本文主要是介绍R语言gWQS包在加权分位数和回归模型的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在流行病学研究中,相较于单一因素的暴露,多因素同时暴露的情况更为常见。传统模型在评价多因素联合暴露时存在数据维度高、多重共线性等问题. WQS 回归模型的基本原理是通过分位数间距及加权的方法,将多种研究因素的效应综合成为一个指数,再进行回归分析。不同因素赋予的权重反映了其对结局的影响程度。使用该模型时应满足各研究因素
对结局影响的方向相同这一基本假设.
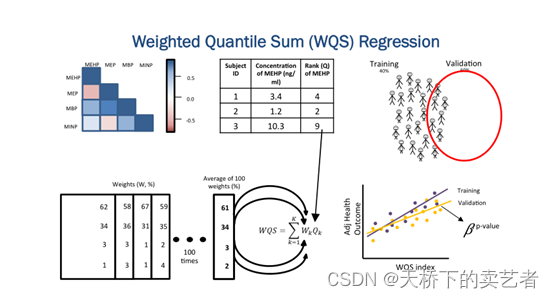
模型的一般形式为:
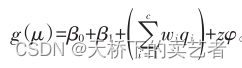
式中:c 表示污染物种类;β 0 表示截距;β 1 表示回归系数,用于限制联合效应对结局影响的方向;w i 表示第 i 种因素的未知权重,取值范围[0,1],且 ∑wi = 1,q i 表示对因素 i 进行 q 分位(如三、四分位等);

上公式表示c 种研究因素的综合权重指数;z 为协变量矩阵,φ为该矩阵的回归系数;g ( )为连接函数,μ 为均数。

下面咱们来进行演示一下,先导入R包和数据,数据使用的是gWQS自带的数据
library(gWQS)
library(ggplot2)
library(reshape2)
data(wqs_data)
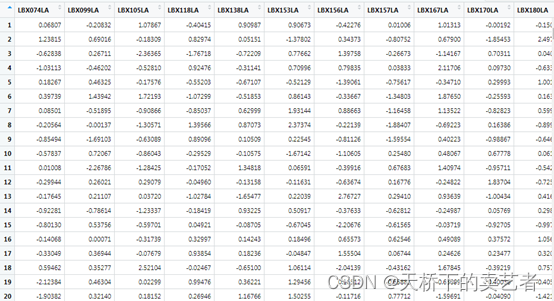
数据挺大的,上图只是数据的一部分,这些数据反映了参与NHANES研究(2001-2002)的受试者中34种多氯联苯暴露和25种邻苯二甲酸酯生物标志物的分布模拟的59种暴露浓度,概括来说就是一些指标的浓度,结局有连续变量和分类变量,还有性别作为协变量。
WQS 回归模型的思想就是把指标打包成一个指数,第一步先要确定咱们研究哪些指标,假设咱们研究的是前面34种指标
PCBs <- names(wqs_data)[1:34]
PCBs

然后就可以生成模型了, 通过 y ~ wqs+sex 将 y 与 34种 PCBs 的联合效应,建立回归方程并调整性别(sex)。其中wqs 是固定参数(即:必须包含项), mix_name=mix 表示指定联合暴露污染物,data =wqs_data 表示输入的数据集为 wqs_data;q=10表示将联合效应进行10分位,在实际运用过程中研究者可设置不同的分位数;validation=0.6 表示随机抽取数据集中的 60% 作为验证集,余下的 40% 作为训练集;b表示 bootstrap 随机抽样次数,该参数至少为 100;b1_pos=TRUE 表示设定联合效应的权重为正 (若为
负则设置为 FALSE);b1_constr=FALSE 表示使用优化算法对权重进行估计时不进行限制(若进行限制则设置为 TURE);family="gaussian"表示采用高斯分布进行拟合,也可根据研究对象的数据类型采用二项分布、多项式或泊松分布等进行拟合;由于涉及 boot⁃strap 随机抽样过程,将随机种子数 (seed) 设置为2021。
results2i <-gwqs (y ~ wqs+sex, mix_name=PCBs, data=wqs_data,q=10, validation=0.6, b=100, b1_pos=TRUE,b1_constr=FALSE, family="gaussian", seed=2021)
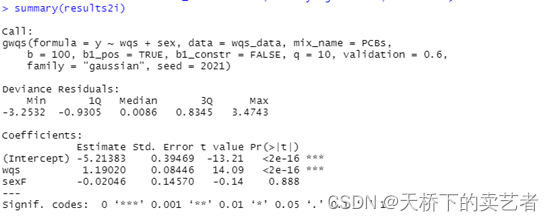
解析结果,可以看到这个联合指数是和结局相关的
summary(results2i)
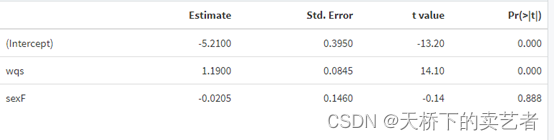
也可以使用gwqs解析函数,生成标准化表格
gwqs_summary_tab(results2i)
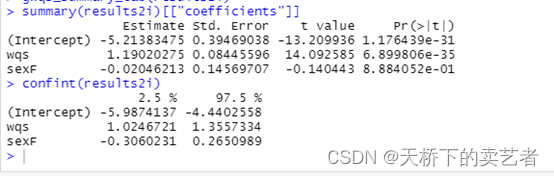
这样也可以查看系数和可信区间
summary(results2i)[["coefficients"]]
confint(results2i)
接下来咱们
咱们查看污染物权重构成比
gwqs_weights_tab(results2i)
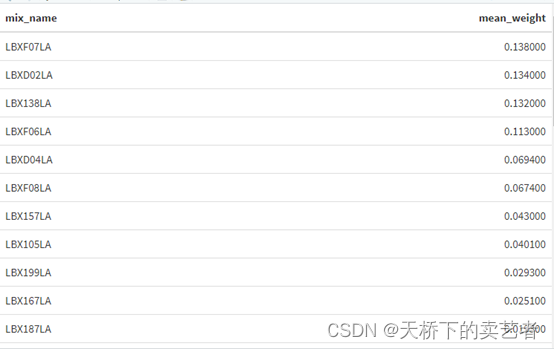
这样也可以的
results2i$final_weights
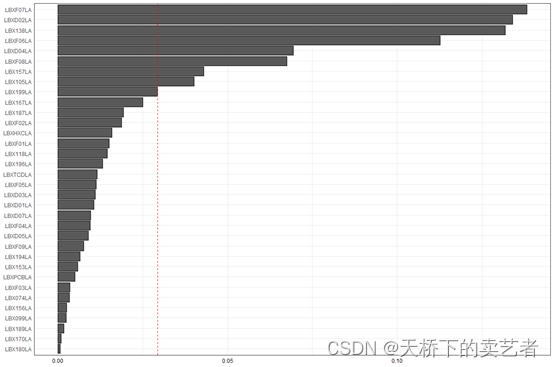
可以进一步可视化,画个条形图,咱们可以看到,前4个指标对结局影响最大
gwqs_barplot(results2i)
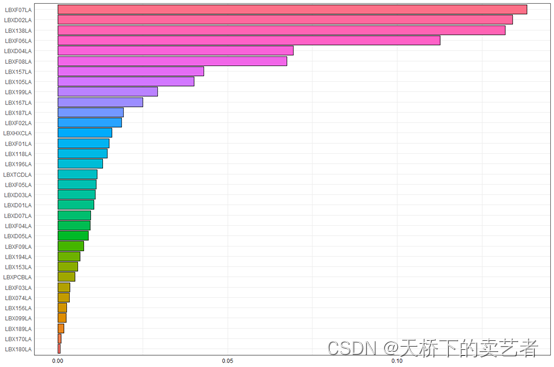
咱们也可以把数据提取出来使用ggplot来话,这样更加美观
w_ord <- order(results2i$final_weights$mean_weight)
mean_weight <- results2i$final_weights$mean_weight[w_ord]mix_name <- factor(results2i$final_weights$mix_name[w_ord],levels = results2i$final_weights$mix_name[w_ord])
dataplot <- data.frame(mean_weight, mix_name)ggplot(dataplot, aes(x = mix_name, y = mean_weight, fill = mix_name)) +geom_bar(stat = "identity", color = "black") + theme_bw() +theme(axis.ticks = element_blank(),axis.title = element_blank(),axis.text.x = element_text(color='black'),legend.position = "none") + coord_flip()
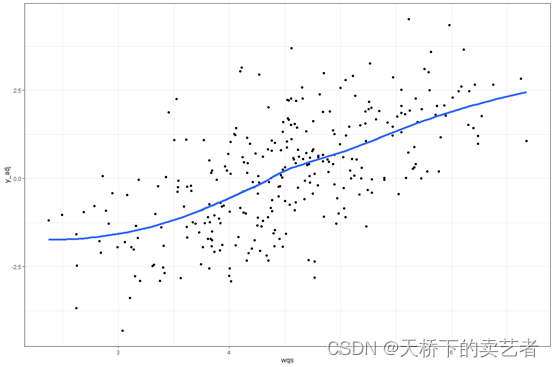
画个相关曲线图,可以看到是正相关
gwqs_scatterplot(results2i)
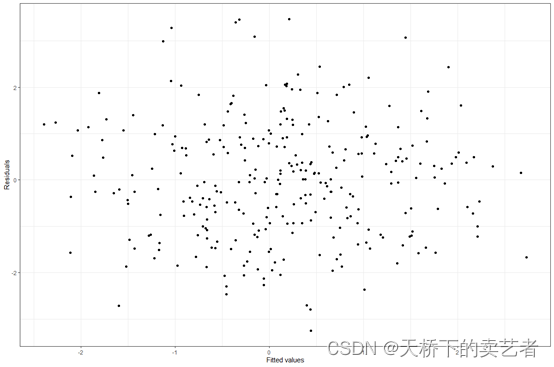
绘制残差图,可以检查它们是否随机分布在0附近或是否有趋势
gwqs_fitted_vs_resid(results2i)
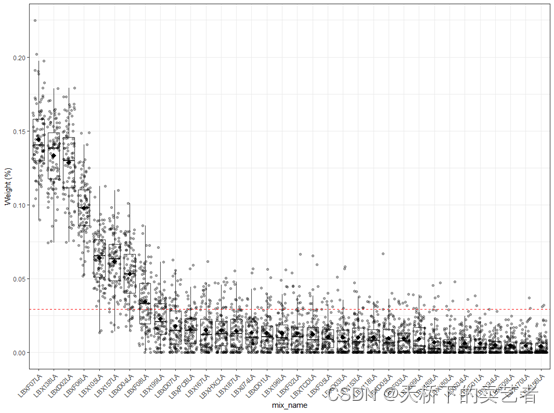
咱们还可以进行箱线图绘制,但是绘制箱线图需要使用gwqsrh函数生成下结果
results3i <-gwqsrh (y ~ wqs+sex, mix_name=PCBs, data=wqs_data,q=10, validation=0.6, b=5, b1_pos=TRUE,seed=2021,b1_constr=FALSE, family="gaussian", future.seed=TRUE)
生成结果后绘图
gWQS::gwqsrh_boxplot(results3i)
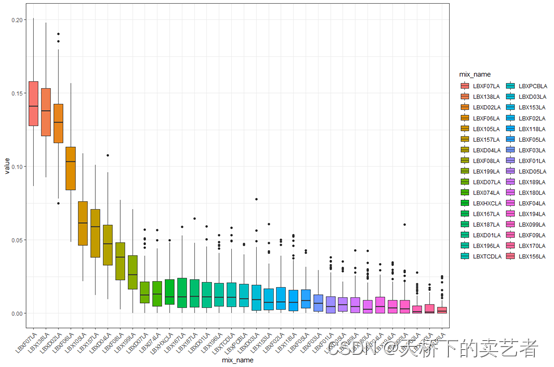
也可以使用ggplot提取数据绘图
wboxplot <- melt(results3i$wmat, varnames = c("rh", "mix_name"))wboxplot$mix_name <- factor(wboxplot$mix_name, levels = results3i$final_weights$mix_name)ggplot(wboxplot, aes(x = mix_name, y = value,fill=mix_name))+geom_boxplot()+theme_bw()+theme(axis.text.x = element_text(angle = 45, hjust = 1))
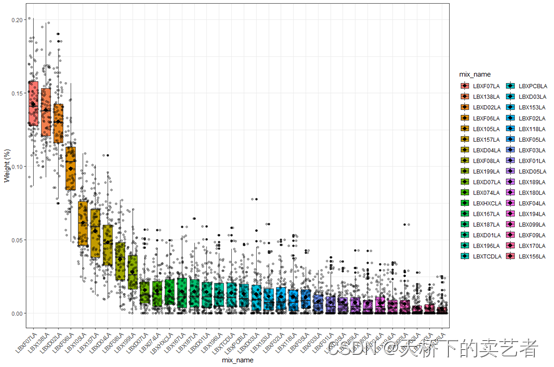
还可以调整一下
ggplot(wboxplot, aes(x = mix_name, y = value,fill=mix_name))+geom_boxplot()+theme_bw()+theme(axis.text.x = element_text(angle = 45, hjust = 1))+ylab("Weight (%)") + stat_summary(fun.y = mean, geom = "point", shape = 18, size = 3) + geom_jitter(alpha = 0.3)
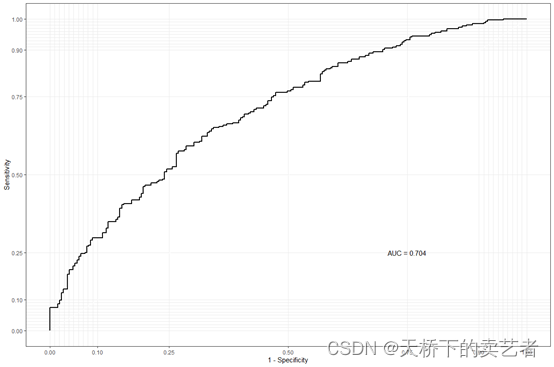
如果结局是二分类指标,咱们还可以绘制roc曲线,咱们从新生成一个结果
results4i <-gwqs (ybin ~ wqs+sex, mix_name=PCBs, data=wqs_data,q=10, validation=0.6, b=100, b1_pos=TRUE,b1_constr=FALSE, family="binomial", seed=2021)gwqs_ROC(results4i,wqs_data)
参考文献
- gwqs说明文件
- Carrico C , Gennings C , Wheeler D C ,et al.Characterization of Weighted Quantile Sum Regression for Highly Correlated Data in a Risk Analysis Setting[J].Journal of Agricultural, Biological, and Environmental Statistics, 2014.DOI:10.1007/s13253-014-0180-3.
- 李珽君,黄俊理,陈海建,莫春宝.加权分位数和回归模型的应用及R软件实现[J].预防医学,2023,35(3):275-276.DOI:10.19485/j.cnki.issn2096-5087.2023.03.021.
- https://blog.csdn.net/qq_42458954/article/details/120157806
- https://blog.csdn.net/weixin_42812146/article/details/126192945
这篇关于R语言gWQS包在加权分位数和回归模型的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






