本文主要是介绍IA-RED²:视觉变换器的可解释性冗余降低,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
尽管transformer在视觉任务中取得了惊人的成绩,但仍然存在计算量大和内存成本高的问题。为了解决这个问题,作者提出了Interpretability-Aware REDundancy REDuction framework (
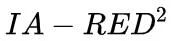
)。
作者认为计算量的冗余主要是因为不相关的input patch,因此引入一个可解释的模块用于动态地丢弃冗余patch。分层的网络架构逐渐丢弃不相关的token,大大减少了计算成本。在图像识别任务中,较DeiT有1.4倍加速;在视频动作识别任务中,较TimeSformer有4倍的提升。经过实验可以看到,该模型以极小的准确性为代价,可以达到效率和解释性的双赢。

论文信息
论文地址:https://arxiv.org/abs/2106.12620
论文链接:http://people.csail.mit.edu/bpan/papers/iared-preprint.pdf
代码压缩包:https://link.zhihu.com/?target=http%3A//people.csail.mit.edu/bpan/ia-red/ia-red_files/interpretation_tool.zip
IA-RED²的主要贡献
(1)第一个可解释性感知冗余减少的vision transformer框架;
(2)利用动态推理的框架自适应地计算和筛选输入序列的patch token,动态丢弃信息量少的patch,减少输入序列的长度,降低计算代价;
(3)模型无关性和任务无关性,可以进行不同模型和不同任务的实现;
(4)获得良好的解释性的结果,能更精确地感知到图像的具体的有信息的区域。
方法
本文方法建立在vision transformer(ViT)上,通过动态地在原始输入序列中去掉信息量较少的patch,降低vision transformer的冗余,以最小的计算量进行正确分类。
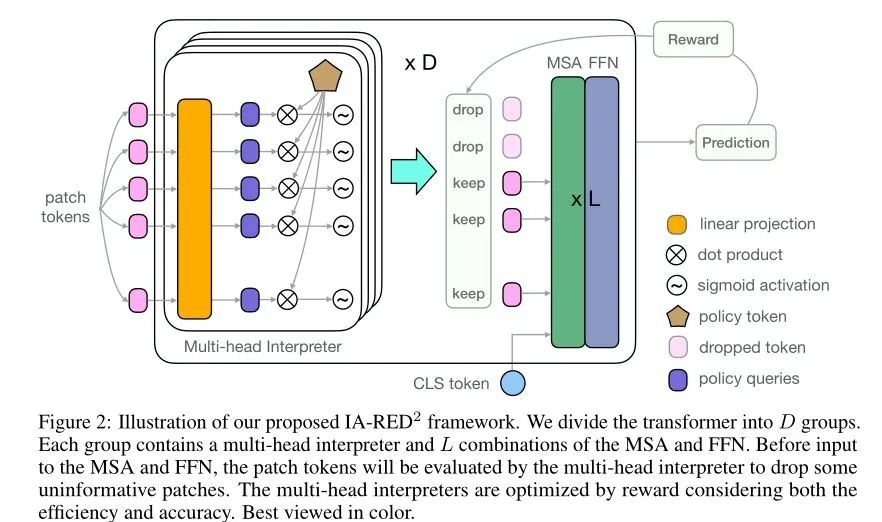
多头解释器Multi-head Interpreter
给定一个带有position信息的patch token序列
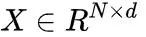
,利用多头解释器丢弃没有信息的patch token。首先将transformer层平均分为D组,每组包含1个多头解释器和L个MSA-FFN块。patch tokens经过多头解释器得到informative score
这篇关于IA-RED²:视觉变换器的可解释性冗余降低的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!