本文主要是介绍《Python网络爬虫从入门到实践 第2版》第17章 爬虫实践四:畅销书籍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第17章 爬虫实践四:畅销书籍
我们平时去在购买书籍之前,总喜欢看看畅销的书籍有哪些,别人的评价怎么样,再决定是否购买。亚马逊电商网站最早就是从卖书做起的,所以本章选择亚马逊作为案例来获取畅销书榜单的数据,以及相应的评论数据。
本章为爬取亚马逊数据的实践项目,所采用的技术包括:
·使用Selenium爬取网站
·使用BeautifulSoup解析网页
·数据存储至CSV文件
17.1 项目描述
本项目的目标是爬取亚马逊中国网站的书籍信息。首先使用Selenium获取网页的信息,然后使用BeautifulSoup解析网页中的数据,最终将数据存储至CSV文件中。
本项目的数据获取分为三步:
(1)获取亚马逊的总体图书销售榜。
(2)获取亚马逊图书各个分类的销售榜。
(3)进入每本书的网页,获取书籍的评论。
亚马逊中国图书销售榜的地址为https://www.amazon.cn/gp/bestsellers/books/ref=sv_b_3,如图17-1所示。
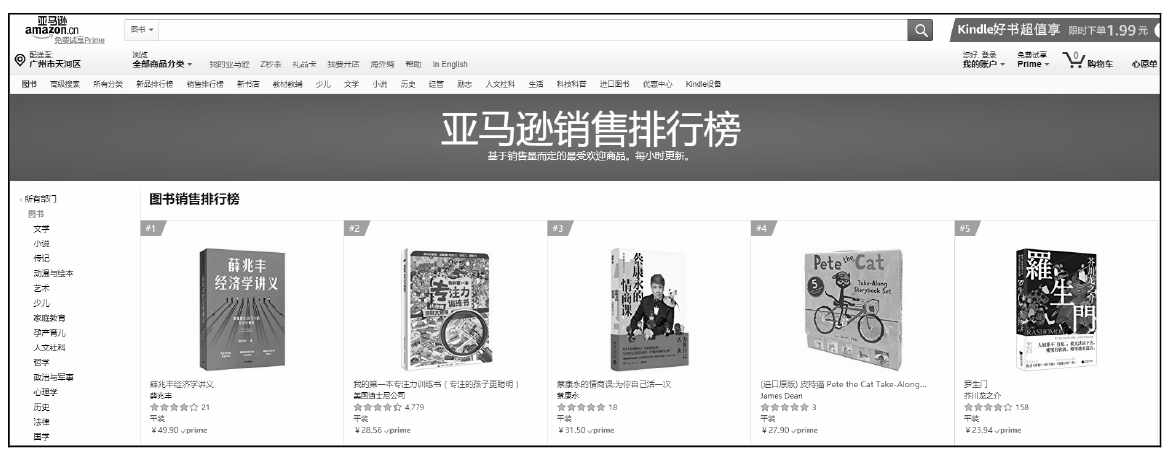
图17-1 亚马逊图书销售榜
17.2 网站分析
首先打开亚马逊图书销售榜,发现第一页只加载了50本图书。如果需要爬取后面排名的图书,要单击“下一页”换页,最多只有两页。从第一页翻页到第二页,第二页的网址是https://www.amazon.cn/gp/bestsellers/books/ref=zg_bs_pg_2?i
这篇关于《Python网络爬虫从入门到实践 第2版》第17章 爬虫实践四:畅销书籍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




