本文主要是介绍HBase-6.hbase 协处理器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引入Hbase中的Coprocessor的原因
HBase作为列族数据库无法建立“二级索引”,难以执行求和、计数、排序等操作。为解决这些问题,HBase0.92 之后引入协处理器(Coprocessor),实现一些新特性,能够轻易建立二次索引、复杂过滤器、以及访问控制。
参考: http://blog.csdn.net/lifuxiangcaohui/article/details/39991183
协处理器两个插件
(1)观察者(observer)
提供三种观察者接口:
RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan等。
WALObserver:提供WAL相关操作钩子。
MasterObserver:提供DDL-类型的操作钩子。如创建、删除、修改数据表等。
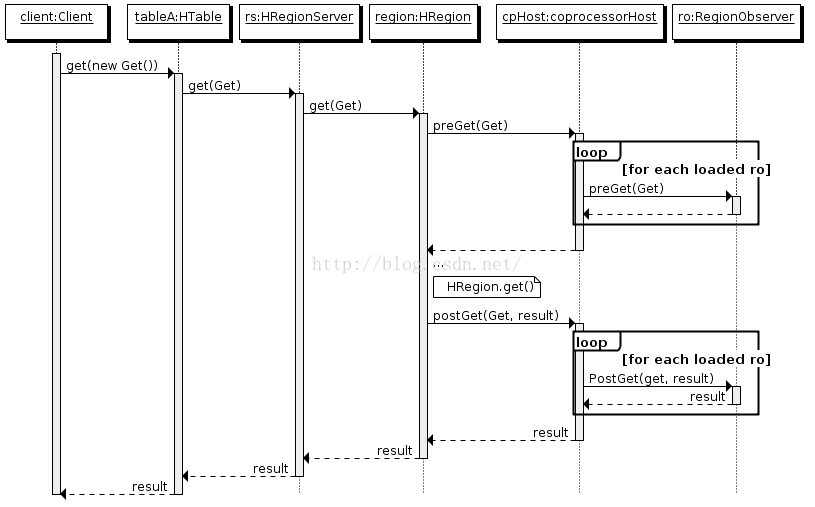
(2)终端(endpoint)
EndPoint协处理器
(1)ObServer协处理器:允许集群在正常的客户端操作过程中可以有不同的行表现!
(2)EndPoint协处理器:允许你扩展集群能力,对客户端应用开放新的运行命令,在RegionServer上执行
HBase的协处理器(coprocessor)统计函数
(1)在使用HBase的协处理器(coprocessor)之前,需要启动协处理器,有两种方案。
方案1:启动全局aggregation,能过操纵所有的表上的数据。通过修改hbase-site.xml这个文件来实现
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>
方案2:启用表aggregation,只对特定的表生效。通过HBase Shell 来实现
create 'stu', {NAME => 'info', VERSIONS => 5}
1、disable指定表。
hbase> disable 'stu'
2、添加aggregation
hbase>alter 'stu', METHOD => 'table_att','coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.AggregateImplementation||'
3、重启指定表
hbase> enable 'stu'
(2) JAVA代码统计表中列族的行数
public class MyAggregationClient {
public static void main(String[] args) throws Throwable {
Configuration customConf = new Configuration();
customConf.set("hbase.rootdir", "hdfs://mycluster:8020/hbase");
customConf.setStrings("hbase.zookeeper.quorum", "mycluster:2181");
// 提高RPC通信时长
customConf.setLong("hbase.rpc.timeout", 600000);
// 设置Scan缓存
customConf.setLong("hbase.client.scanner.caching", 1000);
// 默认为9000毫秒
customConf.set("zookeeper.session.timeout", "180000");
Configuration configuration = HBaseConfiguration.create(customConf);
AggregationClient aggregationClient = new AggregationClient(configuration);
Scan scan = new Scan();
// 指定扫描列族,唯一值
scan.addFamily(Bytes.toBytes("info"));
long rowCount = aggregationClient.rowCount(TableName.valueOf("stu"),new LongColumnInterpreter(), scan);
System.out.println("row count is " + rowCount);
}
}
HBase的协处理器案例
协处理器其中的一个作用是使用Observer创建二级索引,一般来说,对数据库建立索引,往往需要单独的数据结构来存储索引的数据。在为hbase建立索引时,可以另外建立一张索引表,查询时先查询索引表,然后用查询结果查询数据表.。
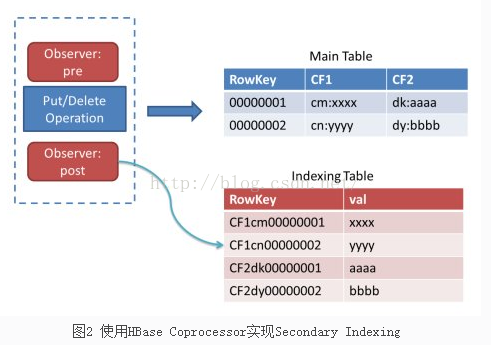
所以为了解决这个问题,hbase项目应运而生,它的主要思想是在region级别建立索引而不是在表级别。
参考: http://www.oschina.net/question/12_32573
这篇关于HBase-6.hbase 协处理器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





