本文主要是介绍使用R语言计算二项分布的概率和累计概率,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需求描述
利用R语言计算二项分布的概率和累计概率。
问题分析
假设某个试验是伯努利试验,其成功概率用p表示,那么失败的概率为q=1-p。进行n次这样的试验,成功了x次,则失败次数为n-x,发生这种情况的概率可用下面公式来计算:
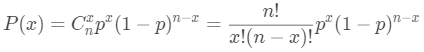
计算过程为:
![]()
=![]()
=120*0.0009765625
=0.1171875
这里的概率称之为概率质量函数,简称概率函数,而R里称之为密度函数是为了跟连续分布在概念上的统一。
而累计概率则为X≤7的所有概率之和,这里可以反过来求,即1减去X=8、X=9、X=10的概率,即
1-P(8)-P(9)-P(10) = 1-(10*9/2+10+1) *0.0009765625 = 0.9453125
实现方法
在R里可通过函数dbinom完成该概率的计算:
dbinom(7, size=10, prob=0.5)
[1] 0.1171875
在R里可通过函数pbinom完成该累计概率的计算:
pbinom(7, size=10, prob=0.5)
[1] 0.9453125
这篇关于使用R语言计算二项分布的概率和累计概率的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






