本文主要是介绍Human-Like Machine Hearing With AI (3/3)--Results and perspectives.,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章来自
Author :Daniel Rothmann
原文网站:链接
未翻译...
This is the last part of my article series on “Human-Like” Machine Hearing: Modeling parts of human hearing to do audio signal processing with AI.
This last part of the series will provide:
- A concluding summary of the key ideas.
- Results from empirical testing.
- Related work and future perspectives.
If you’ve missed out on the previous articles, here they are:
Background: The promise of AI in audio processing
Criticism: What’s wrong with CNNs and spectrograms for audio processing?
Part 1: Human-Like Machine Hearing With AI (1/3)
Part 2: Human-Like Machine Hearing With AI (2/3)
Summary.
Understanding and processing information at an abstract level is not an easy task. Artificial neural networks have moved mountains in this area. Especially for computer vision: Deep 2D CNNs have been shown to capture a hierarchy of visual features, increasing in complexity with each layer of the network. The convolutional neural network was inspired by the Neocognitron which in turn was inspired by the human visual system.
Attempts have been made at reapplying techniques such as style transfer in the audio domain, but the results are rarely convincing. Visual methods don’t seem to reapply well on sounds.
I have argued that sound is a different beast altogether. It’s something to keep in mind when doing feature extraction and designing deep learning architectures. Sounds behave differently. Just like computer vision benefited from modeling the visual system, we can benefit from considering human hearing when working with sound in neural networks.

Photo credit: Steve Harvey
Sound representation.
To start exploring a modeling approach, we can establish a human baseline:
To the brain, sounds are spectrally represented. Pressure waves are processed by the cochlea and divided into ~3500 logarithmically spaced frequency bands in the range ~20-20,000 Hz.
Sounds are heard at a temporal resolution of 2–5 ms. Sounds (or gaps in sounds) shorter than this are something near imperceptible to humans.
Based on this information, I recommend using a Gammatone filterbankinstead of the Fourier Transform. Gammatone filterbanks are a common tool in auditory modeling and generally, filterbanks allow for the decoupling of spectral and temporal resolutions. This way, you can have a many spectral bands and a short window of analysis.
Memory and buffers.
Humans are thought to have memory for storing sensory impressions in the short-term so that they can be compared and integrated. Although experimental results differer slightly, they have shown that humans have ~0.25–4 seconds of echoic memory (sensory memory dedicated to sound).
Any sound that can be understood by a human being can be represented within these limits!
A couple of seconds worth of 2–5 ms windows, each with ~3500 logarithmically spaced frequency bands. But that does add up to a lot of data.

Two dilated buffers covering ~1.25s of sound with 8 time steps.
To reduce the dimensionality a bit, I proposed the idea of dilated buffers, where the temporal resolution of a time series is reduced by an increasing factor for older timesteps. This way, a larger time context can be covered.

Photo credit: Alireza Attari
Listener-processor architecture.
We can conceptualize the inner ear as a spectral feature extractor and the auditory cortex as an analytical processor, deriving “cognitive properties”from memories of auditory impressions.
In between, there is a set of steps often forgotten about. They’re referred to as the cochlear nuclei. There’s a lot we don’t know about these, but they do a sort of initial neural coding of sounds: Encoding basic features essential to localization and sound identification.
This led me to explore a listener-processor model, where sound buffers are embedded to a low-dimensional space by a general-purpose LSTM autoencoder (a “listener”) before being passed to a task-specific neural network (a “processor”). That essentially makes the autoencoder a reusable preprocessing step for doing some task-specific analytical work on a sound.

A listener-processor architecture to do sound classification.
Results.
I like to think this article series has presented a couple of fresh ideas for working with sound in neural networks. Using these principles, I built a model to do environmental sound classification using the UrbanSound8K dataset.
Due to limited computing resources, I settled for humble representation:
- 100 Gammatone filters.
- 10 ms analysis windows.
- 8-step dilated buffers covering ~1.25 seconds of sound.
To train the listener, I fed thousands of dilated buffers to an autoencoder with 2 LSTM layers on each side, encoding the 800-dimensional sequential input into a latent space with 250 “static” dimensions.

An illustration of the LSTM autoencoder architecture.
After training for ~50 epochs, the autoencoder was able to capture the coarse structures for most of the input buffers. Being able to produce an embedding that captures the complex sequential movements of frequencies in sounds is very interesting!
But is it useful?
This is the question to ask. To test this, I trained a 5-layer self-normalizing neural network to predict the sound class (UrbanSound8K defines 10 possible classes) using embeddings from the LSTM encoder.
After 50 epochs of training, this network predicted sound class with an accuracy of ~70%.
In 2018, Z. Zhang et. al. achieved state of the art on the UrbanSound8K dataset with a 77.4% prediction accuracy. They achieved this by doing 1D convolutions on Gammatone spectrograms. With data augmentation, that accuracy can be pushed higher yet. I did not have resources to explore data augmentation, so I am going to compare on non-augmented versions of the system.
In comparison, my approach was 7.4% less accurate. However, my technique works on 10 ms time frames (usually with some memory attached), meaning that the 70% accuracy covers a 10 ms moment at any given time of a sound in the dataset. This reduces the latency of the system by a factor of 300, making it well suited for realtime processing. Put simply, this approach was less accurate but introduced significantly less delay when processing.
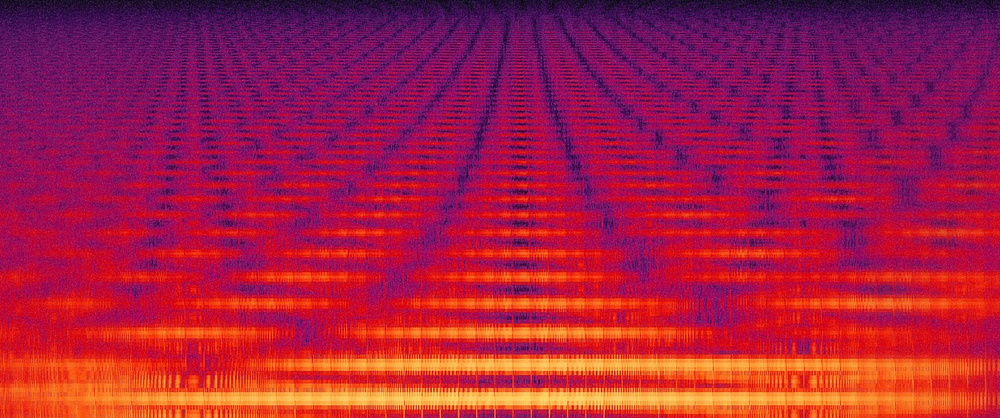
A “happy accident” I encountered during initial experiments.
Perspectives.
Working through this project has been very interesting indeed. I hope to have supplied you with some ideas for how you can work with sound in neural networks. Though I am happy with my initial results, I believe they can be significantly improved given a finer spectral resolution and computational resources for training the neural networks.
I hope that someone will pick this up and experiment with a listener-processor approach on new problems. In particular, I am curious to try a variational autoencoder approach to see what happens to reconstructed sounds when their latent spaces are adjusted — Maybe this can reveal some intuitions about what makes the basic statistical features of sound itself.
Related work.
If you’re interested in sound representation using autoencoders, here are some projects that have inspired me and that I recommend looking into:
Audio Word2Vec
These folks worked on a similar approach for encoding speech using MFCC’s and Seq2Seq autoencoders. They found that the phonetic structures of speech can be adequately represented this way.
A Universal Musical Translation Network
This is very impressive and the closest I’ve seen to style transfer in sound yet. It came out from Facebook AI Research last year. By using a shared WaveNet encoder, they compressed a number of raw-sample musical sequences to a latent space, then decoded with separate WaveNet decoders for each desired output “style”.
Modeling Non-Linear Audio Effects with Neural Networks
Marco Martinez and Joshua Reiss successfully modeled non-linear audio effects (like distortion) with neural networks. They achieved this by using 1D convolutions to encode raw-sample sequencies, transform these encodings (!) with a deep neural network, and then resynthesize these encodings back to raw samples with deconvolution.
....
Dear reader, thanks so much for coming on this journey with me. I feel privileged by the amount of positive, critical and informative response I’ve had to this article series.
Having been swamped with work, this final article has been a long time coming. Now that it’s wrapped up, I am looking forward to next chapters, new projects and ideas to explore.
I hope you’ve enjoyed it! If you would like to get in touch, please feel free to connect with me here and on LinkedIn.
音频相关文章的搬运工,如有侵权 请联系我们删除。
微博:砖瓦工-日记本
联系方式qq:1657250854
这篇关于Human-Like Machine Hearing With AI (3/3)--Results and perspectives.的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








