本文主要是介绍基于LSTM模型的股票价格趋势预测,预测未来一天的开盘价格(附代码详解与注释),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:简介
该股票价格选取了谷歌股票2012年1月3日至2016年12月20日,每天股票开盘的价格,其中2016年11月30日之前的股票价格作为LSTM模型的训练数据集。12月1日至20日的开盘价格作为股票价格的预测集。
数据展示:
 测试集数据如该图所示;
测试集数据如该图所示;
二:模型介绍
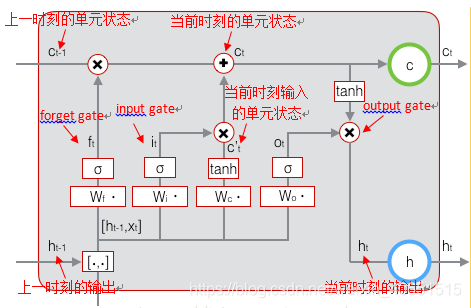
LSTM模型是基于时间序列的模型,其内的神经元细胞具有记忆功能,即在该问题上,就是之前的开盘价格会影响后期的开盘价格,意思是12月20日早上的开盘价格受12月19日开盘价格的影响,于是,LSTM模型内的记忆细胞就会选择性的记住12月19日的价格。这是对LSTM的直白理解。如有问题请留言指正。严谨的LSTM结果模型如下图所示:
三:代码实现
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# Part 1- Data Preprocessing
#importing training set
training_set=pd.read_csv('Google_Stock_Price_Train.csv')
#extract open value from the trainng data
training_set=training_set.iloc[:,1:2].values
#Feature Scaling
from sklearn.preprocessing import MinMaxScaler
sc=MinMaxScaler()
training_set=sc.fit_transform(training_set)
#Getting the input and output
X_train= training_set[:1236]
print(X_train)
Y_train=training_set[1:1257]
print(Y_train)
#Reshaping
X_train=np.reshape(X_train,(1236,1,1))
#Part-2 Building RNN
#importing keras library and packages
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
#Initalizing RNN
regressor=Sequential()
regressor.add(LSTM(units=50,activation='sigmoid', input_shape=(1,1)))
#Adding output layer (default argument)
regressor.add(Dense(units=1))
#Compile LSTM
regressor.compile(optimizer='adam',loss='mean_squared_error')
#Fitting the RNN on training set
regressor.fit(X_train,Y_train,batch_size=50,epochs=200)
#Part 3-Making Prediction and Visualizing Results
#Getting real Stock price for 2017
test_set=pd.read_csv('Google_Stock_Price_Test.csv')
real_stock_price=test_set.iloc[:,1:2].values
print(real_stock_price)
real_stock_price1=test_set.iloc[:,1:2].values
print(real_stock_price1)
#Getting predicted Stock price for 2017
inputs=real_stock_price
inputs=sc.transform(inputs)
inputs=np.reshape(inputs,(20,1,1)) #scaling the values
predicted_stock_price = regressor.predict(inputs)
predicted_stock_price = sc.inverse_transform(predicted_stock_price) #scaling to input values
#Visualize the results
x=[]
y1=[]
for i in range(20):x.append(i)
for j in range(20):y1.append(j)
plt.plot(x,real_stock_price1,'ro',color='red',label='Real Stock Price')
plt.plot(y1,predicted_stock_price,'ro',color='green',label='Predicted Stock Price')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
#Part 4- Evaluating the RNN
# since it is linear regression problem we will evaluate RMSE
import math
from sklearn.metrics import mean_squared_error
rmse=math.sqrt(mean_squared_error(real_stock_price, predicted_stock_price))
#expressing RMSE in percentage
rmse=rmse/800 # 800 becasue it is average value
训练结果:
............
50/1236 [>.............................] - ETA: 0s - loss: 1.5879e-04
950/1236 [======================>.......] - ETA: 0s - loss: 2.3606e-04
1236/1236 [==============================] - 0s 59us/step - loss: 2.5158e-04
Epoch 200/200
50/1236 [>.............................] - ETA: 0s - loss: 6.5003e-04
1050/1236 [========================>.....] - ETA: 0s - loss: 2.7387e-04
1236/1236 [==============================] - 0s 53us/step - loss: 2.5892e-04
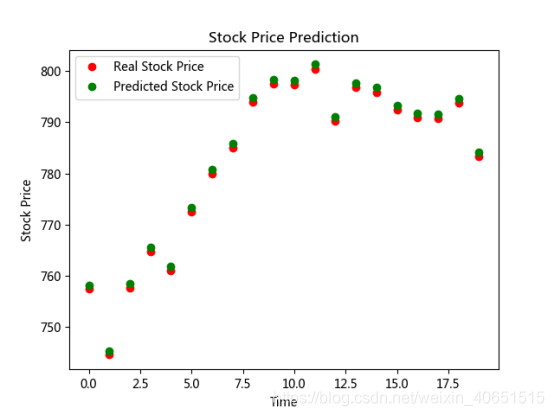
结果展示:
四:总结
该模型的主要目的就是训练该数据集根据前一天的开盘输入,能够预测出后一天的开盘价格,因此,输入训练集时输入0-1236行开盘价格为输入,而标签及为该1-2237行开盘价格,即标签往后推迟一天。最后训练的模型就行在测试集上进行测试。我将输出结果展示为散点图而不是折线图,其目的就是为了好给大家展示该预测结果与其真实值还是相当来说比较准的,但是该预测只是预测开盘价的走势。股票还有很多影响因素,其方法类似。
这篇关于基于LSTM模型的股票价格趋势预测,预测未来一天的开盘价格(附代码详解与注释)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





