本文主要是介绍李宏毅机器学习笔记第10周_鱼与熊掌可以兼得的深度学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、鱼与熊掌可以兼得
- 二、Why Hidden Layer?
- 1.Piecewise Linear
- 2.Hard Sigmoid -> ReLU
- 三、Deeper is Better?
- 四、Fat + Short v.s. Thin + Tall
- 五、Why we need deep?
- 六、Analogy – Logic Circuits
- 七、Analogy – Programming
- 八、More Analogy
- 九、Deep Network
- 总结
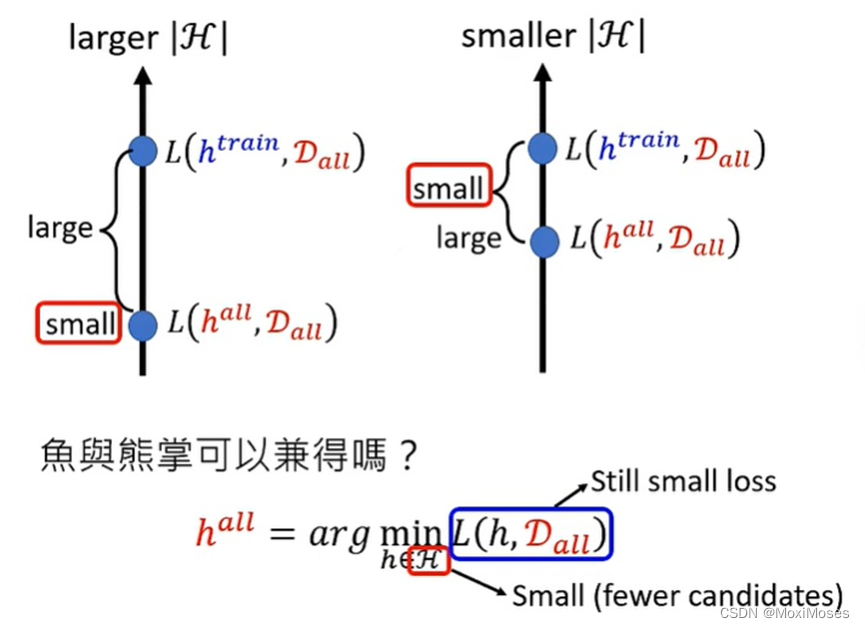
一、鱼与熊掌可以兼得
如下图所示,当有较大H的时候,我们得到的理想情况是比较小的,但是理想与现实相差较大;当有较小H的时候,虽然理想与现实相差较小,但是理想情况的结果比较大;那么要想做到鱼与熊掌兼得,就要既让loss小,又要让H也很小。
二、Why Hidden Layer?
1.Piecewise Linear
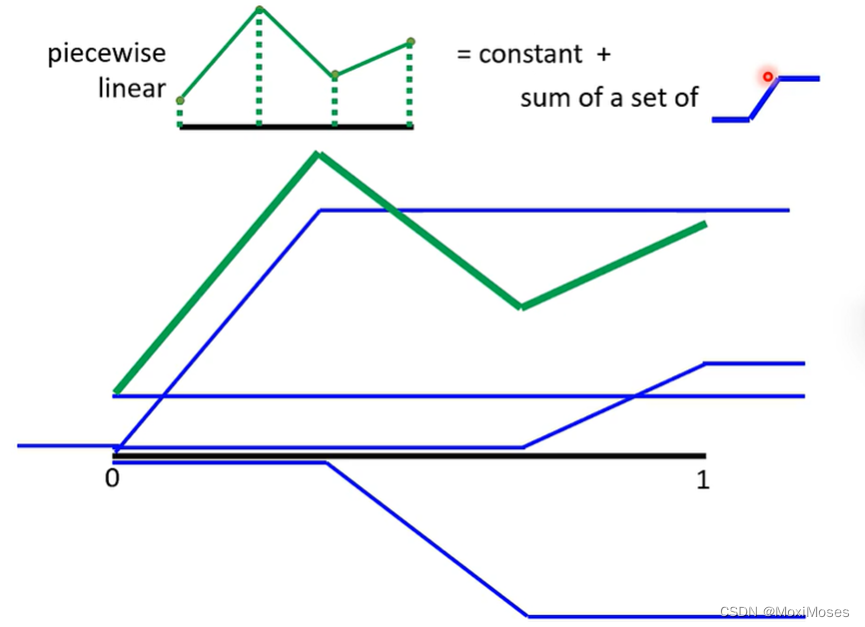
1)我们可以通过一个Hidden Layer就可以制造出所有可能的Function。如下图所示,现在我们要找一个Function,用Network去产生图中的线。我们将图中的线分成几等分,然后将端点连接起来得到Piecewise Linear。从图中我们可以发现如果绿色的线段足够多,就可以让绿色的线和黑色的线越来越接近。

2)如下图所示,通过观察发现,绿色的线可以看作常数项加上一堆蓝色的Function。
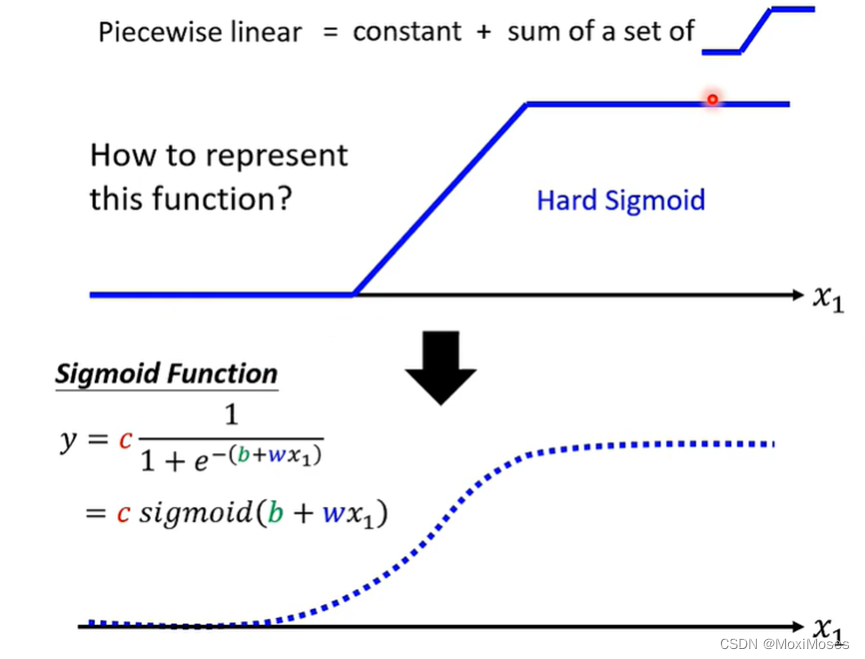
3)如下图所示,我们可以使用Sigmoid Function近似地表示蓝色阶梯形的线(Hard Sigmoid)。
4)如下图所示,每一个neuron都可以制造出蓝色阶梯形的线,然后把它们加起来,再加上常数项,就可以产生Piecewise Linear。
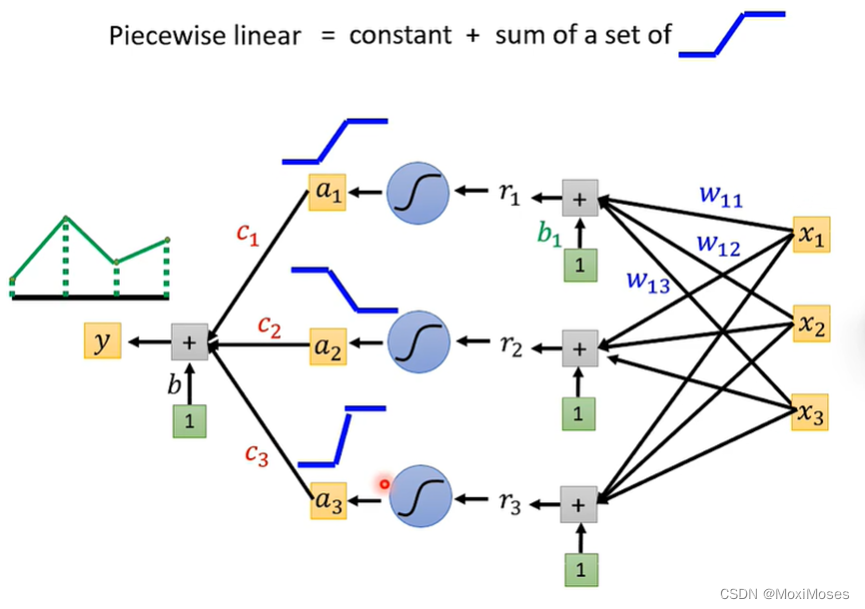
我们只要有足够多的neuron,我们就可以产生其它任何的Function。
2.Hard Sigmoid -> ReLU
1)Hard Sigmoid Function可以由两个ReLU Function所组成,ReLU Function如下图所示。
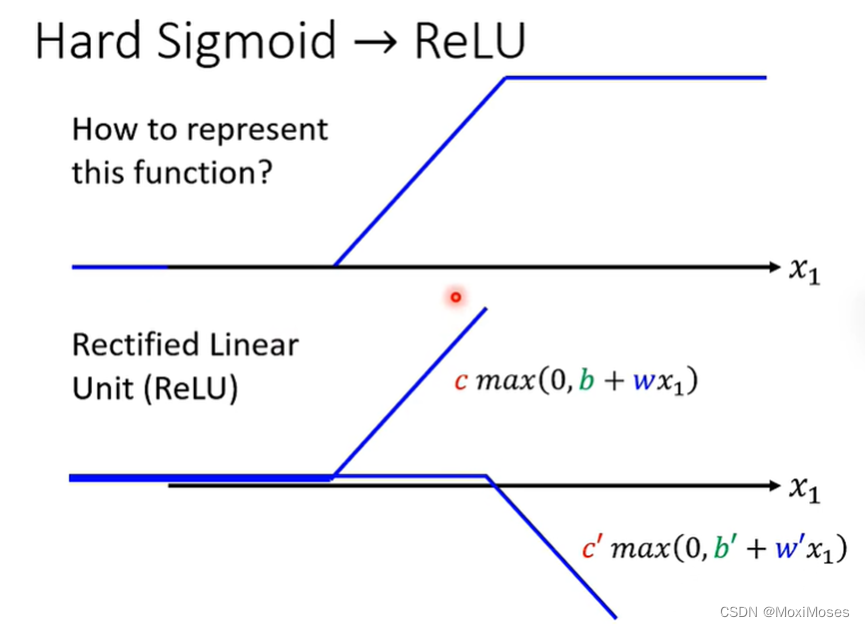
2)如下图所示,假设Network里面的neuron都是ReLU。只要有足够多的ReLU,把它们组合起来,就可以变成Piecewise Linear,这个Piecewise Linear可以逼近任何的Function。

三、Deeper is Better?
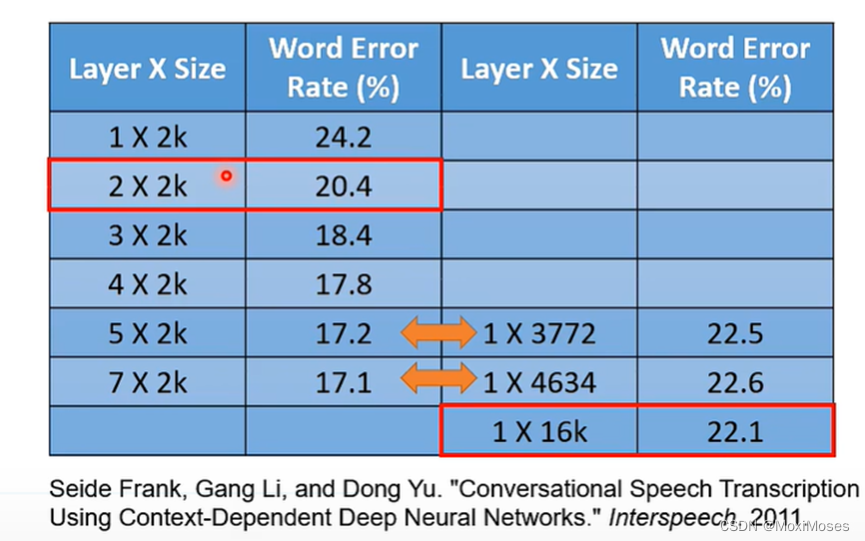
如下图所示,这里是对语音辨识性能的研究。我们可以发现Network越深,错误率越低。当我们把Network越叠越深时,H就会越来越大,理想的Loss会越来越低,就算有足够多的资料量,理想与现实也不会差太多。

深度学习不仅需要大模型,也需要大量的训练资料。如果没有大量的训练资料,就会出现overfitting。
四、Fat + Short v.s. Thin + Tall
1. 如下图所示,我们可以让模型横向发展,也就是把模型变胖,这样也可以制造很大的模型。现在我们让Shallow Network和Deep Network有一样的参数,看谁的表现更好?
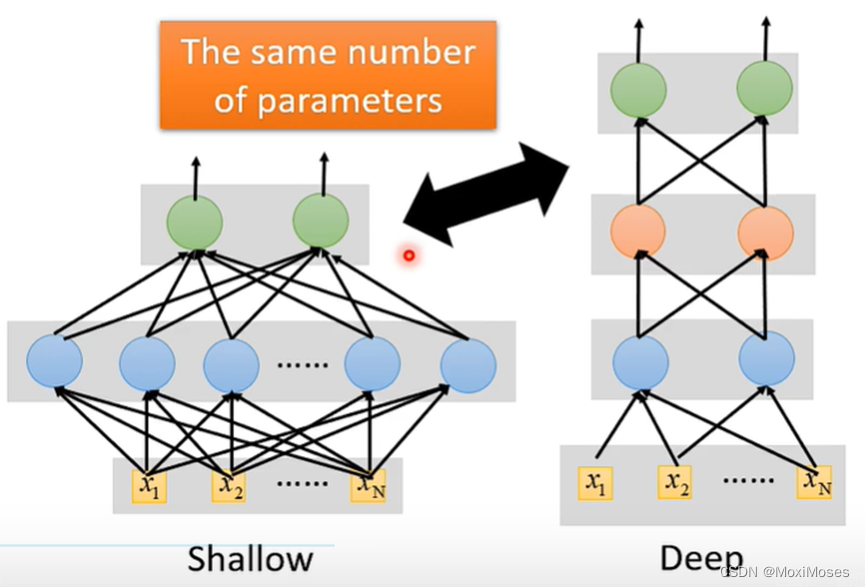
2. 如下图所示,当参数量相同时,Deep Network比Shallow Network的表现更好,错误率更低。
五、Why we need deep?
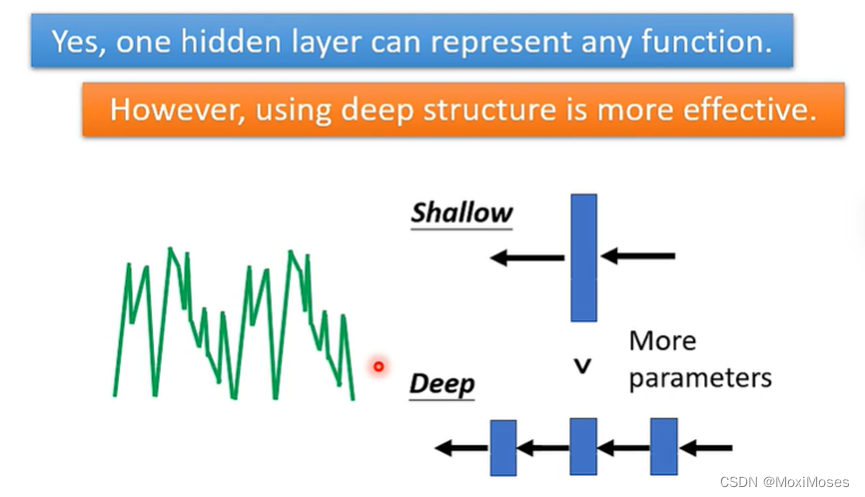
当表示某一个Function时,使用Deep的架构更加有效率,因为Deep使用的参数比Shallow使用的参数少。
六、Analogy – Logic Circuits
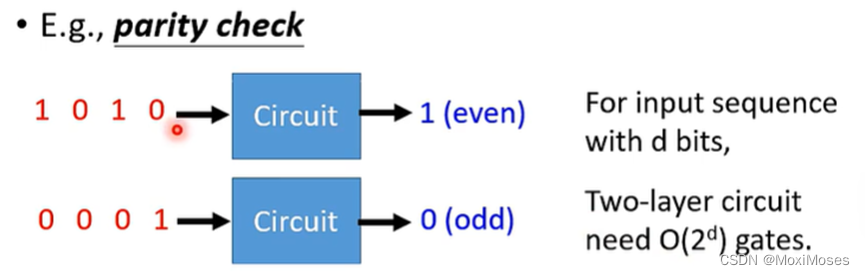
1. Parity check
输入是由01组成的串,如果这个串中1出现的次数是奇数,就输出0;反之,就输出1。
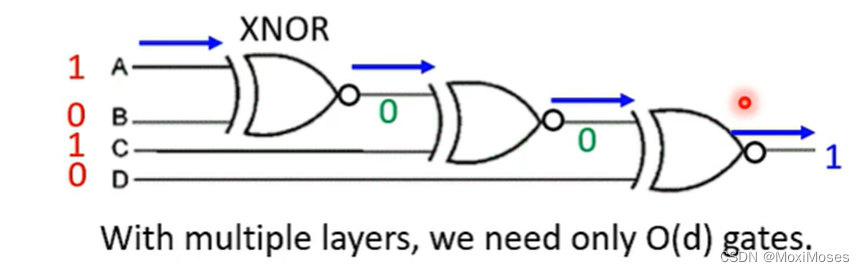
2. 把XNOR排成Deep结构时,当输入的数字相同时,就输出1;反之,就输出0。
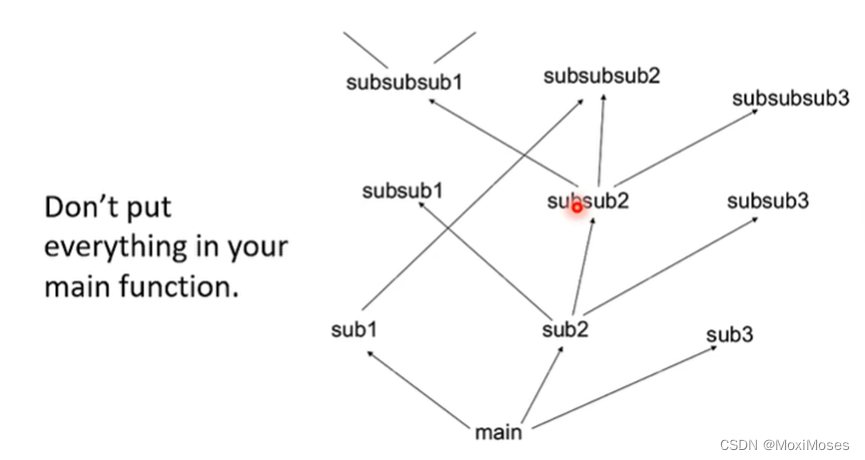
七、Analogy – Programming
模块化编程的设计思想是把程序要实现的功能分模块,分别写成函数,这样就可以增加复用性,提高开发效率。
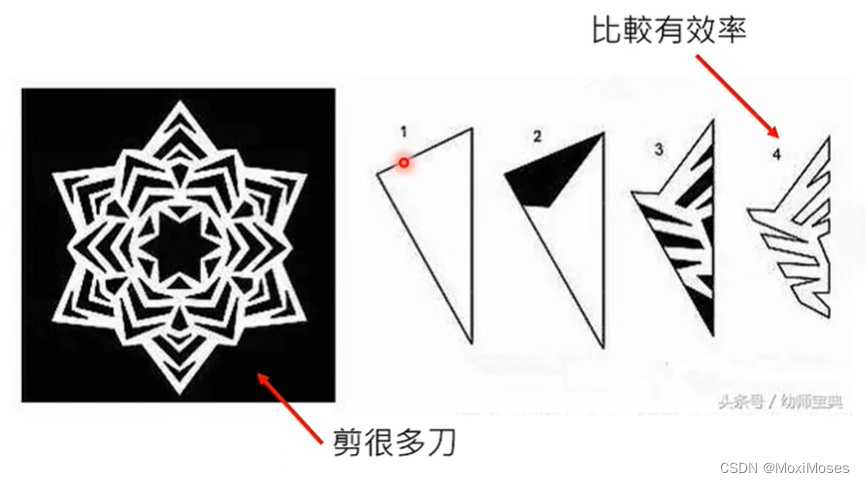
八、More Analogy
在剪窗花过程中,把纸对折多次后剪比不对折纸剪要更快、更有效率。
九、Deep Network
1. 如下图所示,一层结构,两层神经元,激活函数用ReLU,输出a1后,得到x与a1的关系。
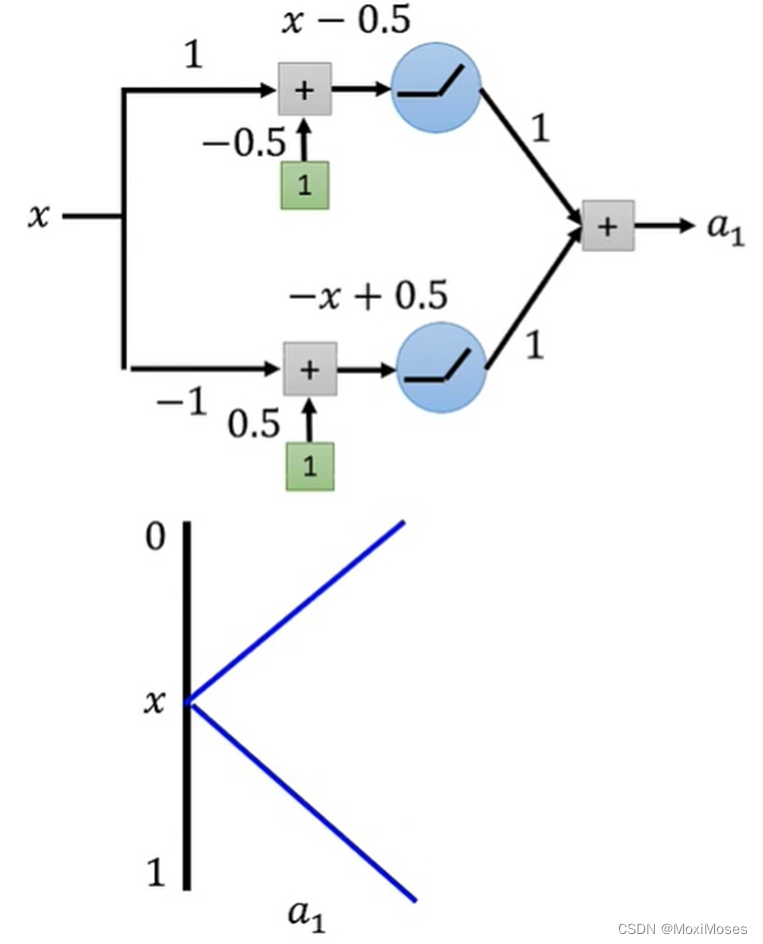
2. 如下图所示,两层结构,因为第二层的Hidden Layer与第一层的Hidden Layer结构一样,所以a2与a1的关系跟a1与x的关系一样。因此得到a2与x的关系。
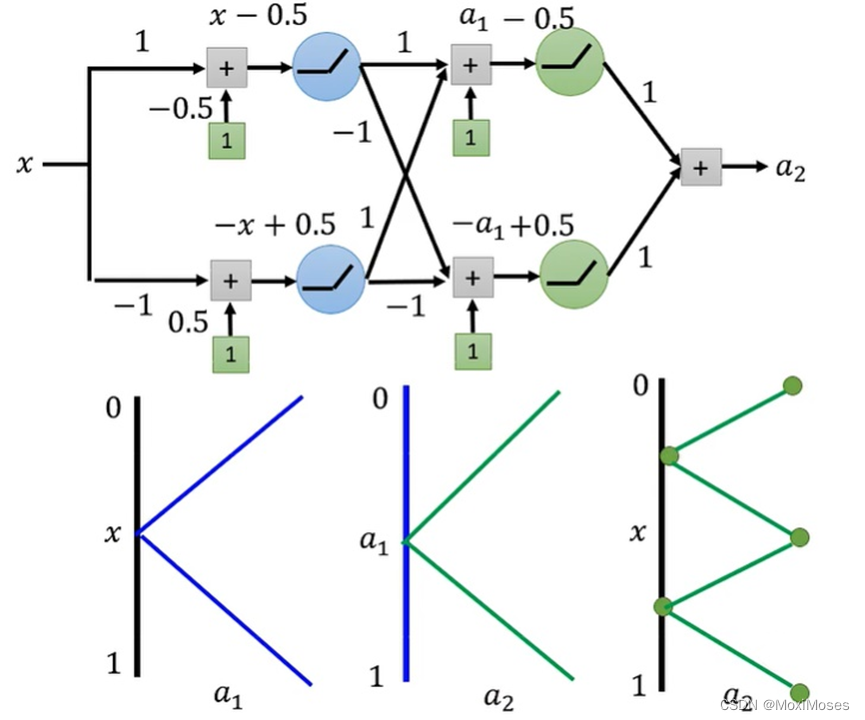
3. 如下图所示,三层结构,与上面情况相似,因此可以得到a3与x的关系。
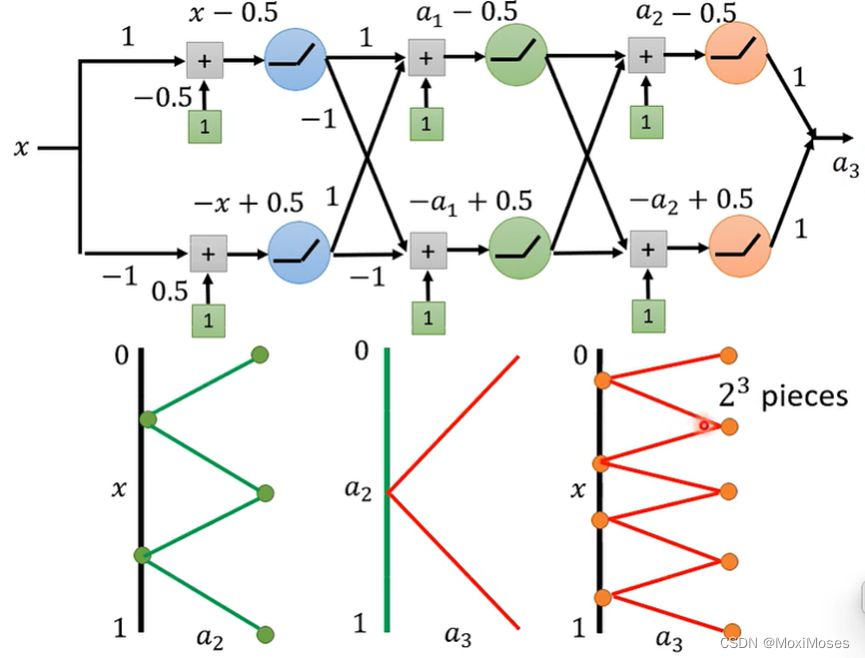
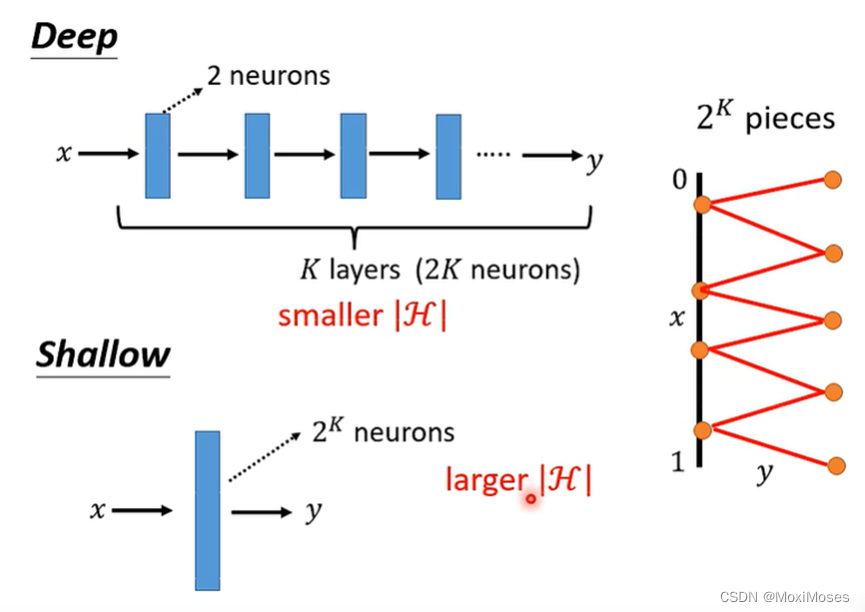
4. 如下图所示,通过上述结果可以得到,假如我们想要得到2^k个折线段的函数,只需要Deep Network有k层,每层有2个神经元;Shallow Network只有1层,需要2^k个神经元。因此,Deep Network参数量比较小,需要比较简单的模型;Shallow Network参数量比较大,需要比较复杂的模型,然而复杂的模型容易overfitting,所有需要大量的训练资料。
总结
当我们需要的Function(让Loss很低)是复杂和有规律的(image,speech),Deep Network比Shallow Network表现得更好。
在函数是y=x^2的情况下,Deep Network也比Shallow Network表现得更好。
这篇关于李宏毅机器学习笔记第10周_鱼与熊掌可以兼得的深度学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



