本文主要是介绍InnoDB——详解B+树索引的分裂原理与管理 B+树索引的分裂,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
B+树索引的分裂
上篇介绍的是B+树分裂的最为简单的一种情况,这和数据库中B+树索引的情况可能略有不同。
B+树索引页的分裂并不总是从页的中间记录开始,这样可能会导致页空间的浪费。
例子
比如下面这个记录:
1、2、3、4、5、6、7、8、9
由于插入是以自增的顺序进行的,若这时插入第10条记录然后进行页的分裂操作,那么根据上一节的方法,会将5作为分割点,得到下面两个页:
P1: 1、2、3、4
P2: 5、6、7、8、9、10
然而由于插入是顺序的,P1这个页中将不会再有记录插入,从而导致空间浪费。而P2又会再次进行分裂。
InnoDB存储引擎的Page Header中有以下几个部分用来保存插入的顺序信息:
- PAGE_LAST_INSERT: 最后插入记录的位置
- PAGE_DIRECTION: 最后插入的方向。可能的取值为PAGE_LEFT(0x01),PAGE_RIGHT(0x02), PAGE_SAME_REC(0x03),PAGE_SAME_PAGE(0x04),PAGE_NO_DIRECTION(0x05)。
- PAGE_N_DIRECTION: 一个方向连续插入记录的数量
通过这几个信息,InnoDB可以决定是向左还是向右进行分裂,同时决定将哪个作为分裂点。
- 若插入是随机的,则取页的中间记录作为分裂点,这和之前介绍的是相同的。
- 若往同一方向插入的记录数量(PAGE_N_DIRECTION)为5,并且目前已经定位(cursor)到的记录(InnoDB存储引擎插入时,首先需要进行定位,定位到的记录为待插入记录的前一条记录)之后还有3条记录,则分裂点的记录为定位到的记录后的第三条记录,否则分裂点记录就是待插入的记录。
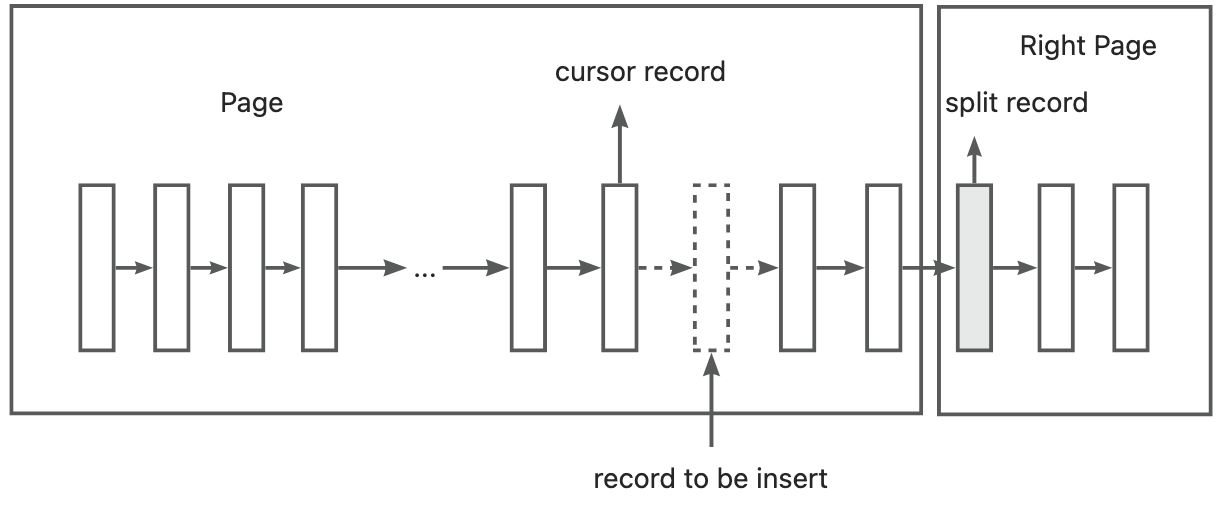
来看一个向右分裂的例子,并且定位到的记录之后还有3条记录,则分裂点记录如下图所示:

上图向右分裂且定位到的记录之后还有3条记录,split record为分裂点记录最终向右分裂的到如下图所示的情况:
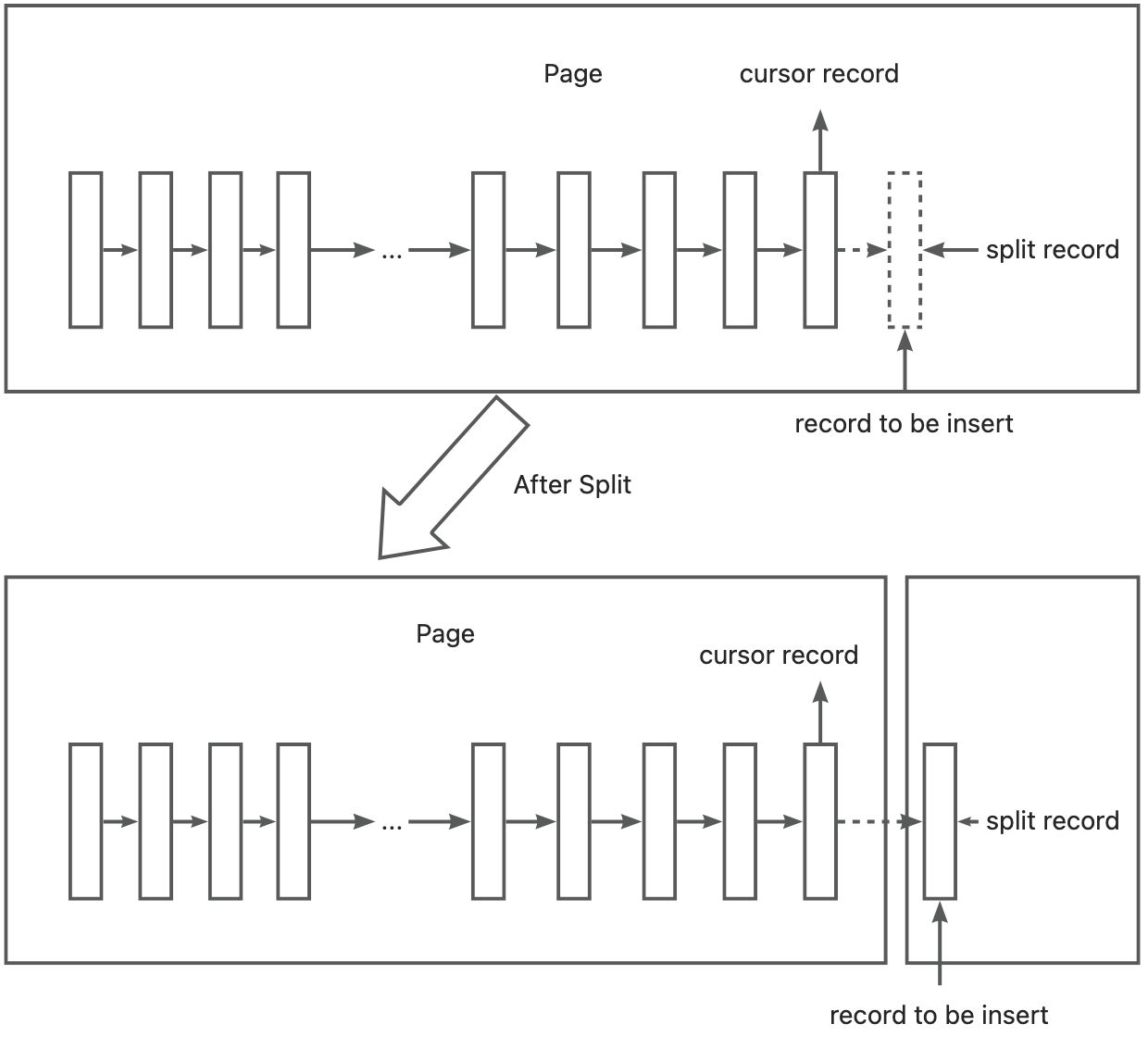
而对于下图,分裂点就是插入记录本身,向右分裂后仅插入记录本身,这在自增插入时是普遍存在的一种情况:
B+树索引的管理
索引管理
索引的创建和删除可以通过两种方法,一种是ALTER TABLE,另一种是CREATE/DROP INDEX。
通过ALTER TABLE创建索引的语法为:
ALTER TABLE tbl_name
| ADD {INDEX|KEY} [index_name]
[index_type] (index_col_name, ...) [index_option] ...ALTER TABLE tbl_name
DROP PRIMARY KEY
| DROP {INDEX|KEY} index_name
CREATE/DROP INDEX的语法同样很简单:
CREATE [UNIQUE] INDEX index_name
[index_type]
ON tbl_name (index_col_name, ...)Drop INDEX index_name ON tbl_name
索引列的部分数据
用户可以设置对整个列的数据进行索引,也可以只索引一个列的开头部分数据,如前面创建的表t,列b为varchar(8000),但是用户可以只索引前100个字段,如:
ALTER TABLE t ADD KEY idx_b (b(100));
若用户想要查看表中索引的信息,可以使用SHOW INDEX。下面的例子使用之前的表t,并加一个对于列(a,c)的联合索引 idx_a_c,可得:
ALTER TABLE t ADD KEY idx_a_c (a,c);
查看表中的索引信息:
SHOW INDEX FROM t\G;
通过命令SHOW INDEX FROM可以观察到表t上有4个索引,分别为主键索引、c列上的辅助索引、b列的前100字节构成的辅助索引,以及(a、c)的联合辅助索引。
具体看SHOW INDEX结果中每列的含义:
- TABLE:索引所在表名
- Non_unique:非唯一索引,可以看到primary key的值是0,因为primary key是唯一的。
- Key_name:索引的名字;Seq_in_index(联合索引中的位置);
- Column_name:索引列的名称;
- Collatioin:列以什么方式存储在索引中。可与是A或NULL。B+树索引总是A,即排序的。如果使用了Heap存储引擎,并且建立了Hash索引,这里就会显示NULL了。因为Hash根据Hash桶存放索引数据,而不是对数据进行排序。
- Cardinality:非常关键的值,表示索引中唯一值的数目的估计值。Cardinality表的行数应尽可能接近1,如果非常小,那么用户需要考虑是否可以删除次索引。
- Sub_part:是否列的部分被索引
- Packed:关键字如何被压缩。如果没有被压缩,则为NULL。
- Null:是否索引的列行有NULL值。
- Index_type:索引的类型,比如BTREE
- Comment:注释。
Cardinality
Cardinality值非常关键,优化器会根据这个值来判断是否使用这个索引。
但是这个值并不是实时更新的,即并非每次索引的更新都会更新该值,因为这样的代价太大了。因此这个值是不太准确的,只是一个大概的值。
如果需要更新索引Cardinality的信息,可以使用ANALYZE TABLE命令,如:
ANALYZ table t\G;
每个系统上可能得到的结果不一样,因为ANALYZE TABLE现在还存在一些问题,可能会影响最后得到的结果。
另一个问题是MYSQL数据库对于Cardinality计数的问题,在运行一段时间后,可能会看到Cardinality为NULL。
Cardinality为NULL,在某些情况下可能会发生索引建立了但却没有用到的情况。或者对两条基本一样的语句执行EXPLAIN,但是最终出来的结果不一样:一个使用索引,另一个使用全表扫描。
这时最好的解决办法的就是做一次ANALYZE TABLE,最好在非高峰期间做这个操作;
快速创建索引
在MySQL5.5版本之前(不包括5.5)存在的一个普遍被人诟病的问题是,MySQL数据库对于索引的的添加或者删除的这类DDL操作。MYSQL数据库ALTER TABLE的操作过程为:
- 首先创建一张新的临时表,表结构为通过命令ALTER TABLE新定义的结构。
- 然后把原表中数据导入到临时表。
- 接着删除原表。
- 最后把临时表重命名为原来的表名。
可以发现,若用户对于一张大表进行索引的添加和删除操作,那么会需要很长的时间。
更关键的是,若有大量事务需要访问正在被修改的表,这意味着数据库服务不可用。
而这对于Microsoft SQL Server或Oracle数据库的DBA来说,MySQL数据库的索引维护始终让他们感到非常痛苦。
辅助索引的创建与删除
InnoDB存储引擎从InnoDB 1.0X版本开始支持一种称为Fast Index Creation(快速索引创建)的索引创建方式——简称FIC。
- 对于辅助索引的创建,InnoDB存储引擎会对创建索引的表加上一个S锁。
在创建的过程中,不需要重建表,因此速度较之前提高很多,并且数据库的可用性也得到了提高。
- 删除辅助索引操作更简单些,InnoDB存储引擎值需要更新内部视图,并将辅助索引的空间标记为可用,同时删除MySQL数据库内部视图上对该表的索引定义即可。
这里需要特别注意的是,临时表的创建路径是通过参数tmpdir进行设置的。用户必须保证tmpdir有足够的空间可以存放临时表,否则会导致创建索引失败。
由于FIC在索引的创建过程中对表加上S锁,因此在创建的过程中只能对该表进行读操作,若有大量的事务需要对目标表进行写操作,那么数据库的服务同样不可用。
此外,FIC方式只限定于辅助索引,对于主键的创建和删除同样需要重建一张表。
在线架构改变(OSC)
Online Schema Change(OSC)最早是由Facebook实现的一种在线执行DDL的方式,并广泛地应用于Facebook的MySQL数据。
所谓的“在线”是指在事务的创建过程中,可以有读写事务对表进行操作,这提高了原有MySQL数据库在DDL操作时的并发性。
Facebook采用PHP脚本来实现OSC,而不是通过修改InnoDB源码的方式。实现OSC的步骤如下:
- init,初始化阶段,对创建表做一些验证工作:检查是否有主键,是否存在触发器或者外键等。
- createCopyTable,创建和原始表结构一样的新表。
- alterCopyTable:对创建的新表进行ALTER TABLE操作,如添加索引或列等。
- createDeltasTable,创建deltas表,该表的作用是为下一步创建的触发器所使用。
之后对原表的所有DML操作操作会被记录到createDeltasTable中。
- createTriggers,对原表创建INSERT、UPDATE、DELETE操作的触发器。触发操作产生的记录被写入到deltas表。
- startSnapshotXact,开始OSC操作的事务。
- selectTableIntoOutfile,将原表中的数据写入到新表。为了减少对原表的锁定时间,这里通过分片( chunked)将数据输出到多个外部文件,然后将外部文件的数据导入到copy表中。分片的大小可以指定,默认值是500000。
- dropNCIndexs,在导入到新表前,删除新表中所有的辅助索引。
- loadCopyTable,将导出的分片文件导入到新表。
- replayChanges,将OSC过程中原表DML操作的记录并应用到新表中,这些记录被保存在deltas表中。
- recreateNCIndexes,重新创建辅助索引。
- replayChanges,再次进行DML日志的回放操作,这些日志是在上述创建辅助索引过程中新产生的日志。
- swapTables,将原表和新表交换名字,整个操作需要锁定2张表,不允许新的数据产生。由于改名是一个很快的操作,因此阻塞的时间非常短。
上述只是简单介绍了OSC的实现过程,实际脚本非常复杂。同时OSC所做的操作不会同步slave服务器,可能导致主从不一致的情况。
在线DDL(Online DDL)
虽然FIC可以让InnoDB存储引擎避免创建临时表,从而提高索引创建的效率,但创建索引时会阻塞表上的DML操作。
OSC虽然解决了上述的部分问题,但还是有很大的局限性。
MySQL5.6版本开始支持Online DDL操作,其允许辅助索引创建的同时,还允许其他诸如INSERT、UPDATE、DELETE这类DML操作,这极大地提高了MySQL数据库在生产环境中的可用性。
此外,不仅是辅助索引,以下这几类DDL操作都可以通过“在线”的方式进行操作:
- 辅助索引的创建与删除
- 改变自增长值
- 添加或删除外键约束
- 列的重命名
通过新的ALTER TABLE语法,用户可以选择索引的创建方式:
ALTER TABLE tbl_name
| ADD {INDEX|KEY} [index_name]
[index_type] (index_col_name,...) [index_option] ...
ALGORITHM [=] {DEFAULT|INPLACE|COPY}
LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE}ALGORITHM指定了创建或删除索引的算法:
- COPY表示按照MySQL5.1版本之前的工作模式,即创建临时表的方式。
- INPLACE表示索引创建或删除操作不需要创建临时表。
- DEFAULT表示根据参数old_alter_table来判断是通过INPLACE还是COPY的算法。
LOCK部分为索引创建或删除时对表添加锁的情况,可有的选择为:
- NONE
执行索引创建或者删除操作时,对目标表不添加任何的所,即事务仍然可以进行读写操作,不会受到阻塞。因此这种模式可以获得最大的并发度。
- SHARE
这和之前的FIC类似,执行索引创建或删除操作时,对目标表加上一个S锁。对于兵法地读事务,依然可以执行,但是遇到写事务,就会发生等待操作。如果存储引擎不支持SHARE模式,会返回一个错误信息
- EXCLUSIVE
该模式下,执行索引创建或删除操作时,对目标表加上一个X锁。读写事务都不能进行,因此会阻塞所有的线程。和COPY的状态类似,但不需要像COPY方式那样创建一张临时表。
- DEFAULT
首先判断当前操作是否可以使用NONE模式,若不能则判断是否可以使用SHARE模式,最后判断是否可以使用EXCLUSIVE模式。
也就是说,DEFAULT会通过判断事物的最大并发来判断执行DDL的模式。
在线DDL的实现
原理是在执行创建或者删除操作的同时,将INSERT、UPDATE、DELETE这类DML操作日志写入到一个缓存中。等完成索引创建后再将重做应用到表上,以此达到数据的一致性。
这个缓存的大小由参数innodb_online_alter_log_max_size控制,默认的大小是128MB。
因此如果遇到类似如下的错误:
ErrOr: 1799SOLSTATE: HI000 (ER INNODB_ONLINE_ LOG _TOO_ BIG)
Message: Creating index 'id_aaa' required more than 'innodb_online_alter 109_ max size' bytes of modification log.
Please try again.
对于这个错误,用户可以调大参数 innodb online alter_log_ max_size,以此获得更大的日志缓存空间。此外,还可以设置 ALTER TABLE 的模式为 SHARE,这样在执行过程中不会有写事务发生,因此不需要进行 DML 日志的记录。
需要特别注意的是,由于 Online DDL 在创建索引完成后再通过重做日志达到数据库的最终一致性,这意味着在索引创建过程中,SQL 优化器不会选择正在创建中的索引。
后续会仔细介绍一下Cardinality值
这篇关于InnoDB——详解B+树索引的分裂原理与管理 B+树索引的分裂的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






