本文主要是介绍分布式仿真SNN的思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
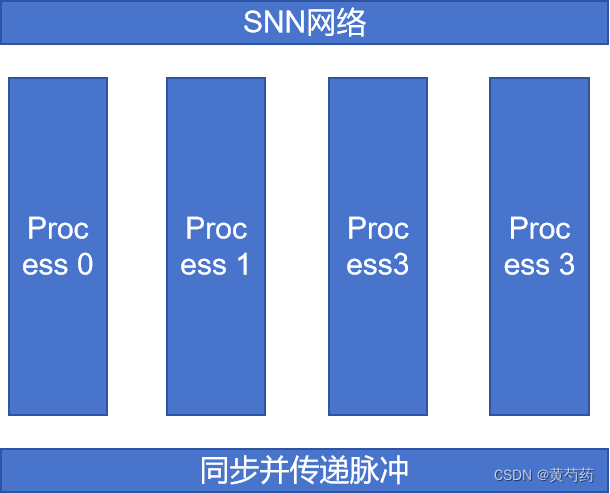
我之前实现的仿真完全基于如下图设计的

将整体的网络构成见一个邻接表,突触和神经元作为类分别存储,所以当一个神经元发射脉冲时,很容易的将脉冲传输到突触指向的后神经元。但是在分布式方丈中,由多个进程仿真整体的网络,如图所示
那么整体的邻接表就变成了
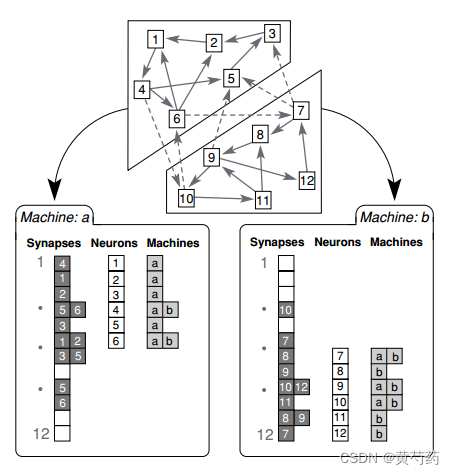
明显,对于神经元来说,很容易将其进行分区,但是对于突触来说就没那么简单了,有些文献建议将突触和后神经元存储在一起,邻接表就变成上图的格式。那当一个进程的神经元发生脉冲时,那么传图过程就变为了
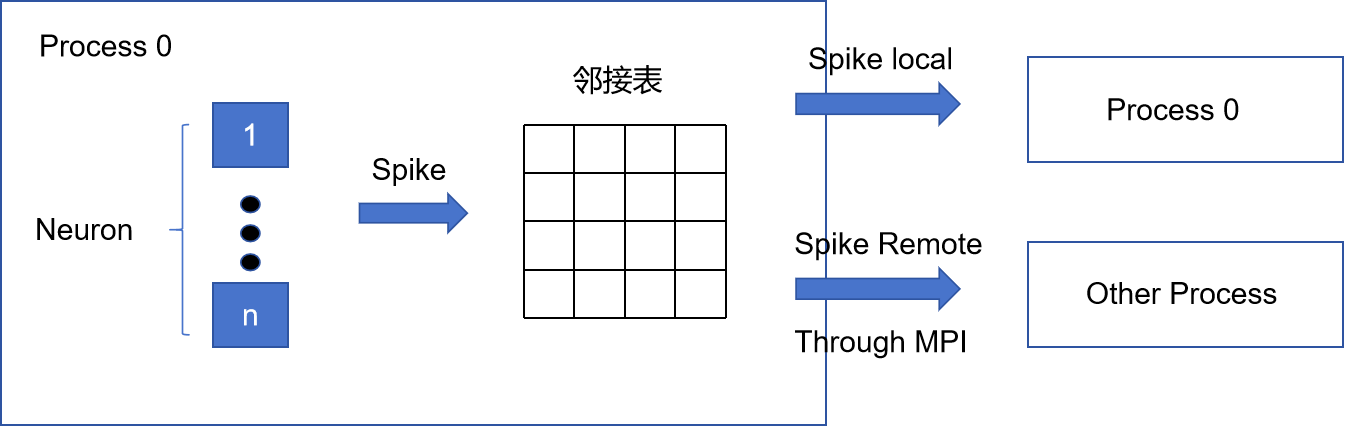 可以看到,问题的难点有两个
可以看到,问题的难点有两个
- 如何判断一个脉冲的后神经在是本进程还是其他进程
- 在我么的设计中,突触是和后神经元存储在一起的,那么当突触没有前身神经元的索引,如何建立脉冲、突触、和后神经元的关系呢。
对于第一个问题,我想出一种方案,能够解决一个神经元的后神经元是否在本地。如图所示
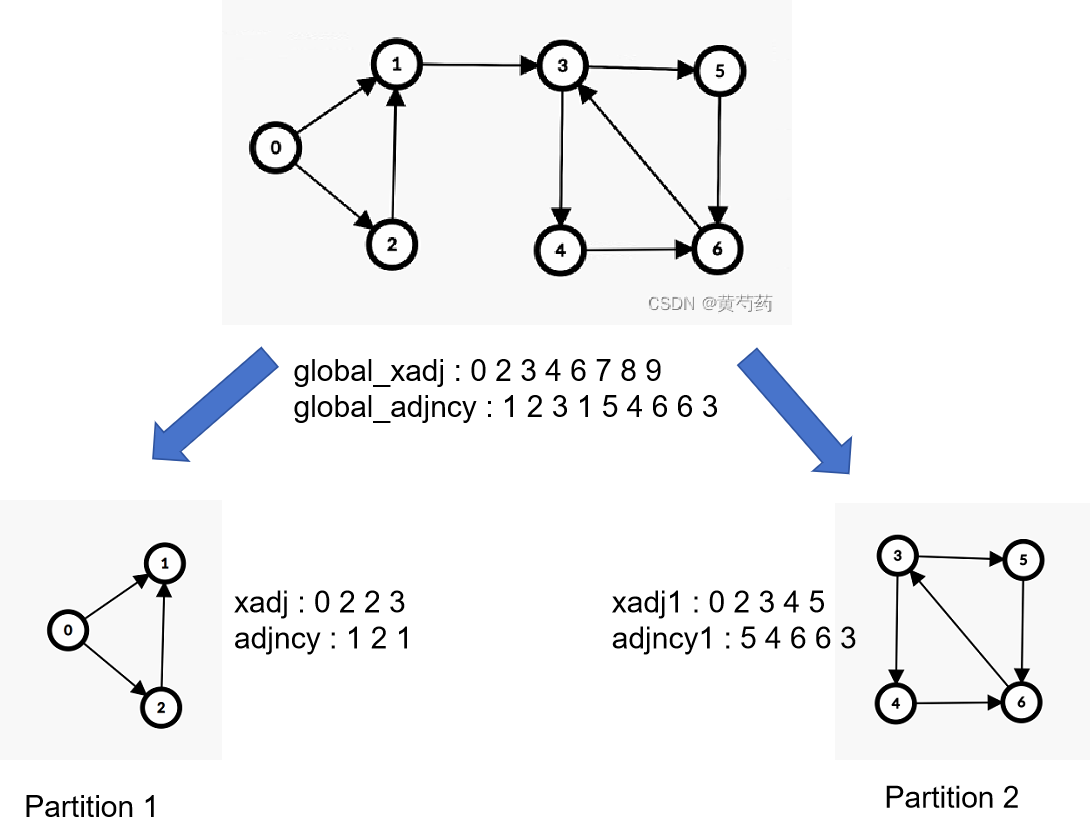
观察每一个图的CSR的存储,你就会发现,对于一个名为gid的神经元,如果他的xadj[gid]<xadj[gid+1],那么该神经元的后神经元就一定存在本地。难点就是如何判断该神经元的后神经元是否存在于别的进程。对于本地脉冲判断还是很容易的,但是远程脉冲似乎出现问题。讨论一下一个神经的后神经元的情况:

那么我们就针对这一种无法判断的情况具体分析。
我们知道xadj[gid+1]-xadj[gid]=该神经元的后神经元的个数,又因为(global_xadj[gid+1]-global_xadj[gid])>=(xadj[gid+1]-xadj[gid]),那么仅仅需要考虑,两种情况:
- (global_xadj[gid+1]-global_xadj[gid]) =(xadj[gid+1]-xadj[gid]),这和第二种可能相同。
- (global_xadj[gid+1]-global_xadj[gid]) >(xadj[gid+1]-xadj[gid]), 在这种情况下就一定满足即存在本地脉冲,也存在远程脉冲。
于是对于第一种难点我们就解决了,但是第二种,突触的实例化存储,以及远程脉冲如何查找突触,我暂时还没有好的思路。先这样吧,回来我在翻看一些资料。
这篇关于分布式仿真SNN的思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







