本文主要是介绍学习dangdang的分库分表扩展框架sharding-jdbc(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当当开源的sharding-jdbc,官方网址:https://github.com/dangdangdotcom/sharding-jdbc
一、简介

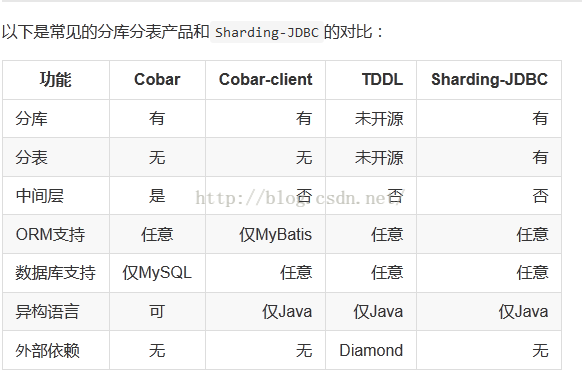
好了,看了这么多的介绍,感觉还是很高大上的,注意点有:
①对JDBC API进行了原生态的分装,这是与cobar-client不一样的地方,这就是他可以支持多个第三方ORM框架的关键
②可支持=,BETWEEN,IN等操作,说明,JDBC返回结果后,sharding进行了合并操作,这里面肯定会有性能损耗
③支持分表,这也是cobar-client不支持的地方
好了,先简单的按照官方网址的demo实践一发:
先在MySQL中建2个库

分别在这2个库中运行:

ShardingJdbc
ModuloDatabaseShardingAlgorithm
好了,按照官方教程说明:

我们现在user_id是10,order_id是1001
我们应该在sharding0库中的t_order_1和t_order_item_1中新建数据:
好了,准备工作做完了,我们运行main函数,运行结果为:

好了,sharding-jdbc正常工作了
一、简介
好了,看了这么多的介绍,感觉还是很高大上的,注意点有:
①对JDBC API进行了原生态的分装,这是与cobar-client不一样的地方,这就是他可以支持多个第三方ORM框架的关键
②可支持=,BETWEEN,IN等操作,说明,JDBC返回结果后,sharding进行了合并操作,这里面肯定会有性能损耗
③支持分表,这也是cobar-client不支持的地方
好了,先简单的按照官方网址的demo实践一发:
先在MySQL中建2个库
分别在这2个库中运行:
CREATE TABLE IF NOT EXISTS `t_order_0` ( `order_id` INT NOT NULL, `user_id` INT NOT NULL, PRIMARY KEY (`order_id`) ); CREATE TABLE IF NOT EXISTS `t_order_item_0` ( `item_id` INT NOT NULL, `order_id` INT NOT NULL, `user_id` INT NOT NULL, PRIMARY KEY (`item_id`) ); CREATE TABLE IF NOT EXISTS `t_order_1` ( `order_id` INT NOT NULL, `user_id` INT NOT NULL, PRIMARY KEY (`order_id`) ); CREATE TABLE IF NOT EXISTS `t_order_item_1` ( `item_id` INT NOT NULL, `order_id` INT NOT NULL, `user_id` INT NOT NULL, PRIMARY KEY (`item_id`) );
ShardingJdbc
package com.study.base;import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;import javax.sql.DataSource;import org.apache.commons.dbcp.BasicDataSource;import com.dangdang.ddframe.rdb.sharding.api.ShardingDataSource;
import com.dangdang.ddframe.rdb.sharding.api.rule.BindingTableRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.TableRule;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.DatabaseShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy;public class ShardingJdbc {public static void main(String[] args) throws SQLException {//数据源Map<String, DataSource> dataSourceMap = new HashMap<>(2);dataSourceMap.put("sharding_0", createDataSource("sharding_0"));dataSourceMap.put("sharding_1", createDataSource("sharding_1"));DataSourceRule dataSourceRule = new DataSourceRule(dataSourceMap);//分表分库的表,第一个参数是逻辑表名,第二个是实际表名,第三个是实际库TableRule orderTableRule = new TableRule("t_order", Arrays.asList("t_order_0", "t_order_1"), dataSourceRule);TableRule orderItemTableRule = new TableRule("t_order_item", Arrays.asList("t_order_item_0", "t_order_item_1"), dataSourceRule);/*** DatabaseShardingStrategy 分库策略* 参数一:根据哪个字段分库* 参数二:分库路由函数* TableShardingStrategy 分表策略* 参数一:根据哪个字段分表* 参数二:分表路由函数* */ShardingRule shardingRule = new ShardingRule(dataSourceRule, Arrays.asList(orderTableRule, orderItemTableRule),Arrays.asList(new BindingTableRule(Arrays.asList(orderTableRule, orderItemTableRule))),new DatabaseShardingStrategy("user_id", new ModuloDatabaseShardingAlgorithm()),new TableShardingStrategy("order_id", new ModuloTableShardingAlgorithm()));DataSource dataSource = new ShardingDataSource(shardingRule);String sql = "SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.user_id=? AND o.order_id=?";try (Connection conn = dataSource.getConnection();PreparedStatement pstmt = conn.prepareStatement(sql)) {pstmt.setInt(1, 10);pstmt.setInt(2, 1001);try (ResultSet rs = pstmt.executeQuery()) {while(rs.next()) {System.out.println(rs.getInt(1));System.out.println(rs.getInt(2));System.out.println(rs.getInt(3));}}}}/*** 创建数据源* @param dataSourceName* @return*/private static DataSource createDataSource(String dataSourceName) {BasicDataSource result = new BasicDataSource();result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());result.setUrl(String.format("jdbc:mysql://localhost:3306/%s", dataSourceName));result.setUsername("root");result.setPassword("");return result;}}Maven依赖的pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.study</groupId> <artifactId>sharding-jdbc</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>sharding-jdbc</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <spring.version>3.2.5.RELEASE</spring.version> <mybatis.version>3.2.4</mybatis.version> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.10</version> </dependency> <dependency> <groupId>com.dangdang</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>1.0.0</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-orm</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>commons-dbcp</groupId> <artifactId>commons-dbcp</artifactId> <version>1.4</version> </dependency> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>${mybatis.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-expression</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-aop</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-beans</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context-support</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-tx</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.28</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.16</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.5</version> </dependency> </dependencies> </project>
ModuloDatabaseShardingAlgorithm
package com.study.base;import java.util.Collection;
import java.util.LinkedHashSet;import com.dangdang.ddframe.rdb.sharding.api.ShardingValue;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.SingleKeyDatabaseShardingAlgorithm;
import com.google.common.collect.Range;/*** * @author lyncc**/
public class ModuloDatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm<Integer>{@Overridepublic String doEqualSharding(Collection<String> availableTargetNames, ShardingValue<Integer> shardingValue) {for (String each : availableTargetNames) {if (each.endsWith(shardingValue.getValue() % 2 + "")) {return each;}}throw new IllegalArgumentException();}@Overridepublic Collection<String> doInSharding(Collection<String> availableTargetNames, ShardingValue<Integer> shardingValue) {Collection<String> result = new LinkedHashSet<>(availableTargetNames.size());for (Integer value : shardingValue.getValues()) {for (String tableName : availableTargetNames) {if (tableName.endsWith(value % 2 + "")) {result.add(tableName);}}}return result;}@Overridepublic Collection<String> doBetweenSharding(Collection<String> availableTargetNames,ShardingValue<Integer> shardingValue) {Collection<String> result = new LinkedHashSet<>(availableTargetNames.size());Range<Integer> range = (Range<Integer>) shardingValue.getValueRange();for (Integer i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {for (String each : availableTargetNames) {if (each.endsWith(i % 2 + "")) {result.add(each);}}}return result;}}ModuloTableShardingAlgorithm.java
package com.study.base;
import java.util.Collection;
import java.util.LinkedHashSet;import com.dangdang.ddframe.rdb.sharding.api.ShardingValue;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.SingleKeyTableShardingAlgorithm;
import com.google.common.collect.Range;public final class ModuloTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Integer> {/*** select * from t_order from t_order where order_id = 11 * └── SELECT * FROM t_order_1 WHERE order_id = 11* select * from t_order from t_order where order_id = 44* └── SELECT * FROM t_order_0 WHERE order_id = 44*/public String doEqualSharding(final Collection<String> tableNames, final ShardingValue<Integer> shardingValue) {for (String each : tableNames) {if (each.endsWith(shardingValue.getValue() % 2 + "")) {return each;}}throw new IllegalArgumentException();}/*** select * from t_order from t_order where order_id in (11,44) * ├── SELECT * FROM t_order_0 WHERE order_id IN (11,44) * └── SELECT * FROM t_order_1 WHERE order_id IN (11,44) * select * from t_order from t_order where order_id in (11,13,15) * └── SELECT * FROM t_order_1 WHERE order_id IN (11,13,15) * select * from t_order from t_order where order_id in (22,24,26) * └──SELECT * FROM t_order_0 WHERE order_id IN (22,24,26) */public Collection<String> doInSharding(final Collection<String> tableNames, final ShardingValue<Integer> shardingValue) {Collection<String> result = new LinkedHashSet<>(tableNames.size());for (Integer value : shardingValue.getValues()) {for (String tableName : tableNames) {if (tableName.endsWith(value % 2 + "")) {result.add(tableName);}}}return result;}/*** select * from t_order from t_order where order_id between 10 and 20 * ├── SELECT * FROM t_order_0 WHERE order_id BETWEEN 10 AND 20 * └── SELECT * FROM t_order_1 WHERE order_id BETWEEN 10 AND 20 */public Collection<String> doBetweenSharding(final Collection<String> tableNames, final ShardingValue<Integer> shardingValue) {Collection<String> result = new LinkedHashSet<>(tableNames.size());Range<Integer> range = (Range<Integer>) shardingValue.getValueRange();for (Integer i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {for (String each : tableNames) {if (each.endsWith(i % 2 + "")) {result.add(each);}}}return result;}
}log4j.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE log4j:configuration PUBLIC "-//APACHE//DTD LOG4J 1.2//EN" "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/"> <!-- [控制台STDOUT] --> <appender name="console" class="org.apache.log4j.ConsoleAppender"> <param name="encoding" value="GBK" /> <param name="target" value="System.out" /> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%-5p %c{2} - %m%n" /> </layout> </appender> <!-- [公共Appender] --> <appender name="DEFAULT-APPENDER" class="org.apache.log4j.DailyRollingFileAppender"> <param name="File" value="${webapp.root}/logs/common-default.log" /> <param name="Append" value="true" /> <param name="encoding" value="GBK" /> <param name="DatePattern" value="'.'yyyy-MM-dd'.log'" /> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d %-5p %c{2} - %m%n" /> </layout> </appender> <!-- [错误日志APPENDER] --> <appender name="ERROR-APPENDER" class="org.apache.log4j.DailyRollingFileAppender"> <param name="File" value="${webapp.root}/logs/common-error.log" /> <param name="Append" value="true" /> <param name="encoding" value="GBK" /> <param name="threshold" value="error" /> <param name="DatePattern" value="'.'yyyy-MM-dd'.log'" /> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d %-5p %c{2} - %m%n" /> </layout> </appender> <!-- [组件日志APPENDER] --> <appender name="COMPONENT-APPENDER"
class="org.apache.log4j.DailyRollingFileAppender"> <param name="File" value="${webapp.root}/logs/logistics-component.log" /> <param name="Append" value="true" /> <param name="encoding" value="GBK" /> <param name="DatePattern" value="'.'yyyy-MM-dd'.log'" /> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d %-5p %c{2} - %m%n" /> </layout> </appender> <!-- [组件日志] --> <logger name="LOGISTICS-COMPONENT"> <level value="${loggingLevel}" /> <appender-ref ref="COMPONENT-APPENDER" /> <appender-ref ref="ERROR-APPENDER" /> </logger> <!-- Root Logger --> <root> <level value="${rootLevel}"></level> <appender-ref ref="DEFAULT-APPENDER" /> <appender-ref ref="ERROR-APPENDER" /> <appender-ref ref="console" /> <appender-ref ref="COMPONENT-APPENDER" /> </root>
</log4j:configuration> 好了,按照官方教程说明:
我们现在user_id是10,order_id是1001
我们应该在sharding0库中的t_order_1和t_order_item_1中新建数据:
INSERT INTO `t_order_1` VALUES ('1001', '10'); INSERT INTO `t_order_item_1` VALUES ('4', '1001', '2'); 好了,准备工作做完了,我们运行main函数,运行结果为:
好了,sharding-jdbc正常工作了
这篇关于学习dangdang的分库分表扩展框架sharding-jdbc(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




