本文主要是介绍Linux python安装 虚拟环境 virtualenv,以及 git clone的 文件数据, 以及 下资源配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

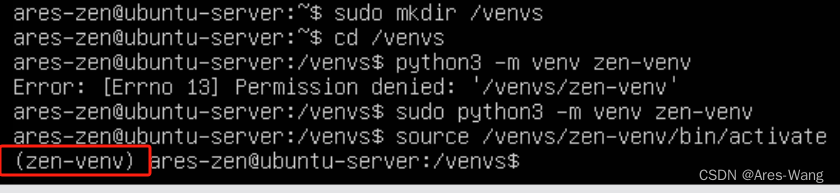
根目录创建 venvs 文件夹
sudo mkdir /venvs
进入 /venvs 目录
cd /venvsp
创建虚拟环境,前提要按照 python3
安装 的 命令 sudo apt install python3
sudo python3 -m venv 虚拟环境名
激活虚拟环境
source /venvs/zen-venv/bin/activate
安装flask
pip install flask
在虚拟环境中运行flask项目 这个效率不高
激活要用什么环境运行项目
source /venvs/zen-venv/bin/activate
进入指定的项目位置
cd /data/www/zen001
运行项目
python app.py
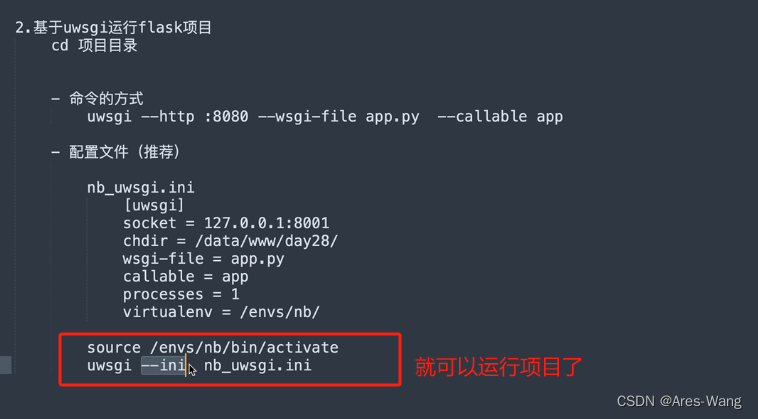
基于uwsgi 运行flask项目 运行静态资源 效率不高
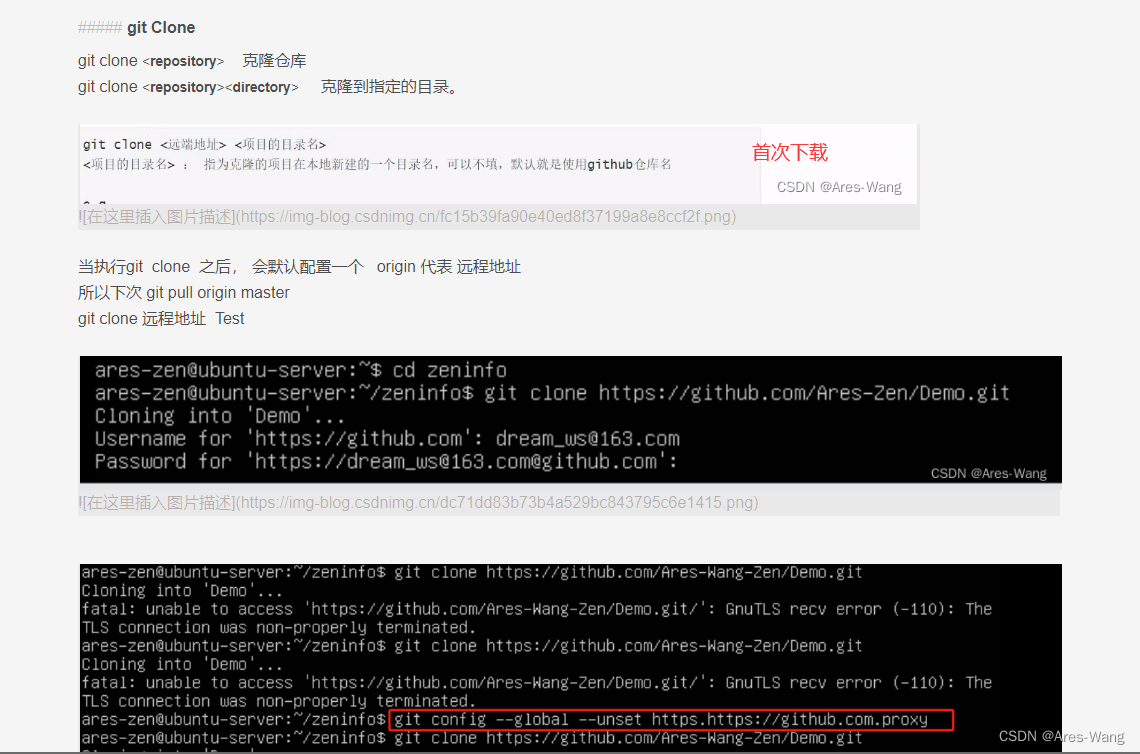
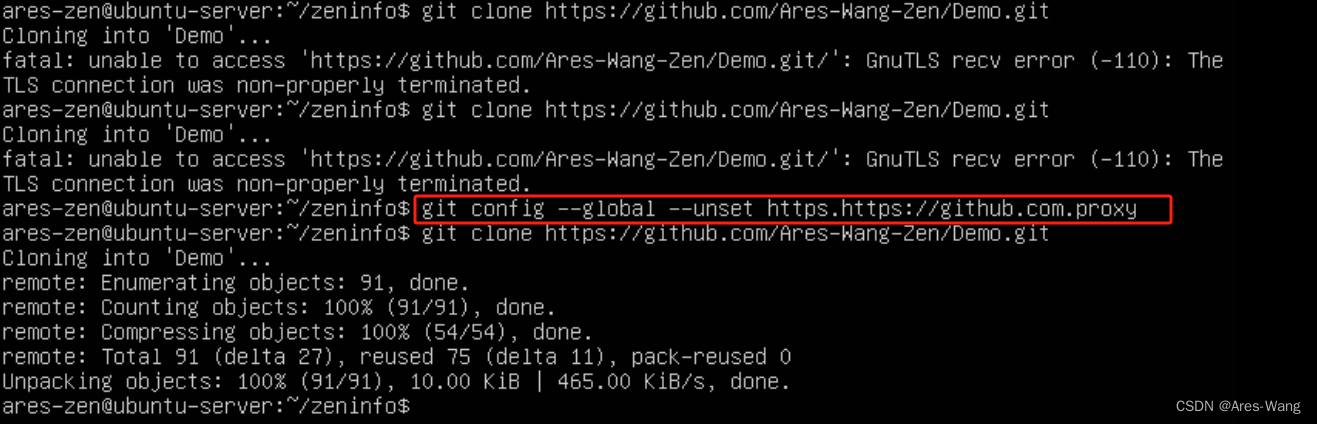
把github上的文件克隆到文件夹中
进入指定目录
cd /xxx
创建存放项目的文件夹
mkdir zeninfo
进入这个目录
git clone 远程git地址

下资源配置
进入加目录
cd ~
创建文件夹 .pip 有个. 代表是隐藏文件夹
sudo mkdir .pip
进入这个文件夹
cd .pip
创建 pip.conf 文件
sudo touch pip.conf
编辑
sudo vim pip.conf
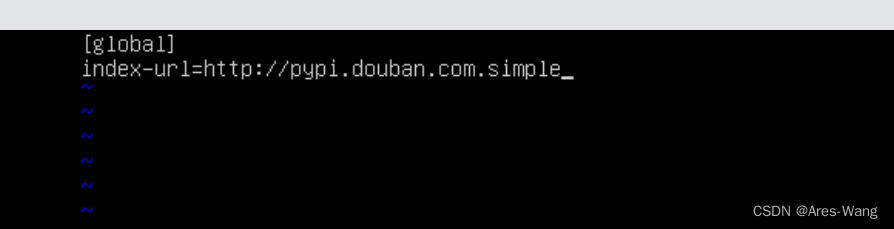
编辑的内容
[global]
index-url = http://pypi.douban.com/simple
[install]
use-mirrors =true
mirrors =http://pypi.douban.com/simple/
trusted-host =pypi.douban.com

默认是不被信任的
可以在安装时
pip install uwsgi --trusted-host pypi.douban.com.simple
或者


这篇关于Linux python安装 虚拟环境 virtualenv,以及 git clone的 文件数据, 以及 下资源配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








