本文主要是介绍Flink Window类型及使用原理案例实战-Flink牛刀小试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
版权声明:本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。版权声明:禁止转载,欢迎学习。QQ邮箱地址:1120746959@qq.com,如有任何问题,可随时联系。
1 Window(窗口)类型
- 聚合事件(比如计数、求和)在流上的工作方式与批处理不同。
比如,对流中的所有元素进行计数是不可能的,因为通常流是无限的(无界的)。所以,流上的聚合需要由 window 来划定范围,比如 “计算过去的5分钟” ,或者 “最后100个元素的和” 。 - window是一种可以把无限数据切割为有限数据块的手段
窗口可以是 时间驱动的 【Time Window】(比如:每30秒)或者 数据驱动的【Count Window】 (比如:每100个元素)。
-
窗口通常被区分为不同的类型:
tumbling windows:滚动窗口 【没有重叠】 sliding windows:滑动窗口 【有重叠】session windows:会话窗口
2 Window继承关系
3 Window计算原理

- 翻滚窗口:将数据根据固定窗口长度对数据进行切片。特点是:时间对齐,窗口长度固定,没有重叠。使用场景:适合做BI统计(做每个时间段的聚合统计)
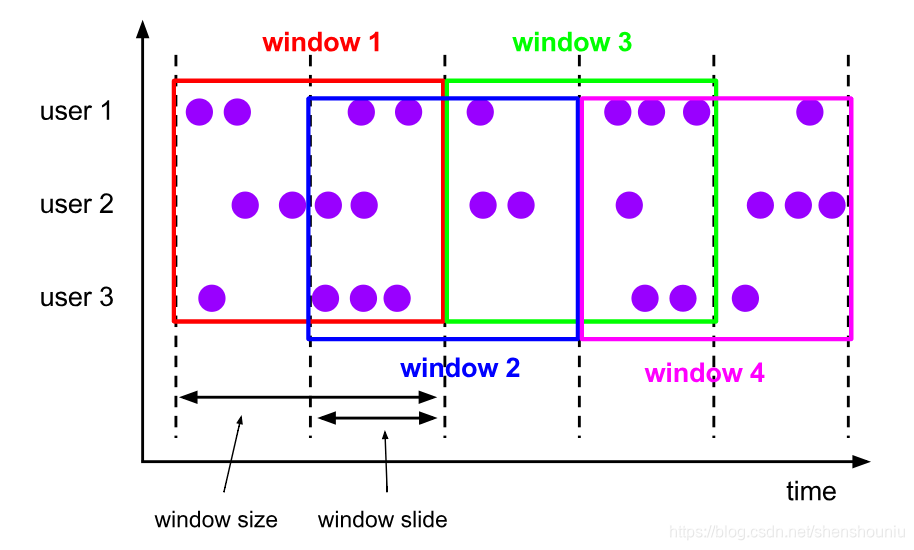
- 滑动窗口:滑动窗口由固定的窗口长度和互动间隔组成。特点是:时间对齐,窗口长度固定,有重
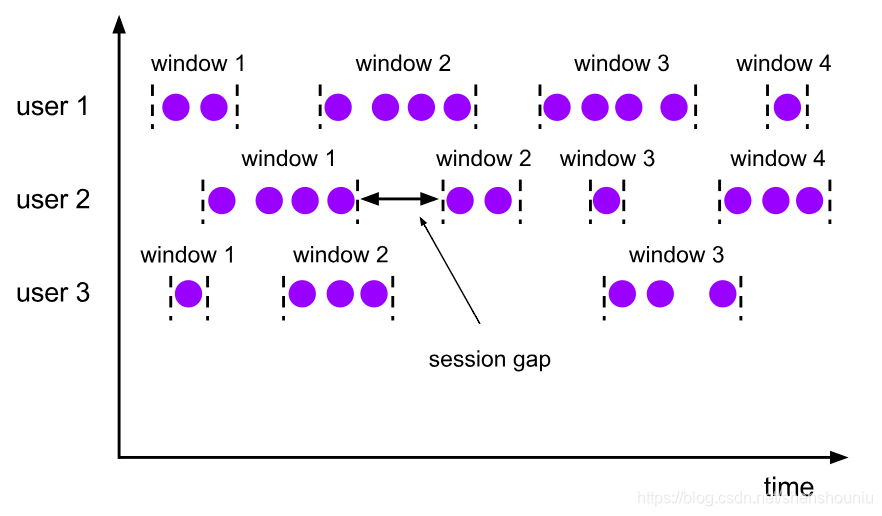
- 会话窗口:一段时间内没有接收到新数据就会就会生成新的窗口。特点:时间不对齐,适合线上用户行为分析。
4 Window API 快览
5 案例实战
5.1 时间窗口
5.1.1 TumblingEventTimeWindows 推荐使用:
DataStream<T> input = ...;// tumbling event-time windowsinput.keyBy(<key selector>).window(TumblingEventTimeWindows.of(Time.seconds(5))).<windowed transformation>(<window function>);// tumbling processing-time windowsinput.keyBy(<key selector>).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).<windowed transformation>(<window function>);// daily tumbling event-time windows offset by -8 hours.input.keyBy(<key selector>).window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8))).<windowed transformation>(<window function>);
5.1.2 sliding event-time windows 推荐使用:
DataStream<T> input = ...;// sliding event-time windows
input.keyBy(<key selector>).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))).<windowed transformation>(<window function>);// sliding processing-time windows
input.keyBy(<key selector>).window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).<windowed transformation>(<window function>);// sliding processing-time windows offset by -8 hours
input.keyBy(<key selector>).window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8))).<windowed transformation>(<window function>);
5.1.3 session windows with static gap 推荐使用:
DataStream<T> input = ...;// event-time session windows with static gap
input.keyBy(<key selector>).window(EventTimeSessionWindows.withGap(Time.minutes(10))).<windowed transformation>(<window function>);// event-time session windows with dynamic gap
input.keyBy(<key selector>).window(EventTimeSessionWindows.withDynamicGap((element) -> {// determine and return session gap})).<windowed transformation>(<window function>);// processing-time session windows with static gap
input.keyBy(<key selector>).window(ProcessingTimeSessionWindows.withGap(Time.minutes(10))).<windowed transformation>(<window function>);// processing-time session windows with dynamic gap
input.keyBy(<key selector>).window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {// determine and return session gap})).<windowed transformation>(<window function>);
5.2 计数窗口
6 Window 的聚合分类
-
增量聚合
窗口中每进入一条数据,就进行一次计算:reduce(reduceFunction)aggregate(aggregateFunction)sum(),min(),max()
-
全量聚合 等属于窗口的数据到齐,才开始进行聚合计算【可以实现对窗口内的数据进行排序等需求】
apply(windowFunction)process(processWindowFunction)processWindowFunction比windowFunction提供了更多的上下文信息。
7 总结
本文代码实例请参考水印处理上一篇博客,本文在于汇集了窗的离散知识,方便整体回顾,辛苦成文,实属不易,谢谢。
秦凯新 于深圳 20181152
这篇关于Flink Window类型及使用原理案例实战-Flink牛刀小试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




