本文主要是介绍芯片出口对百度影响不大 /微软计划改革OpenAI董事会 /OPPO携手AndesGPT大模型 |魔法半周报,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我有魔法✨为你劈开信息大海❗
高效获取AIGC的热门事件🔥,更新AIGC的最新动态,生成相应的魔法简报,节省阅读时间👻
🔥资讯预览
-
百度2023年第三季度业绩发布:芯片出口限制对百度影响有限,AI大模型“文心一言”引领新发展
-
微软计划改革OpenAI董事会,加强公司治理措施
-
OPPO携手AndesGPT大模型,实现智能手机的革新与进化
-
人工智能时代:人机交互革命,挑战与机遇并存
-
"OpenAI的Karpathy录制了一场关于700亿参数的开源模型的讲座视频,涵盖LLM的训练、推理、未来发展和安全性"
🪄魔法简报
百度2023年第三季度业绩发布:芯片出口限制对百度影响有限,AI大模型“文心一言”引领新发展
百度创始人李彦宏在百度2023年第三季度业绩说明会上表示,美国对中国芯片出口的限制对百度的影响有限。百度拥有大量的人工智能芯片储备,并可以在未来1至2年内不断更新其AI大模型“文心一言”。

李彦宏指出,百度的芯片储备和其他替代品足以支持终端用户的大量AI本地应用程序。虽然难以获得最先进的芯片会影响中国AI发展的步伐,但百度正在积极寻找替代品。百度的财报显示,第三季度百度营收达344.47亿元,同比增长6%;净利润达73亿元,同比增长23%。

百度智能云事业群总裁沈抖提到,芯片的出口限制将减少百度客户训练自己模型的活动。百度计划用文心大模型重构广告系统,预计有望在第四季度带来数亿元的增量收入。百度将继续投资人工智能,特别是生成式AI和基础模型,推动公司营收的增长。
微软计划改革OpenAI董事会,加强公司治理措施
微软计划改造OpenAI董事会,以扩大其在公司治理中的话语权。上周OpenAI董事会罢免了首席执行官奥特曼,这令微软措手不及。微软正在讨论一份计划,要求OpenAI董事会进行治理改革,以防止微软再次被搞得措手不及。

微软可能要求OpenAI扩大董事会规模,并提高对董事会成员的经验要求。微软也在考虑是否让一名高管加入OpenAI董事会。微软希望解决导致OpenAI解雇奥特曼的治理问题,并加强对未来决策的保护措施。目前,微软正在等待新的OpenAI董事会产生,以进一步讨论这些变化。
OPPO携手AndesGPT大模型,实现智能手机的革新与进化
大模型正在让智能手机变得更加智能。OPPO的潘塔纳尔系统和AndesGPT模型的结合,实现了系统和应用之间的解耦,让服务和数据可以在不同设备和系统之间流转。这种解耦带来了更加灵活和便捷的用户体验。

同时,大模型的应用也带来了智能推荐和对话式交互等功能的革新。通过大模型的支持,智能手机可以更好地理解用户的需求,并提供更准确和个性化的服务。目前,OPPO已经在ColorOS 14中推出了对话式交互的应用,帮助用户解决日常高频使用的复杂设置。

这场变革不仅是从界面交互到对话交互的转变,更是从用户学习使用计算机到计算机主动理解用户需求的转变。大模型的应用将为智能手机带来更广阔的未来。
人工智能时代:人机交互革命,挑战与机遇并存
人类与机器的关系越来越亲密,人工智能大模型的发展加速了这一趋势。人们希望机器拥有真正的智能和情感,与人类进行深层次的情感交流。生成式人工智能的兴起引发了对于机器智能具备自我意识的期盼和恐惧。

人们面临着技术失效和技术失控的风险。技术失效可能导致社会运转失灵,而技术失控可能使人工智能摆脱人类的掌控。在人工智能时代,人类是否还能保持生活的主导地位,以及人类生活的基本运转依靠什么,都是需要思考的重要问题。

人与人工智能之间产生亲密情感也成为讨论的话题。然而,人们需要警惕技术乐观主义和发展主义的诱惑,保持反思和保障人的尊严,才能在人与AI共同生活的时代持续探索人的价值。
"OpenAI的Karpathy录制了一场关于700亿参数的开源模型的讲座视频,涵盖LLM的训练、推理、未来发展和安全性"
OpenAI的Karpathy录制了一场关于大型语言模型(LLM)的入门讲座视频。视频分为三个部分:LLMs、LLMs的未来和LLM安全。在第一部分中,Karpathy介绍了LLM的入门知识,并以一个有700亿参数的开源模型为例进行讲解。
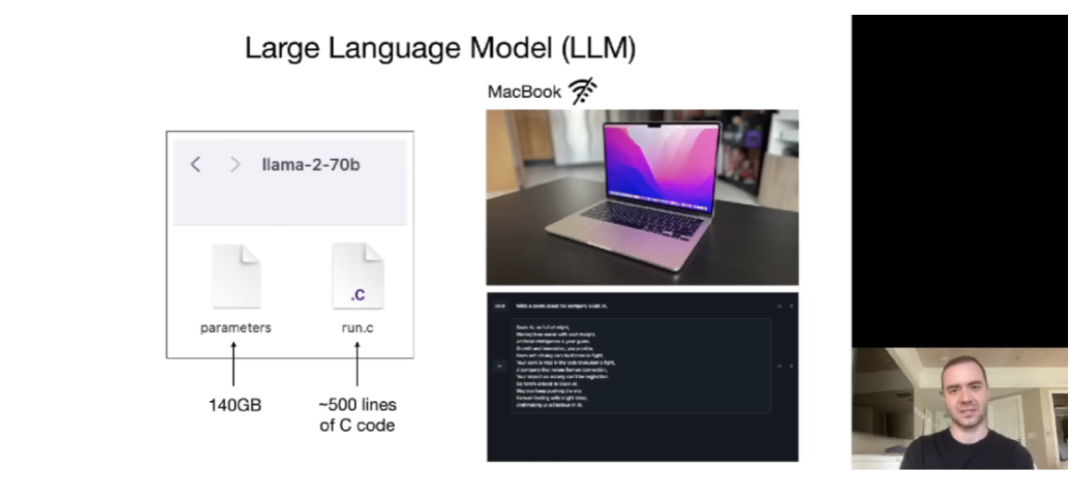
在第二部分中,他讨论了LLMs的未来发展,包括LLM的缩放法则、工具使用、多模态、思考模式、自我改进、定制化以及LLM操作系统等。第三部分讲述了LLM的安全性,涉及到越狱、提示注入和数据投毒等攻击方式。总的来说,这场讲座涵盖了LLM的训练、推理、未来发展和安全性等方面的内容。
如果对AIGC感兴趣,请关注我们的微信公众号“我有魔法WYMF”,我们会定期分享AIGC最新资讯和经典论文精读分享,让我们一起交流学习!!
这篇关于芯片出口对百度影响不大 /微软计划改革OpenAI董事会 /OPPO携手AndesGPT大模型 |魔法半周报的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









