本文主要是介绍【论文记录】Deep Learning with Differential Privacy,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 差分隐私的隐私开销计算 (注: 实际上前面的PPT内容都是论文中的details)
记录几条需要搞清楚的疑问
- Introduction右边的三条
- PDF中的几条标记
- Theorem 1紧跟着的一段中如何根据the strong composition theorem得出 σ \sigma σ的渐进下界?
- 介绍到the strong composition theorem时,文章中标注的参考文献是[24], 但此文中并没有the strong composition theorem的概念。
The Moments Accountant
privacy loss random variable 的传统定义是: L M , D 1 , D 2 ( O ) = ln P [ M ( D 1 ) = O ] P [ M ( D 2 ) = O ] \mathcal{L}_{\mathcal M,D_1,D_2}(O) = \ln\frac{\,\, \mathbb{P}\left[\mathcal M(D_1)=O\right] \,\,}{\mathbb{P}\left[\mathcal M(D_2)=O\right]} LM,D1,D2(O)=lnP[M(D2)=O]P[M(D1)=O]
但本文中的定义在其中多添加了一条 auxiliary input aux 如下:
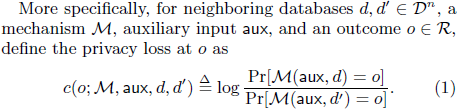
根据后续给出的定理及证明过程, 此 aux 指代的是 : 计算 P r [ M i ( d ) = o i ] Pr[\mathcal M_i(d)=o_i] Pr[Mi(d)=oi] 时的已知条件 ( M 1 , . . . , M i − 1 ) = ( o 1 , . . . , o i − 1 ) (\mathcal M_1,... \,,\mathcal M_{i-1})=(o_1,... \,,o_{i-1}) (M1,...,Mi−1)=(o1,...,oi−1)
这是由于本文采用的 design pattern 是 update the state by sequentially applying differentially private mechanisms. This is an instance of adaptive composition.
根据 privacy loss 随机变量 c ( o ; M , a u x , d , d ′ ) c(o; \mathcal M,aux,d,d') c(o;M,aux,d,d′)
再定义 α M ( λ ; a u x , d , d ′ ) \alpha_\mathcal M(\lambda;aux,d,d') αM(λ;aux,d,d′) 为 c ( o ; M , a u x , d , d ′ ) c(o; \mathcal M,aux,d,d') c(o;M,aux,d,d′)的矩量母函数的对数值。 α M ( λ ) = max a u x , d , d ′ α M ( λ ; a u x , d , d ′ ) \alpha_\mathcal M(\lambda) = \max\limits_{aux,d,d'} {\alpha_\mathcal M(\lambda;aux,d,d')} αM(λ)=aux,d,d′maxαM(λ;aux,d,d′) 。于是有定理 :

本文用上述定理 1 1 1来bound α M i ( λ ) \alpha_\mathcal {M_i}(\lambda) αMi(λ) , 再利用被bound的 α M ( λ ) \alpha_\mathcal M(\lambda) αM(λ)和定理 2 2 2来计算 δ \delta δ
my id : 根据上述这个定理 2 2 2的证明过程, 本文的作者是把 δ \delta δ 定义为了 P r [ c ( o ) ≥ ε ] Pr[c(o)\ge \varepsilon] Pr[c(o)≥ε] 的值, 但实际上此 δ \delta δ 可以更小 …?
定理 1 1 1的证明过程如下 :
 \quad\quad
\quad\quad 
其他阅读顺序
22 基础铺垫
8,53 本文是他们的跟进、延伸
+++++++++++++++++++++++++++++++++++++++++++++++++++++
24 关于strong composition theorem
+++++++++++++++++++++++++++++++++++++++++++++++++++++
42 关于privacy accountant
44 关于The moments accountant的来源: Renyi Differential Privacy
+++++++++++++++++++++++++++++++++++++++++++++++++++++
25 differentially private PCA algorithm
+++++++++++++++++++++++++++++++++++++++++++++++++++++
9 在 Moments accountant 中用到的 the privacy amplification theorem
+++++++++++++++++++++++++++++++++++++++++++++++++++++
58 用convex empirical risk minimization对数据集MNIST的实验精度
11 作为22的推广
23 advanced composition theorems and their refinements
这篇关于【论文记录】Deep Learning with Differential Privacy的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






