本文主要是介绍Cache学习(2):Cache结构 命中与缺失 多级Cache结构 直接映射缓存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 Cache名词解释
- 命中(hit): CPU要访问的数据在Cache中有缓存
- 缺失(miss): CPU要访问的数据在Cache中没有缓存
- Cache Size:Cache的大小,代表Cache可以缓存最大数据的大小
- Cache Line:Cache会被平均分成很多相等的块,每一个块大小称之为Cache Line Size;Cache Line是Cache和主存之间数据传输的最小单位。当CPU试图load一个字节数据的时候,如果Cache缺失,那么Cache控制器会从主存中一次性的load一个Cache Line大小的数据到Cache中。例如,Cache Line大小是8字节。CPU即使读取一个Byte,在Cache 出现miss后,Cache会从主存中load 8字节填充整个Cache Line。
Cache Size 为 64 Bytes的Cache举两个例子:
- 将64 Bytes平均分成64块,那么Cache Line就是1字节,总共64行Cache Line
- 将64 Bytes平均分成8块,那么Cache Line就是8字节,总共8行Cache Line
现在的硬件设计中,一般Cache Line的大小是4-128 Byts。会有如下两个问题:
- Cache如何判断是否命中
- 这个值为什么不是更低,低至1字节,这样就可以更加灵活的映射,从而没有刷新整个cache line的开销
- 这个值为什么不是更高或者更低
- 为什么一次要读取整个Cache Line
将在后文中进行解释说明。
2 多级Cache之间的配合工作
当CPU试图从某地址load数据时,下图为只有两级Cache的系统举例:
- 从L1 Cache中查询是否命中,如果命中则把数据返回给CPU(蓝色实线)
- L1 Cache缺失,则继续从L2 Cache中查找。当L2 Cache命中时,数据会返回给L1 Cache以及CPU(绿色实线&绿色虚线)
- L2 Cache也缺失,需要从主存中load数据,将数据返回给L2 Cache、L1 Cache及CPU(红色实线&红色虚线)
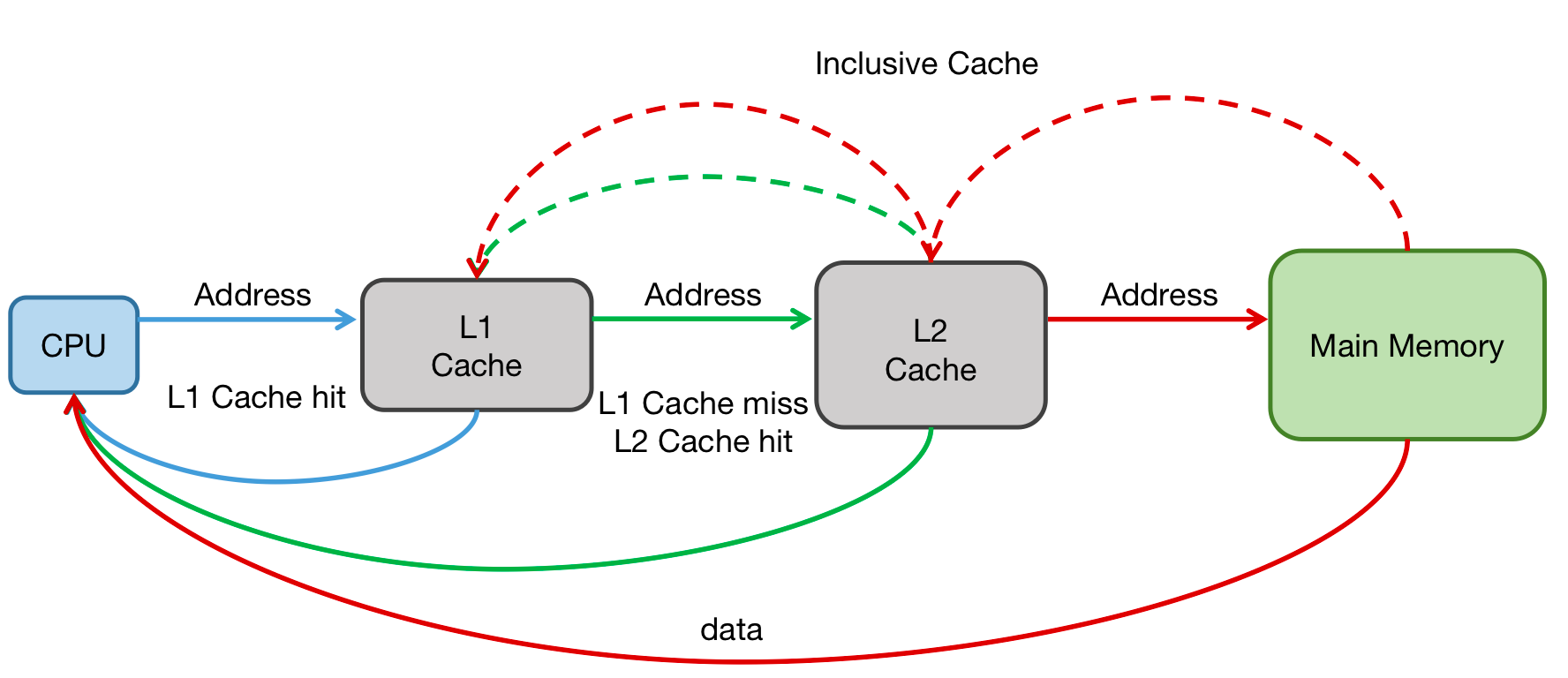
这种多级Cache的工作方式称之为inclusive Cache。某一地址的数据可能存在多级缓存中。与Inclusive Cache对应的是Exclusive Cache,这种Cache保证某一地址的数据缓存只会存在于多级Cache其中一级。也就是说,任意地址的数据不可能同时在L1和L2 Cache中缓存。
3 直接映射缓存(Direct Mapped Cache)
3.1 举例1
以一个Cache Size 为 128 Bytes 并且Cache Line是 16 Bytes的Cache为例。首先把这个Cache想象成一个数组,数组总共8个元素,每个元素大小是 16 Bytes,如下图:
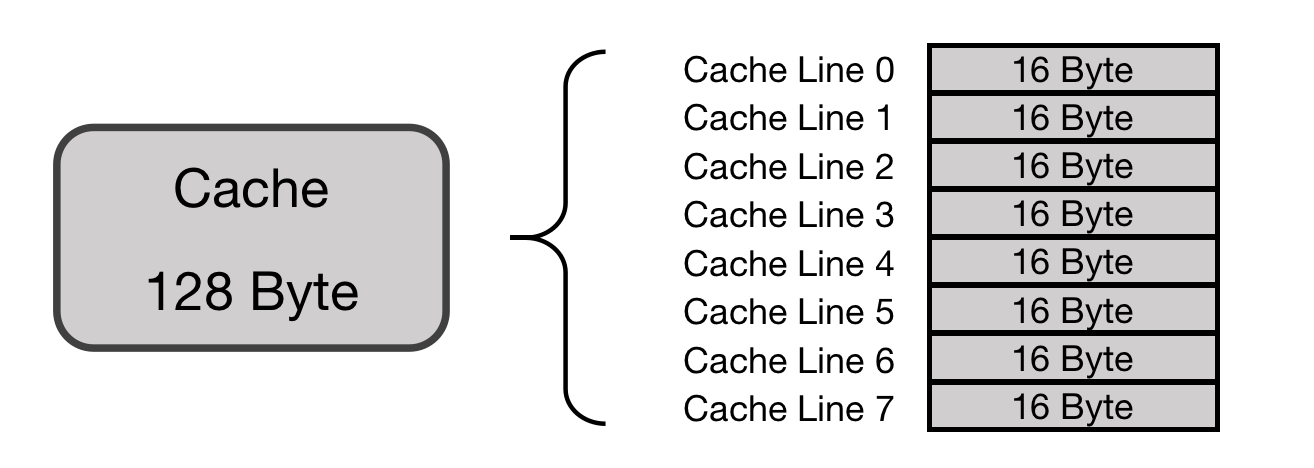
现在考虑一个问题,CPU从0x0654地址读取一个字节,由于Cache大小相对于主存来说,是非常小的。所以Cache只能缓存主存中极小一部分数据。如何根据地址在有限大小的Cache中查找数据呢?现在硬件采取的做法是对地址进行散列(可以理解成地址取模操作)。
3.2 命中与缺失
经过如下计算:
- 假设地址总线是16位,目标地址为0x0654,转换为二进制为
0000,0110,0101,0100 - Offset:由于每个Cache Line中有16 Byte,所以地址最低4位,即为每一个Cache Line中的偏移Offset,标记在这个Cache Line中的具体位置是哪个字节,举例中为
0100,即为图中地址段的蓝色背景部分 - Index:由于一共有8个Cache Line,所以地址除去最低4位的后3位,即为不同Cache Line的索引Index,标记具体在整个Cache 中的那一个Cache Line,举例中为
101,即为图中地址段的绿色背景部分
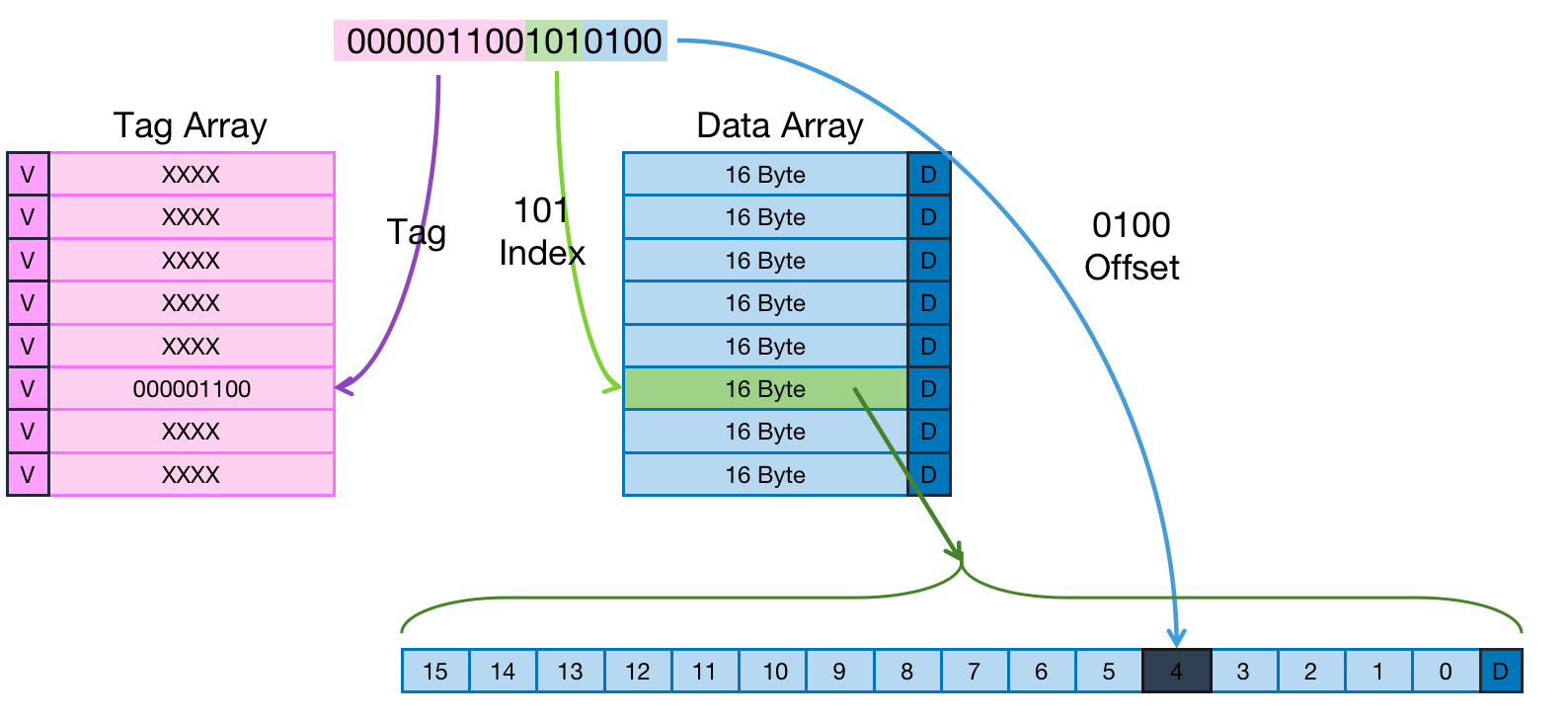
如果两个不同的地址,其地址的Index部分完全一样,这两个地址经过硬件散列之后都会找到同一个Cache Line。所以,根据地址确定到Cache Line之后,只代表所需要访问的目标地址中存储的对应数据可能存在这个Cache Line中,但是该Cache Line也有可能存储其他地址对应的数据。
所以,独立于Data Array,又引入Tag Array区域,Tag Array和Data Array中的每一个Cache Line都有着一一对应关系。每一个Cache Line都对应唯一一个tag,tag中保存的是整个地址位宽去除index和offset使用的bit剩余部分(如上图地址粉色背景部分)。tag、index和offset三者组合就可以唯一确定一个地址了。
因此,根据地址中index位找到Cache Line后,取出当前Cache Line对应的tag,然后和目标地址的tag进行比较,如果相等,这说明Cache命中。如果不相等,说明当前Cache Line存储的是其他地址的数据,这就是Cache缺失。
在上述图中,我们看到tag的值是0,0000,1100,和地址中的tag部分相等,因此在本次访问会命中。
我们可以从图中看到tag旁边还有一个valid bit,这个bit用来表示Cache Line中数据是否有效(例如:1代表有效;0代表无效)。当系统刚启动时,Cache中的数据都应该是无效的,因为还没有缓存任何数据。Cache控制器可以根据valid bit确认当前Cache Line数据是否有效。所以,上述比较tag确认Cache Line是否命中之前还会检查valid bit是否有效。只有在有效的情况下,比较tag才有意义。如果无效,直接判定Cache缺失。
此时回答,前文提出的第二个问题:这个值为什么不是更低,低至1字节,这样就可以更加灵活的映射,从而避免了因为部分所需要的数据而刷新整个Cache Line的开销
由于tag的引入。这样会导致硬件成本的上升,将两种情况进行对比:
- 原本Cache Line 设置为16 Byte:每16 Byte对应一个tag,需要8个tag
- 假设Cache Line设置为1 Byte:需要128个Tag同时每一个Tag的长度也会更长,因为Offest缩短了
因此可以发现这样做占用了很多内存。需要注意:tag也是Cache的一部分,但是谈到Cache size的时候并不考虑tag占用的内存部分。
上面的例子中,总结如下:Cache Size是128 Byte并且Cache Line size是16 Byte,共计8个Cache Line。
- offset:4bit
- index:3bit
- tag:9bits(假设地址宽度是16 bit)
3.3 直接映射缓存的优缺点
- 优点1:直接映射缓存在硬件设计上会更加简单
- 优点2:因为优点1,所以成本上也会较低
根据直接映射缓存的工作方式,可以计算出不同主存地址段和对应的Cache
| 地址段 | Cahce Line Index |
|---|---|
| 0x0000-0x000F,0x0080-0x008F,… | 0 |
| 0x0010-0x001F,0x0090-0x009F,… | 1 |
| 0x0020-0x002F,0x00A0-0x00AF,… | 2 |
| 0x0030-0x003F,0x00B0-0x00BF,… | 3 |
| 0x0040-0x004F,0x00C0-0x00CF,… | 4 |
| 0x0050-0x005F,0x00D0-0x00DF,… | 5 |
| 0x0060-0x006F,0x00E0-0x00EF,… | 6 |
| 0x0070-0x007F,0x00F0-0x00FF,… | 7 |
可以看到,地址0x0000-0x007F地址(0x0000-0x000F~0x0070-0x007F)处对应的数据可以覆盖整个Cache。0x0080-0x00FF地址的数据也同样是覆盖整个Cache。
现在思考一个问题,如果一个程序试图依次访问地址0x0000、0x0080、0x0100,Cache中的数据会发生什么呢?首先应该明白0x0000、0x0080、0x0100地址中index部分是一样的。因此,这3个地址对应的Cache Line是同一个。所以,当访问0x0000地址时,Cache会缺失,然后数据会从主存中加载到Cache中第0行Cache Line。当我们访问0x0080地址时,依然索引到Cache中第0行Cache Line,由于此时Cache Line中存储的是地址0x0000地址对应的数据,所以此时依然会Cache缺失。然后从主存中加载0x0080地址数据到第一行Cache Line中。同理,继续访问0x0100地址,依然会Cache缺失。这就相当于每次访问数据都要从主存中读取,所以Cache的存在并没有对性能有什么提升。访问0x0080地址时,就会把0x00地址缓存的数据替换。这种现象叫做Cache颠簸(Cache thrashing)。针对这个问题,在后面的文章中引入多路组相连缓存优化规避这一问题。

这篇关于Cache学习(2):Cache结构 命中与缺失 多级Cache结构 直接映射缓存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







