本文主要是介绍TF2-归一化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# 归一化:
# 1:把数据变成(0,1)或者(1,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
# 2:把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。
# 归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。归一化算法有:
1、线性变换
y=(x-MinValue)/(MaxValue-MinValue)
2、对数函数转换
y = log10(x)
3、反余切函数转换
y = atan(x)*2/PI
import tensorflow as tf
from tensorflow import keras
import matplotlib as mpl
from matplotlib import pyplot as plt
%matplotlib inline
import sklearn
import numpy as np
import pandas as pd
import os
import sys
import time
#Get data:
fashion_mnist = keras.datasets.fashion_mnist #download the mnist data
(x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data() #split data to train and test
x_valid ,x_train = x_train_all[:5000],x_train_all[5000:] #splot train data to train and valid
y_valid ,y_train = y_train_all[:5000],y_train_all[5000:] #splot train data to train and valid
print(x_valid.shape,y_valid.shape)
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)
print(np.max(x_train),np.min(x_train))
255 0
#Normalization或StandarScaler(归一化)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()#归一化训练集,归一化输入的是float类型的二维数据,所以先转化为二维数据,得到结果之后在把shape换回来
x_train_scaled = scaler.fit_transform( x_train.astype(np.float32).reshape(-1,1)
).reshape(-1,28,28)
#归一化验证集
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)
).reshape(-1,28,28)
#归一化测试集
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)
).reshape(-1,28,28)print(np.max(x_train_scaled),np.min(x_train_scaled))
2.0231433 -0.8105136
# Tf.keras.Sequential (bulit model)
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape = (28,28)))
model.add(keras.layers.Dense(300,activation = "relu"))
model.add(keras.layers.Dense(100,activation = "relu"))
model.add(keras.layers.Dense(10,activation = "softmax"))#relu : y = max(x,0)
#softmax : change vertor to probability distributions#why sparse: y-> index ,y ->one hot->[](vector)
model.compile(loss = "sparse_categorical_crossentropy",optimizer = "sgd",metrics = ["accuracy"])
#Train
history = model.fit(x_train_scaled,y_train,epochs=10,validation_data=(x_valid_scaled,y_valid))
Train on 55000 samples, validate on 5000 samples
Epoch 1/10
55000/55000 [==============================] - 4s 80us/sample - loss: 0.9240 - accuracy: 0.6899 - val_loss: 0.6467 - val_accuracy: 0.7802
Epoch 2/10
55000/55000 [==============================] - 3s 63us/sample - loss: 0.5935 - accuracy: 0.7941 - val_loss: 0.5394 - val_accuracy: 0.8146
Epoch 3/10
55000/55000 [==============================] - 3s 64us/sample - loss: 0.5202 - accuracy: 0.8170 - val_loss: 0.4891 - val_accuracy: 0.8310
Epoch 4/10
55000/55000 [==============================] - 3s 63us/sample - loss: 0.4811 - accuracy: 0.8304 - val_loss: 0.4669 - val_accuracy: 0.8382
Epoch 5/10
55000/55000 [==============================] - 4s 64us/sample - loss: 0.4558 - accuracy: 0.8385 - val_loss: 0.4417 - val_accuracy: 0.8486
Epoch 6/10
55000/55000 [==============================] - 4s 64us/sample - loss: 0.4375 - accuracy: 0.8444 - val_loss: 0.4285 - val_accuracy: 0.8546
Epoch 7/10
55000/55000 [==============================] - 4s 64us/sample - loss: 0.4234 - accuracy: 0.8501 - val_loss: 0.4178 - val_accuracy: 0.8556
Epoch 8/10
55000/55000 [==============================] - 4s 64us/sample - loss: 0.4116 - accuracy: 0.8540 - val_loss: 0.4094 - val_accuracy: 0.8576
Epoch 9/10
55000/55000 [==============================] - 4s 65us/sample - loss: 0.4018 - accuracy: 0.8578 - val_loss: 0.4007 - val_accuracy: 0.8614
Epoch 10/10
55000/55000 [==============================] - 4s 64us/sample - loss: 0.3931 - accuracy: 0.8609 - val_loss: 0.3955 - val_accuracy: 0.8598
# Show learn result
def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize = (8,5))plt.grid(True)plt.gca().set_ylim(0,1)plt.show()
plot_learning_curves(history)
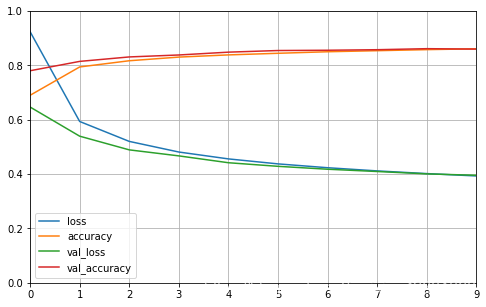
# test
model.evaluate(x_test_scaled,y_test)
10000/10000 [==============================] - 0s 40us/sample - loss: 0.4323 - accuracy: 0.8447[0.4322594210624695, 0.8447]
这篇关于TF2-归一化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





