本文主要是介绍SRGAN 使用指南:将低分辨率图像转换为高分辨率图像,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SRGAN、ESRGAN、Real-ESRGAN 使用指南
- SRGAN
- 网络结构
- 优化目标
- ESRGAN
- Real-ESRGAN
SRGAN
超分辨率:从低分辨率(LR)图像来估计其对应高分辨率(HR)图像的任务,被称作超分辨率(SR)。
SRGAN 图像超分辨率的深度学习模型,通过生成对抗网络(GAN)的训练,将低分辨率图像转换为高分辨率图像。
SRGAN 项目代码:https://github.com/tensorlayer/srgan
网络结构
分为 2 部分:
- 生成器:残差模块(不改特征分辨率,图中的 B 个残差块)+ 上采样模块(提高分辨率,图中的反卷积层、重建层)
- 判别器:卷积层(通道数不断增加,通道数增加一倍,特征分辨率减一半)
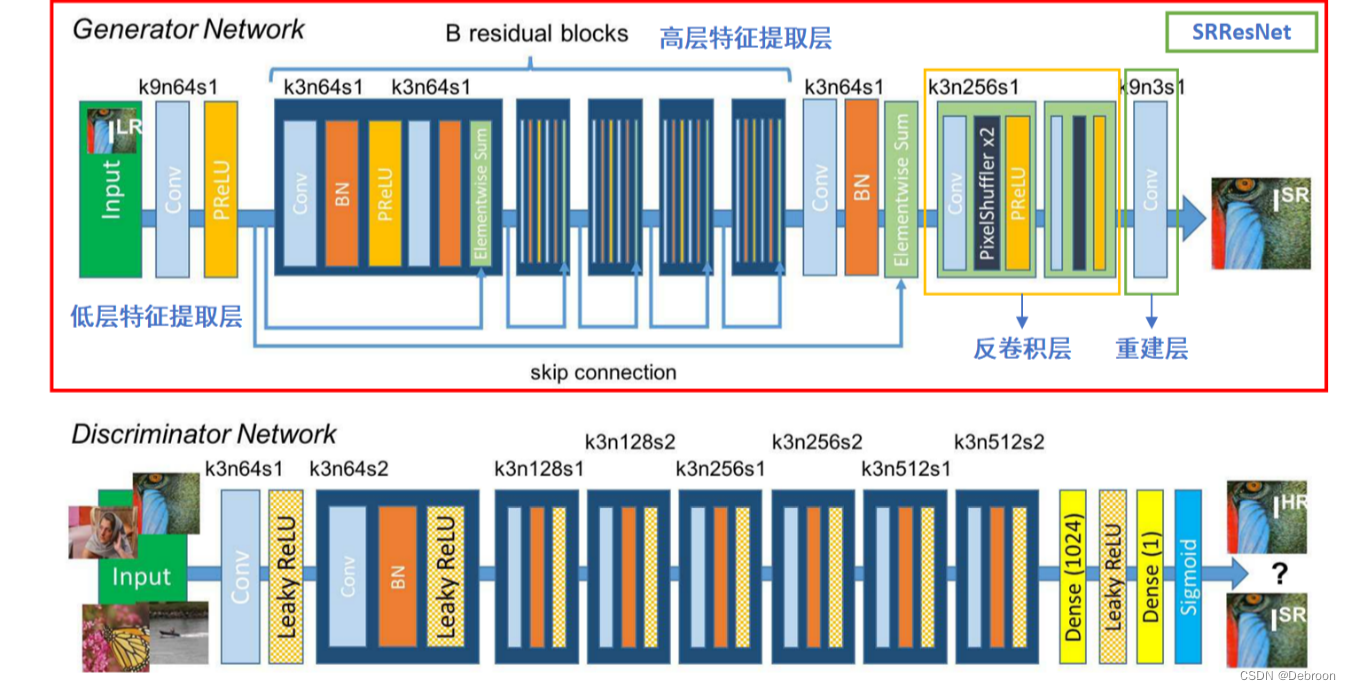
上采样模块是,亚像素卷积上采样模块,通过卷积和像素重排操作实现上采样,可以保持图像的细节信息。
不是普通的上采样层,通过插值算法实现上采样,简单但可能会导致图像的细节信息丢失。
优化目标
分为 3 部分:感知损失、内容损失、对抗损失。
-
感知损失 是基于感知质量评价指标(使用预训练的感知质量评价网络(如VGG网络)中的特征提取器来提取生成图像和真实图像的特征,并计算它们之间的欧氏距离)计算的。测量生成图像与真实高分辨率图像之间的感知差异。具体而言,通过计算生成图像和真实图像在特征空间中的距离,可以评估它们的相似性。感知损失帮助生成器学习到更接近真实图像的内容和结构。
-
内容损失 是基于均方误差(MSE)计算的。它测量生成图像与真实高分辨率图像之间的像素级差异。内容损失帮助生成器学习到更接近真实图像的细节和颜色。
-
对抗损失 是对抗性损失是通过判别器网络来评估生成图像的真实性,用于指导生成图像更逼真的外观和纹理。
感知损失:内容损失 + 对抗性损失 × 权重
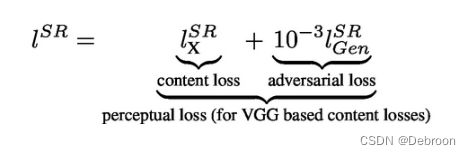
l S R l^{SR} lSR 和 l X S R l_{\mathbf{X}}^{SR} lXSR 是同一个损失函数 l 的不同形式或表示。
l S R l^{SR} lSR 是总体损失函数,包括了两个部分: l X S R l_{\mathbf{X}}^{SR} lXSR 和 1 0 − 3 l G e n S R 10^{-3}l_{Gen}^{SR} 10−3lGenSR。
- 表示生成器网络的整体损失,用于优化生成器网络的训练。
l X S R l_{\mathbf{X}}^{SR} lXSR 是生成图像与真实高分辨率图像之间的差异损失函数。
- 用于度量生成图像与真实图像之间的差异,并作为总体损失的一部分,目标是使生成图像尽可能接近真实高分辨率图像。
l X S R l_{\mathbf{X}}^{SR} lXSR 和 1 0 − 3 l G e n S R 10^{-3}l_{Gen}^{SR} 10−3lGenSR 是分别计算两个部分的损失函数,并根据一定的权重进行加权求和,得到总体损失函数 l S R l^{SR} lSR。
- 目的是平衡两个部分的重要性,使得生成器网络能够同时优化生成图像与真实图像之间的差异,并通过判别器网络的误分类来提高生成器的性能。
内容损失(基于VGG特征空间):将生成器得到ISR图像与IHR图像输入VGG-19网络,对每一层的特征映射计算欧式距离。
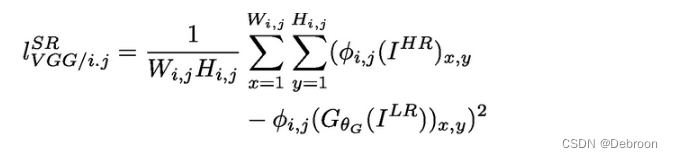
对抗损失:通过添加Gan生成网络损失,鼓励网络欺骗鉴别器。
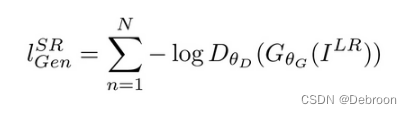
ESRGAN
Real-ESRGAN
这篇关于SRGAN 使用指南:将低分辨率图像转换为高分辨率图像的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





