本文主要是介绍yolov8-seg 分割推理流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、分割+检测
二、图像预处理
二、推理
三、后处理与可视化
3.1、后处理
3.2、mask可视化
四、完整pytorch代码
一、分割+检测
注:本篇只是阐述推理流程,tensorrt实现后续跟进。
yolov8-pose的tensorrt部署代码稍后更新,还是在仓库:GitHub - FeiYull/TensorRT-Alpha: 🔥🔥🔥TensorRT-Alpha supports YOLOv8、YOLOv7、YOLOv6、YOLOv5、YOLOv4、v3、YOLOX、YOLOR...🚀🚀🚀CUDA IS ALL YOU NEED.🍎🍎🍎It also supports end2end CUDA C acceleration and multi-batch inference.
也可以关注:TensorRT系列教程-CSDN博客
以下是官方预测代码:
from ultralytics import YOLO
model = YOLO(model='yolov8n-pose.pt')
model.predict(source="d:/Data/1.jpg", save=True)推理过程无非是:图像预处理 -> 推理 -> 后处理 + 可视化,这三个关键步骤在文件大概247行:D:\CodePython\ultralytics\ultralytics\engine\predictor.py,代码如下:
# Preprocess
with profilers[0]:im = self.preprocess(im0s) # 图像预处理# Inference
with profilers[1]:preds = self.inference(im, *args, **kwargs) # 推理# Postprocess
with profilers[2]:self.results = self.postprocess(preds, im, im0s) # 后处理二、图像预处理
通过debug,进入上述self.preprocess函数,看到代码实现如下。处理流程大概是:padding(满足矩形推理),图像通道转换,即:BGR装RGB,检查图像数据是否连续,存储顺序有HWC转为CHW,然后归一化。需要注意,原始pytorch框架图像预处理的时候,会将图像缩放+padding为HxW的图像,其中H、W为32倍数,而导出tensorrt的时候,为了高效推理,H、W 固定为640x640。
def preprocess(self, im):"""Prepares input image before inference.Args:im (torch.Tensor | List(np.ndarray)): BCHW for tensor, [(HWC) x B] for list."""not_tensor = not isinstance(im, torch.Tensor)if not_tensor:im = np.stack(self.pre_transform(im))im = im[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW, (n, 3, h, w)im = np.ascontiguousarray(im) # contiguousim = torch.from_numpy(im)img = im.to(self.device)img = img.half() if self.model.fp16 else img.float() # uint8 to fp16/32if not_tensor:img /= 255 # 0 - 255 to 0.0 - 1.0return img二、推理
图像预处理之后,直接推理就行了,这里是基于pytorch推理。
def inference(self, im, *args, **kwargs):visualize = increment_path(self.save_dir / Path(self.batch[0][0]).stem,mkdir=True) if self.args.visualize and (not self.source_type.tensor) else Falsereturn self.model(im, augment=self.args.augment, visualize=visualize)三、后处理与可视化
3.1、后处理
640x640输入之后,有两个输出,其中
- output1:尺寸为:116X8400,其中116=4+80+32,32为seg部分特征,经过NMS之后,输出为:N*38,其中38=4 + 2 + 32
- output2:尺寸为32x160x160,拿上面NMS后的特征图后面,即:N*38矩阵后面部分N*32的特征图和output2作矩阵乘法,得到N*160*160的矩阵,接着执行sigmiod,然后拉平得到N*160*160 的mask。
然后将bbox缩放160*160的坐标系,如下代码,用于截断越界的mask,就是如下函数。最后,将所有mask上采样到640*640,然后用阀值0.5过一下。最后mask中只有0和1了,结束。
有关def crop_mask(masks, boxes):的理解:
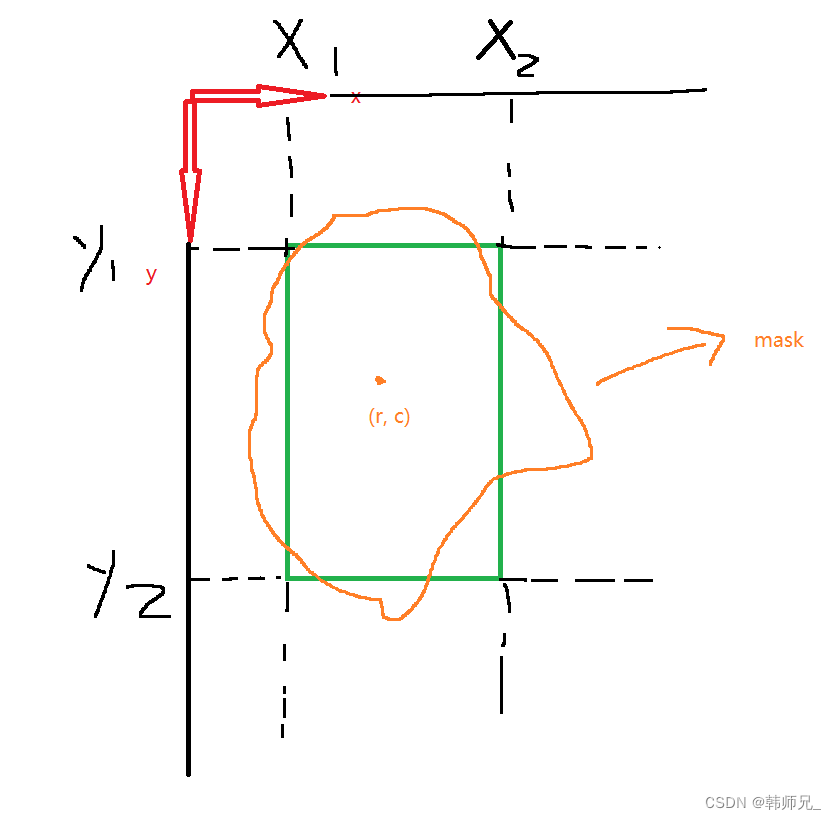
def crop_mask(masks, boxes):"""It takes a mask and a bounding box, and returns a mask that is cropped to the bounding boxArgs:masks (torch.Tensor): [n, h, w] tensor of masksboxes (torch.Tensor): [n, 4] tensor of bbox coordinates in relative point formReturns:(torch.Tensor): The masks are being cropped to the bounding box."""n, h, w = masks.shapex1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(n,1,1)r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,1,w)c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(1,h,1)return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))上面代码最后一句return,如下图理解,mask中所有点,例如点(r,c)必须在bbox内部。做法就是将bbox缩放到和mask一样的坐标系(160x160)如下图,然后使用绿色的bbox将mask进行截断:
3.2、mask可视化
直接将mask从灰度图转为彩色图,然后将类别对应的颜色乘以0.4,最后加在彩色图上就行了。
四、完整pytorch代码
将以上流程合并起来,并加以修改,完整代码如下:
import torch
import cv2 as cv
import numpy as np
from ultralytics.data.augment import LetterBox
from ultralytics.utils import ops
from ultralytics.engine.results import Results
import copy# path = 'd:/Data/1.jpg'
path = 'd:/Data/640640.jpg'
device = 'cuda:0'
conf = 0.25
iou = 0.7# preprocess
im = cv.imread(path)
# letterbox
im = [im]
orig_imgs = copy.deepcopy(im)
im = [LetterBox([640, 640], auto=True, stride=32)(image=x) for x in im]
im = im[0][None] # im = np.stack(im)
im = im[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW, (n, 3, h, w)
im = np.ascontiguousarray(im) # contiguous
im = torch.from_numpy(im)
img = im.to(device)
img = img.float()
img /= 255
# load model pt
ckpt = torch.load('yolov8n-seg.pt', map_location='cpu')
model = ckpt['model'].to(device).float() # FP32 model
model.eval()# inference
preds = model(img)# poseprocess
p = ops.non_max_suppression(preds[0], conf, iou, agnostic=False, max_det=300, nc=80, classes=None)
results = []
# 如果导出onnx,第二个输出维度是1,应该就是mask,需要后续上采样
proto = preds[1][-1] if len(preds[1]) == 3 else preds[1] # second output is len 3 if pt, but only 1 if exported???????
for i, pred in enumerate(p):orig_img = orig_imgs[i]if not len(pred): # save empty boxesresults.append(Results(orig_img=orig_img, path=path, names=model.names, boxes=pred[:, :6]))continuemasks = ops.process_mask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:], upsample=True) # HWCif not isinstance(orig_imgs, torch.Tensor):pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)results.append(Results(orig_img=orig_img, path=path, names=model.names, boxes=pred[:, :6], masks=masks))# show
plot_args = {'line_width': None,'boxes': True,'conf': True, 'labels': True}
plot_args['im_gpu'] = img[0]
result = results[0]
plotted_img = result.plot(**plot_args)
cv.imshow('plotted_img', plotted_img)
cv.waitKey(0)
cv.destroyAllWindows()
这篇关于yolov8-seg 分割推理流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






