e-06 seconds process time
0.0012320000000000005 seconds process time列表推导式的用法也很好理解,可以简单地看成两部分。红色虚线后面的是我们熟悉的 for 循环的表达式,而虚线前面的可以认为是我们想要放在列表中的元素,在这个例子中放在列表中的元素即是后面循环的元素本身。
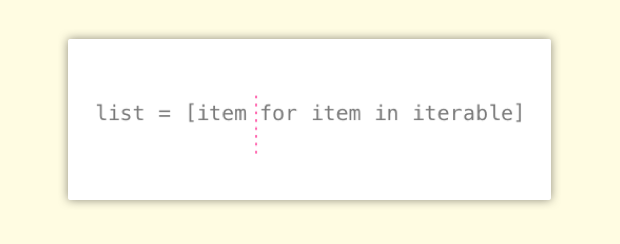
5.3循环列表时获取元素的索引
现在我们有一个字母表,如何能像图中一样,在索引的时候得到每个元素的具体位置的展示呢?
letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']a is 1
b is 2
c is 3
d is 4
e is 5
f is 6
g is 7前面提到过,列表是有序的,这时候我们可以使用 Python 中独有的函数 enumerate 来进行:
letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
for num,letter in enumerate(letters):print(letter,'is',num + 1)结尾
你学废了嘛?等过几天你学废了,记得评论吱一声,到时候我再更新~哈哈哈
快来跟我一起学习吧!关注小编,每天更新精彩内容哦~

这篇关于【Python从入门到实战】太过瘾了,最全的Python数据结构总结,赞赞赞~的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








