本文主要是介绍rv1109/1126 rknn 模型部署过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
rv1109/1126是瑞芯微出的嵌入式AI芯片,带有npu, 可以用于嵌入式人工智能应用。算法工程师训练出的算法要部署到芯片上,需要经过模型转换和量化,下面记录一下整个过程。
量化环境
模型量化需要安装rk的工具包:
rockchip-linux/rknn-toolkit (github.com)
版本要根据开发板的固件支持程度来,如果二者不匹配,可能转出来的模型无法运行或者结果不对。
模型量化
rknn支持caffe,tensorflow,tflite,onnx,mxnet,pytorch等模型量化,下面以onnx为例,其他格式基本类似。即可以使用量化包带的可视化界面,也可以自行写代码,更推荐自己写代码,复用性和灵活性更强,对可视化界面一笔带过。
可视化量化工具
执行
python -m rknn.bin.visualization
选择对应格式,然后设置模型参数进行量化。
写代码量化
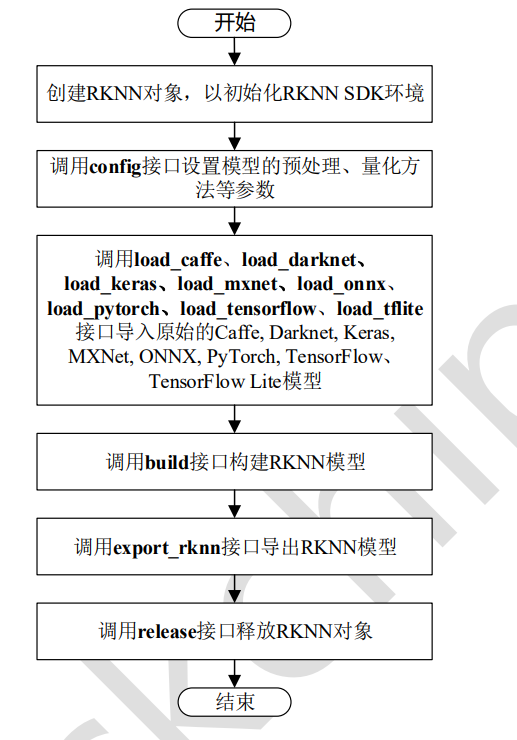
基础量化
最简单的量化方式如下,只需设置模型的均值、方差,载入原始模型,调用rknn.build接口,然后export_rknn即可。
from rknn.api import RKNNif __name__ == '__main__':rknn=RKNN()# pre-process configprint('--> config model')rknn.config(channel_mean_value='0 0 0 255',reorder_channel='0 1 2',target_platform=['rv1109'],#quantized_dtype="dynamic_fixed_point-i16")print('done')# Load mxnet modelonnx_model = 'yolov8n.onnx'print('--> Loading model')ret = rknn.load_onnx(onnx_model)if ret != 0:print('Load onnx_model model failed!')exit(ret)print('done')# Build modelprint('--> Building model')ret = rknn.build(do_quantization=True, dataset='../coco_resize.txt', pre_compile=False) # 若要在PC端仿真,pre_compile 为Falseif ret != 0:print('Build model failed!')exit(ret)print('done')print('--> Export RKNN model')ret = rknn.export_rknn('yolov8n_nohead.rknn')if ret != 0:print('Export RKNN model failed!')exit(ret)print('done')rknn.release()
模型量化需要提供量化图片的列表,格式为每行是一张图片的路径, 一般需要几百张,如:
images/0.jpg
images/1.jpg
模型推理验证
有两种方式验证模型的结果,一种是连接开发板,在开发板上运行,可以实际测试模型的推理速度,需要USB连接开发板,一种是在PC端仿真,速度较慢,适合在没有开发板的情况下,验证模型结果是否正确。两种方式使用的代码大部分一样,区别是在PC端仿真时,模型要以pre_compile=False模式进行量化,init_runtime参数为targe=None。
import os
import sys
from rknn.api import RKNN
import cv2
import numpy as npif __name__=="__main__":# Create RKNN objectrknn = RKNN()print('--> Loading RKNN model')ret = rknn.load_rknn('yolov8.rknn')if ret != 0:print('Load failed!')exit(ret)print('load done')# Init Runtimerknn.init_runtime(target="rv1109")#第二个参数device_id为开发板的设备id,不用填, targe=None时,代表PC仿真image = cv2.imread("1.jpg")outputs = rknn.inference(inputs=[image]) rknn.release()
量化精度评估(逐层)
有些时候,量化损失可能过大,这时我们希望能够逐层比对量化后模型与原始模型,这时需要使用accuracy_analysis接口,这个接口第一个参数是图片列表文件,里面是测试图片的路径,第二个参数是比对结果保存路径:
from rknn.api import RKNNif __name__ == '__main__':rknn=RKNN()# pre-process configprint('--> config model')rknn.config(channel_mean_value='0 0 0 255',reorder_channel='0 1 2',target_platform=['rv1109'],#quantized_dtype="dynamic_fixed_point-i16")print('done')# Load mxnet modelonnx_model = 'yolov8n.onnx'print('--> Loading model')ret = rknn.load_onnx(onnx_model)if ret != 0:print('Load onnx_model model failed!')exit(ret)print('done')# Build modelprint('--> Building model')ret = rknn.build(do_quantization=True, dataset='../coco_resize.txt', pre_compile=False) # 若要在PC端仿真,pre_compile 为Falseif ret != 0:print('Build model failed!')exit(ret)print('done')rknn.accuracy_analysis("test_list.txt", output_dir='./snapshot5') print('--> Export RKNN model')ret = rknn.export_rknn('yolov8n_nohead.rknn')if ret != 0:print('Export RKNN model failed!')exit(ret)print('done')rknn.release()
比对文件如下:
Conv__model.0_conv_Conv_214_out0_nhwc_1_320_320_16.tensor eculidean_norm=0.030792 cosine_norm=0.999525 eculidean=202.926056 cosine=0.999526
Sigmoid__model.0_act_Sigmoid_213_Mul__model.0_act_Mul_212_out0_nhwc_1_320_320_16.tensor eculidean_norm=0.049676 cosine_norm=0.998766 eculidean=178.751434 cosine=0.998767
Conv__model.1_conv_Conv_210_out0_nhwc_1_160_160_32.tensor eculidean_norm=0.103382 cosine_norm=0.994656 eculidean=521.709229 cosine=0.994656
Sigmoid__model.1_act_Sigmoid_211_Mul__model.1_act_Mul_209_out0_nhwc_1_160_160_32.tensor eculidean_norm=0.113702 cosine_norm=0.993536 eculidean=436.044495 cosine=0.993536
Conv__model.2_cv1_conv_Conv_208_out0_nhwc_1_160_160_32.tensor eculidean_norm=0.120058 cosine_norm=0.992793 eculidean=351.808380 cosine=0.992794
Sigmoid__model.2_cv1_act_Sigmoid_207_Mul__model.2_cv1_act_Mul_205_out0_nhwc_1_160_160_32.tensor eculidean_norm=0.169184 cosine_norm=0.985688 eculidean=262.819550 cosine=0.985688混合量化
有些时候,使用默认量化方法模型精度损失较大,我们通过逐层分析,也知道了那些层的损失较大,这时就需要控制一些层不量化,或以更高精度模式量化,这种方式就是混合量化。
与基础量化相比,混合量化分为两步:
第一步是通过rknn.hybrid_quantization_step1(替换基础量化中的rknn.build)获得模型的量化配置文件:
rknn.hybrid_quantization_step1(dataset='../coco_resize.txt')
该接口会生成3个文件:
xx.data
xx.json
xx.quantization.cfg
其中,.cfg文件时量化配置文件,用于控制每一层的量化:
%YAML 1.2
---
# add layer name and corresponding quantized_dtype to customized_quantize_layers, e.g conv2_3: float32
customized_quantize_layers: {}
quantize_parameters:'@attach_Concat_/model.22/Concat_5/out0_0:out0':dtype: asymmetric_affinemethod: layermax_value:- 647.7965087890625min_value:- 0.0zero_point:- 0scale:- 2.5403785705566406qtype: u8'@Concat_/model.22/Concat_5_1:out0':dtype: asymmetric_affinemethod: layermax_value:- 647.7965087890625min_value:- 0.0zero_point:- 0scale:- 2.5403785705566406qtype: u8
对于不量化或者以其他精度模式量化的层,以字典形式写在customized_quantize_layers中,rv1109支持asymmetric_quantized-u8,dynamic_fixed_point-i8和dynamic_fixed_point-i16,默认情况下,以asymmetric_quantized-u8方式量化,在需要更高精度时,可用dynamic_fixed_point-i16,但速度会更慢。对于损失较大的层,我们可以尝试设置dynamic_fixed_point-i16量化(若float32则不量化):
customized_quantize_layers: {"Split_/model.22/Split_21": "dynamic_fixed_point-i16","Reshape_/model.22/dfl/Reshape_20": "float32"
}
设置完成量化配置后,使用rknn.hybrid_quantization_step2进行量化:
from rknn.api import RKNNif __name__ == '__main__':rknn=RKNN()# pre-process configprint('--> config model')rknn.config(channel_mean_value='0 0 0 255',reorder_channel='0 1 2',target_platform=['rv1109'],#quantized_dtype="dynamic_fixed_point-i16")print('done')# Load mxnet modelonnx_model = 'yolov8n.onnx'print('--> Loading model')ret = rknn.load_onnx(onnx_model)if ret != 0:print('Load onnx_model model failed!')exit(ret)print('done')# Build modelprint('--> Building model')rknn.hybrid_quantization_step2(dataset='../coco_resize.txt', model_input='torch_jit.json',data_input="torch_jit.data",model_quantization_cfg="torch_jit.quantization.cfg",pre_compile=False)if ret != 0:print('Build model failed!')exit(ret)print('done')rknn.accuracy_analysis("test_list.txt", output_dir='./snapshot5') print('--> Export RKNN model')ret = rknn.export_rknn('yolov8n_nohead.rknn')if ret != 0:print('Export RKNN model failed!')exit(ret)print('done')rknn.release()
这篇关于rv1109/1126 rknn 模型部署过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






