本文主要是介绍论文翻译2(凝练):Deep SORT: Simple Online and Realtime Tracking with a Deep Association Metric,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分配
匹配自然是指:当前有效的轨迹和当前的detections之间的匹配。
有效的轨迹:是指那些还存活着的轨迹,即状态为tentative和confirmed的轨迹。
轨迹和detection之间的匹配程度:结合了运动信息和表观信息。
-
运动匹配度
使用detection和track在kalman 滤波器预测的位置之间的马氏距离刻画运动匹配程度。
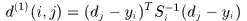
表示第j个detection和第i条轨迹之间的运动匹配度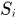 是轨迹由kalman滤波器预测得到的在当前时刻观测空间的协方差矩阵,
是轨迹由kalman滤波器预测得到的在当前时刻观测空间的协方差矩阵,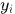 是轨迹在当前时刻的预测观测量,
是轨迹在当前时刻的预测观测量, 时第j个detection的状态
时第j个detection的状态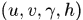
考虑到运动的连续性,可以通过该马氏距离对detections进行筛选
使用卡方分布的0.95分位点作为阈值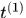 ,定义如下示性函数
,定义如下示性函数
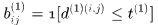
-
表观匹配度
单独使用马氏距离最为匹配度度量会导致IDSwitch等情形严重,特别的当相机运动时可能导致马氏距离度量失效,所以这个时候应该靠表观匹配度补救。
对于每一个detection,包括轨迹中的detections,使用深度网络提取出单位范数的特征向量rj,深度网络稍后再说。
单位范数的特征向量appearance descriptor rj: || rj ||=1
作者对每一个追踪目标构建一个gallary,存储每一个追踪目标成功关联的最近100帧的特征向量
detection和track之间的表观匹配程度:
使用轨迹包含的detections的特征向量和detection之间的最小余弦距离,
(即第i个追踪器的最近100个成功关联的特征集与当前帧第j个检测结果之间的最小余弦距离)
当然轨迹太长导致表观产生变化,在使用这种最小距离作为度量就有风险,所以文中只对轨迹的最新的
之内detections进行计算最小余弦距离。

该度量确定一个门限函数: ,这个阈值由训练集得到.
,这个阈值由训练集得到.
两种度量的融合: 加权平均 
超参数: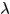 用于调整不同项的权重。
用于调整不同项的权重。
门限函数: 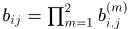 ,因为是相乘,两个门限都要达到.
,因为是相乘,两个门限都要达到.
总结:
距离度量:对于短期的预测和匹配效果很好,而表观信息对于长时间丢失的轨迹而言,匹配度度量的比较有效。
超参数的选择:要看具体的数据集,比如文中说对于相机运动幅度较大的数据集,直接不考虑运动匹配程度。
相通的重要程度:另外还有一点我想说的是这两个匹配度度量的阈值范围是不同的,如果想取相通的重要程度,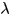 应该取0.1左右。
应该取0.1左右。
级联匹配
为什么采用级联匹配?
如果一条轨迹被遮挡了一段较长的时间,那么在kalman滤波器的不断预测中就会导致概率弥散,kalman滤波预测的不确定性就会大大增加,状态空间内的可观察性就会大大降低。
那么假设现在有两条轨迹竞争同一个detection,那么那条遮挡时间长的往往得到马氏距离更小,使detection倾向于分配给丢失时间更长的轨迹,这种不理想的效果往往会破坏追踪的持续性.
但是直观上,该detection应该分配给时间上最近的轨迹。
导致这种现象的原因正是由于kalman滤波器连续预测没法更新导致的概率弥散。
这么理解吧,假设本来协方差矩阵是一个正态分布,那么连续的预测不更新就会导致这个正态分布的方差越来越大,那么离均值欧氏距离远的点可能和之前分布中离得较近的点获得同样的马氏距离值
所以文中才引入了级联匹配的策略让'more frequently seen objects'分配的优先级更高。
这样每次分配的时候考虑的都是遮挡时间相同的轨迹,就不存在上面说的问题了。
具体的算法如下:

级联匹配的核心思想就是由小到大对消失时间相同的轨迹进行匹配,这样首先保证了对最近出现的目标赋予最大的优先权,也解决了上面所述的问题。
清单1中概述了我们的匹配算法。
作为输入提供的跟踪T和检测D指数以及最高年龄最大。
1:关系矩阵代价 C=[cij]
2:容许关联矩阵 B = [bij]
然后迭代跟踪年龄n来解决增长年龄的跟踪线性分配问题。
3:用空集合,初始化匹配集合M
4:用D,初始化非匹配集合U
5:for n从1到Amax每一个:
6:我们选择在最后n帧里面还没有被检测关联的追踪T n的子集。
7:用C 解决轨道之间的线性匹配( 未关联跟踪轨迹T n 和 无匹配的检测U)。
8:我们更新匹配
9:和无匹配的检测,在第11行结果返回。
注意:这个匹配的级联为主较小年龄的痕迹优先权,即最近见过的跟踪。
在匹配的最后阶段还对unconfirmed和age=1的未匹配轨迹进行基于IoU的匹配。这可以缓解因为表观突变或者部分遮挡导致的较大变化。当然有好处就有坏处,这样做也有可能导致一些新产生的轨迹被连接到了一些旧的轨迹上。但这种情况较少。
这篇关于论文翻译2(凝练):Deep SORT: Simple Online and Realtime Tracking with a Deep Association Metric的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







