本文主要是介绍用 LangChain 搭建基于 Notion 文档的 RAG 应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如何通过语言模型查询 Notion 文档?LangChain 和 Milvus 缺一不可。
在整个过程中,我们会将 LangChain 作为框架,Milvus 作为相似性搜索引擎,用二者搭建一个基本的检索增强生成(RAG)应用。在之前的文章中,我们已经介绍过 LangChain 中的“自查询”(Self-querying)。本质上,LangChain 中的自查询功能就是构建一个基本的 RAG 架构,如图所示:

在 LangChain 中处理 Notion 文档共包含三个步骤:获取、存储和查询文档。获取是指获取 Notion 文档并将内容加载到内存中。存储步骤包括启动向量数据库(Milvus)、将文档转化为向量、将文档向量存储至向量数据库中。查询部分包括针对 Notion 文档进行提问。本文将带大家一一拆解这三个步骤,代码请参考 colab notebook。
01.获取 Notion 文档
用 LangChain 的 NotionDirectoryLoader将文档加载到内存中。我们提供文档的路径并调用load 函数来获取 Notion 文档。加载完毕后,可以得到 Notion 文档的 Markdown 文件。本例中我们以一个 Markdown 文件示意。
接下来,用 LangChain 的 markdown 标题文本分割器。我们向其提供一个分割符列表,然后传入之前命名的 md_file 来获取分割内容。在实际定义headers_to_split_on列表时,请使用自己 Notion 文档的标题。
# Load Notion page as a markdownfile filefrom langchain.document_loaders import NotionDirectoryLoader
path='./notion_docs'
loader = NotionDirectoryLoader(path)
docs = loader.load()
md_file=docs[0].page_content
# Let's create groups based on the section headers in our pagefrom langchain.text_splitter import MarkdownHeaderTextSplitter
headers_to_split_on = [
("##", "Section"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(md_file)
分割任务并检查分割结果。用 LangChain 的 RecursiveCharacterTextSplitter,使用一些不同的字符来进行分割。四个默认的检查字符是换行符、双换行符、空格或无空格。也可以选择传入自己的 separators 参数。
将 Notion文档进行分块时,我们还需要定义两个关键超参数——分块大小(chunk size)和分块重叠(chunk overlap)。本例中,分块大小为 64,重叠为 8。随后,我们就可以调用 split_documents 函数将所有文档进行分割。
# Define our text splitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 64
chunk_overlap = 8
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
all_splits = text_splitter.split_documents(md_header_splits)
all_splits
下图展示了部分分割的 document 对象,其中包含了页面内容和元数据。元数据显示了内容是从哪个章节中提取出来的。
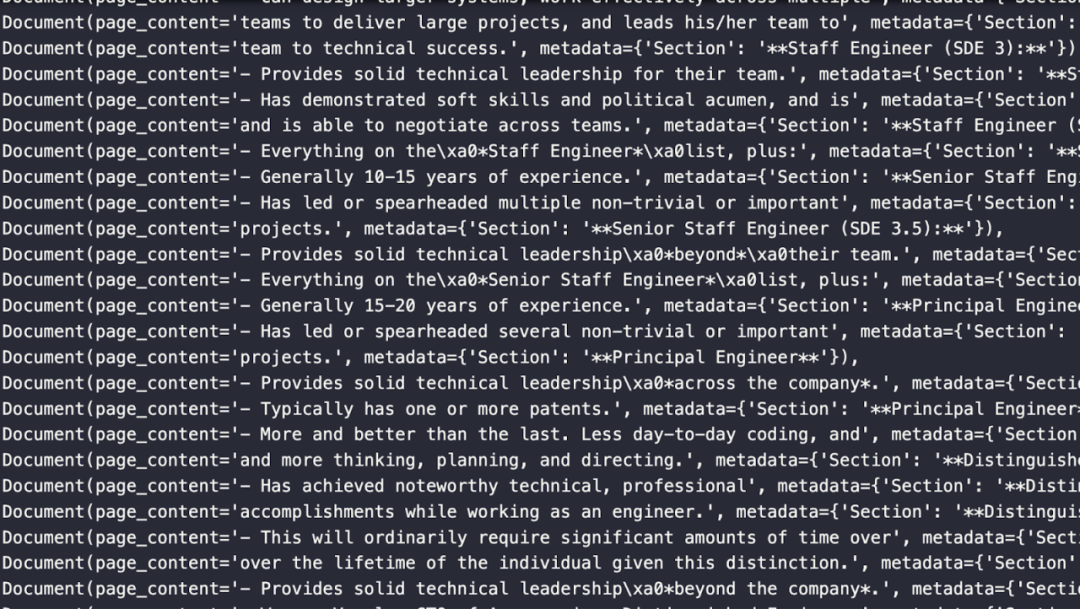
02.存储 Notion 文档
所有文档加载和分割完毕后,就需要存储这些文档块。首先,在 notebook 中直接运行向量数据库 Milvus Lite,随后导入所需的 LangChain 模块——Milvus 和 OpenAI Embeddings。
用 LangChain 的 Milvus 模块为文档块创建 Collection。这个步骤中我们需要传入的参数包括:文档列表、使用的 Embedding 模型、连接参数、以及 Collection 名称(可选)。
from milvus import default_server
default_server.start()
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
vectordb = Milvus.from_documents(documents=all_splits,
embedding=OpenAIEmbeddings(),
connection_args={"host": "127.0.0.1", "port": default_server.listen_port},
collection_name="EngineeringNotionDoc")
03.查询 Notion 文档
现在可以开始查询文档了。开始前,我们需要从 LangChain 中再导入三个模块:
-
OpenAI:用于访问GPT。
-
SelfQueryRetriever:用于搭建基本的 RAG 应用。
-
Attribute info:用于传入元数据的。
首先,我们定义元数据。随后,需要给自查询检索器提供文档的描述。本例中,描述即为“文档的主要部分”。在我们实例化自查询检索器前,现将 GPT 的温度(Temperature)设置为 0,并赋值给一个名为 llm 的变量。有了 LLM、向量数据库、文档描述和元数据字段后,我们就完成了自查询检索器定义。
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_fields_info = [
AttributeInfo(
name="Section",
description="Part of the document that the text comes from",
type="string or list[string]"
),
]
document_content_description = "Major sections of the document"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectordb, document_content_description, metadata_fields_info, verbose=True)
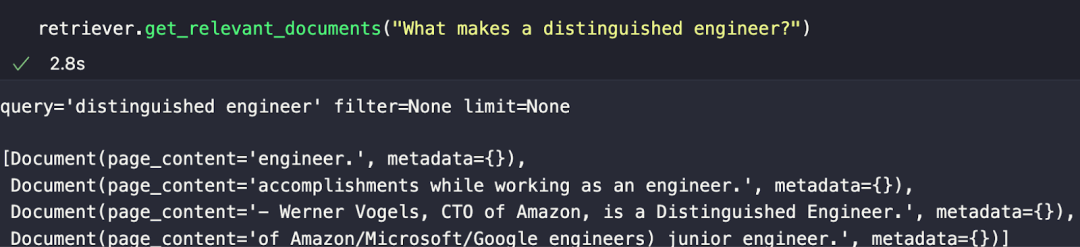
retriever.get_relevant_documents("What makes a distinguished engineer?")
以下例子中我们提出了一个问题:“一名优秀工程师有哪些品质?”(What makes a distinguished engineer?)
响应如下图所示。我们获得了与提问在语义上最相似的文档片段。但不难发现,其回答也仅仅只是语义上相似,并非完全正确。
本教程介绍了如何加载并解析 Notion 文档,并搭建一个基本的 RAG 应用查询 Notion 文档。我们使用到了 LangChain 作为框架,Milvus 作为向量数据库用于相似性搜索。如果想要进行深入的探索,建议大家调整分块大小和重叠等参数,检查不同的参数值是如何影响查询结果的。
所谓分块(Chunking)是构建检索增强型生成(RAG应用程序中最具挑战性的问题。具体的介绍和操作可参考《在 LangChain 尝试了 N 种可能后,我发现了分块的奥义!》
本文由 mdnice 多平台发布
这篇关于用 LangChain 搭建基于 Notion 文档的 RAG 应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







