本文主要是介绍K近邻算法经典案例实现之海伦约会,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
上文实现了简单的K近邻算法,本文来介绍下完整的K近邻算法,将实际需求与算法进行结合,做个小小的demo,毕竟'talk is cheap,show me the code.'。
K近邻算法的一般流程如下:
- 收集数据:可以使用爬虫进行数据的收集,也可以使用第三方提供的免费或收费的数据。一般来讲,数据放在txt文本文件中,按照一定的格式进行存储,便于解析及处理。
- 准备数据:使用Python解析、预处理数据。
- 分析数据:可以使用很多方法对数据进行分析,例如使用Matplotlib将数据可视化。
- 测试算法:计算错误率。
- 使用算法:错误率在可接受范围内,就可以运行k-近邻算法进行分类
案例需求分析
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。datingTestSet.txt数据下载: 数据集下载
海伦收集的样本数据主要包含以下3种特征:
-
每年获得的飞行常客里程数
-
玩视频游戏所消耗时间百分比
-
每周消费的冰淇淋公升数
代码实现
数据解析以及可视化
因为原始数据往往不方便进行直接计算,因此需要对文件进行简单处理成我们需要的数据。可视化是为了方便直接观察数据的规律。
代码如下:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines# 数据预处理
def fileRead(fileName):#打开文件fr = open(fileName)#读取全部内容arraryOfLines = fr.readlines()#求行数numberOfLines = len(arraryOfLines)#生成numberOfLines行,3列的矩阵,方便后面存放数据returnMat = np.zeros((numberOfLines, 3))#用于存放类别classLabelVector = []#设置索引,用于循环index = 0#开始循环读取for line in arraryOfLines:#去除掉文件中的多余字符line = line.strip()#用空格对内容进行分割listFormLine = line.split('\t')#赋值returnMat[index, :] = listFormLine[0:3]#对类别数组进行赋值if listFormLine[-1] == 'didntLike':classLabelVector.append(1)if listFormLine[-1] == 'smallDoses':classLabelVector.append(2)if listFormLine[-1] == 'largeDoses':classLabelVector.append(3)index += 1return returnMat, classLabelVector# 数据展示
def showData(datingDataMat, datingLabels):fig, axs = plt.subplots(nrows=2, ncols=2, sharex=False, sharey=False, figsize=(13, 8))LabelsColors = []for i in datingLabels:if i == 1:LabelsColors.append('black')if i == 2:LabelsColors.append('orange')if i == 3:LabelsColors.append('red')axs[0][0].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 1], color=LabelsColors, s=15, alpha=.5)axs0_title_text = axs[0][0].set_title('flight_play')axs0_xlabel_text = axs[0][0].set_xlabel('flight_time')axs0_ylabel_text = axs[0][0].set_ylabel('play_time')plt.setp(axs0_title_text, size=9, weight='bold', color='red')plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')axs[0][1].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.5)# 设置标题,x轴label,y轴labelaxs1_title_text = axs[0][1].set_title('flight_eat')axs1_xlabel_text = axs[0][1].set_xlabel('flight')axs1_ylabel_text = axs[0][1].set_ylabel('eat')plt.setp(axs1_title_text, size=9, weight='bold', color='red')plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')# 画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5axs[1][0].scatter(x=datingDataMat[:, 1], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.5)# 设置标题,x轴label,y轴labelaxs2_title_text = axs[1][0].set_title('play_eat')axs2_xlabel_text = axs[1][0].set_xlabel('play_time')axs2_ylabel_text = axs[1][0].set_ylabel('eat_weight')plt.setp(axs2_title_text, size=9, weight='bold', color='red')plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')# 设置图例didntLike = mlines.Line2D([], [], color='black', marker='.',markersize=6, label='didntLike')smallDoses = mlines.Line2D([], [], color='orange', marker='.',markersize=6, label='smallDoses')largeDoses = mlines.Line2D([], [], color='red', marker='.',markersize=6, label='largeDoses')# 添加图例axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])# 显示图片plt.show()fileName = 'datingTestSet.txt'
datingDataMat, datingLabels = fileRead(fileName)
print("datingLabels is",datingLabels)
print("datingDataMat is",datingDataMat)
showData(datingDataMat,datingLabels)效果展示
类别矩阵以及初始数据矩阵

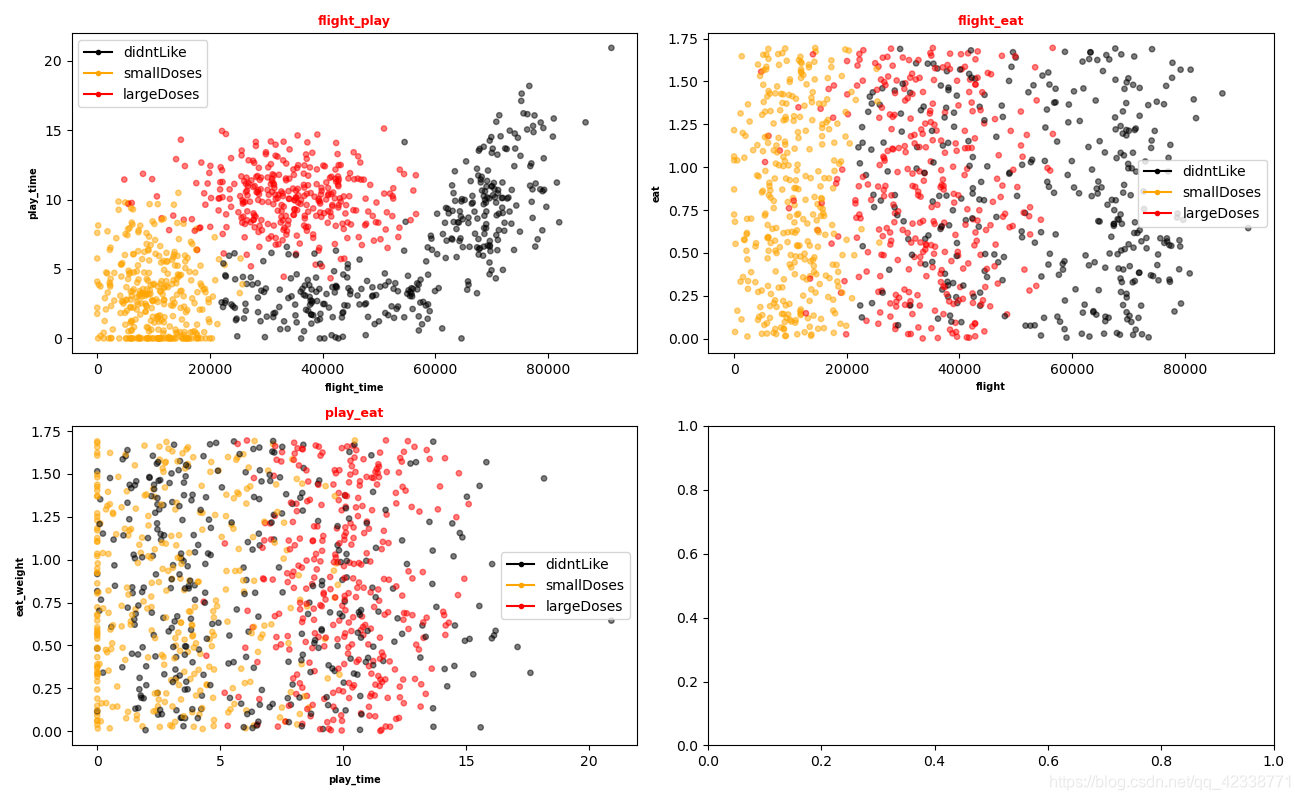
散点图
数据归一化
数据为什么要归一化?
通过上面的图片我们不难发现一个问题,飞行里程数的数据一般都是成百上千,但是吃冰淇淋的总量也就几升而已,这显然会影响欧式距离公式的计算结果,
就如我们小时候画直角坐标系的时候,如果x轴y轴数值差距过大,我们往往会为x,y轴设立不同的比例,以此来让数据更加规整,那是显示层面的,同理
为了让欧式距离公式计算更加精准,我们常用的方法一般为数值归一化,将取值范围取到0到1或者-1到1之间。
归一化公式如下:
n e w V a l u e s = ( o l d V a l u e − m i n ) / ( m a x − m i n ) newValues =(oldValue - min)/(max - min) newValues=(oldValue−min)/(max−min)
代码实现:
def autoNorm(dataSet):#获得数据的最小值minVals = dataSet.min(0)maxVals = dataSet.max(0)#最大值和最小值的范围ranges = maxVals - minVals#shape(dataSet)返回dataSet的矩阵行列数normDataSet = np.zeros(np.shape(dataSet))#返回dataSet的行数m = dataSet.shape[0]#原始值减去最小值normDataSet = dataSet - np.tile(minVals, (m, 1))#除以最大和最小值的差,得到归一化数据normDataSet = normDataSet / np.tile(ranges, (m, 1))#返回归一化数据结果,数据范围,最小值return normDataSet, ranges, minVals
测试算法性能:验证分类器
机器学习算法的一个重要部分就是对算法进行评估,在监督学习中,通常我们将90%的样本作为训练样本来训练分类器,10%的样本用来测试分类器的准确率。
算法上一期已经实现过,这里就不多赘诉了,直接上完整代码。
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
import operator# 数据预处理
def fileRead(fileName):# 打开文件fr = open(fileName)# 读取全部内容arraryOfLines = fr.readlines()# 求行数numberOfLines = len(arraryOfLines)# 生成numberOfLines行,3列的矩阵,方便后面存放数据returnMat = np.zeros((numberOfLines, 3))# 用于存放类别classLabelVector = []# 设置索引,用于循环index = 0# 开始循环读取for line in arraryOfLines:# 去除掉文件中的多余字符line = line.strip()# 用空格对内容进行分割listFormLine = line.split('\t')# 赋值returnMat[index, :] = listFormLine[0:3]# 对类别数组进行赋值if listFormLine[-1] == 'didntLike':classLabelVector.append(1)if listFormLine[-1] == 'smallDoses':classLabelVector.append(2)if listFormLine[-1] == 'largeDoses':classLabelVector.append(3)index += 1return returnMat, classLabelVector# 数据展示
def showData(datingDataMat, datingLabels):fig, axs = plt.subplots(nrows=2, ncols=2, sharex=False, sharey=False, figsize=(13, 8))LabelsColors = []for i in datingLabels:if i == 1:LabelsColors.append('black')if i == 2:LabelsColors.append('orange')if i == 3:LabelsColors.append('red')axs[0][0].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 1], color=LabelsColors, s=15, alpha=.5)axs0_title_text = axs[0][0].set_title('flight_play')axs0_xlabel_text = axs[0][0].set_xlabel('flight_time')axs0_ylabel_text = axs[0][0].set_ylabel('play_time')plt.setp(axs0_title_text, size=9, weight='bold', color='red')plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')axs[0][1].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.5)# 设置标题,x轴label,y轴labelaxs1_title_text = axs[0][1].set_title('flight_eat')axs1_xlabel_text = axs[0][1].set_xlabel('flight')axs1_ylabel_text = axs[0][1].set_ylabel('eat')plt.setp(axs1_title_text, size=9, weight='bold', color='red')plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')# 画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5axs[1][0].scatter(x=datingDataMat[:, 1], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.5)# 设置标题,x轴label,y轴labelaxs2_title_text = axs[1][0].set_title('play_eat')axs2_xlabel_text = axs[1][0].set_xlabel('play_time')axs2_ylabel_text = axs[1][0].set_ylabel('eat_weight')plt.setp(axs2_title_text, size=9, weight='bold', color='red')plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')# 设置图例didntLike = mlines.Line2D([], [], color='black', marker='.',markersize=6, label='didntLike')smallDoses = mlines.Line2D([], [], color='orange', marker='.',markersize=6, label='smallDoses')largeDoses = mlines.Line2D([], [], color='red', marker='.',markersize=6, label='largeDoses')# 添加图例axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])# 显示图片plt.show()# 数据归一化
def autoNorm(dataSet):minVals = dataSet.min(0)maxVals = dataSet.max(0)ranges = maxVals - minValsnormalDataSet = np.zeros(np.shape(dataSet))m = dataSet.shape[0]normalDataSet = dataSet - np.tile(minVals, (m, 1))normalDataSet = normalDataSet / np.tile(ranges, (m, 1))return normalDataSet, ranges, minVals#分类器
def classify(input, dataSet, labels, k):# numpy中的shape方法用于计算形状 eg: dataSet: 4*2# print(dataSet.shape)dataSetSize = dataSet.shape[0]# numpy中的tile方法,用于对矩阵进行填充# 将inX矩阵填充至与dataSet矩阵相同规模,后相减diffMat = np.tile(input, (dataSetSize, 1)) - dataSet# 平方sqDiffMat = diffMat ** 2# 求和sqDistance = sqDiffMat.sum(axis=1)# 开方distance = sqDistance ** 0.5# argsort()方法进行直接排序sortDist = distance.argsort()classCount = {}for i in range(k):# 取出前k个元素的类别voteIlabel = labels[sortDist[i]]# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。# 计算类别次数classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1# 排序sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)# 返回次数最多的类别,即所要分类的类别return sortedClassCount[0][0]fileName = 'datingTestSet.txt'
datingDataMat, datingLabels = fileRead(fileName)
showData(datingDataMat, datingLabels)
percent = 0.10
normalDataMat, ranges, minvals = autoNorm(dataSet=datingDataMat)
m = normalDataMat.shape[0]
numTestVecs = int(m*percent)
errorCount = 0.0
for i in range(numTestVecs):classifyResult = classify(normalDataMat[i,:],normalDataMat[numTestVecs:m,:],datingLabels[numTestVecs:m],4)print("分类结果:%d,真实类别:%d" % (classifyResult,datingLabels[i]))if(classifyResult!=datingLabels[i]):errorCount += 1.0
print("错误率:%f%%" %(errorCount/float(numTestVecs)*100))
运行截图

这篇关于K近邻算法经典案例实现之海伦约会的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






