本文主要是介绍是泄漏的relu实际上是对relu的改进,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TL;DR: The premise for Leaky ReLU is that ReLU has a problem of being bounded on only one side and that any negative number has an output of 0, ‘killing’ the neuron. Leaky ReLU theoretically should perform better, but is relatively the same in practice because the dead neuron problem is not common and can be remedied through other more mainstream methods.
TL; DR:泄漏ReLU的前提是ReLU存在仅在一侧受限制的问题,并且任何负数的输出均为0,从而“杀死”神经元。 从理论上讲,泄漏的ReLU的性能应该更好,但是在实践中相对相同,因为死亡的神经元问题并不常见,可以通过其他更主流的方法来解决。
The Rectified Linear Unit, abbreviated as ReLU, has shown incredible results when abundantly used in deep neural networks. Perhaps what is shocking about this success is that it is so simple: essentially a line bent at the origin such that the left half is y = 0 and the right is y = x.
当在深度神经网络中大量使用时,整流线性单位(缩写为ReLU)已显示出令人难以置信的结果。 可能令这一成功震惊的是,它是如此简单:本质上是一条在原点弯曲的线,使得左半部分为y = 0而右半部分为y = x 。
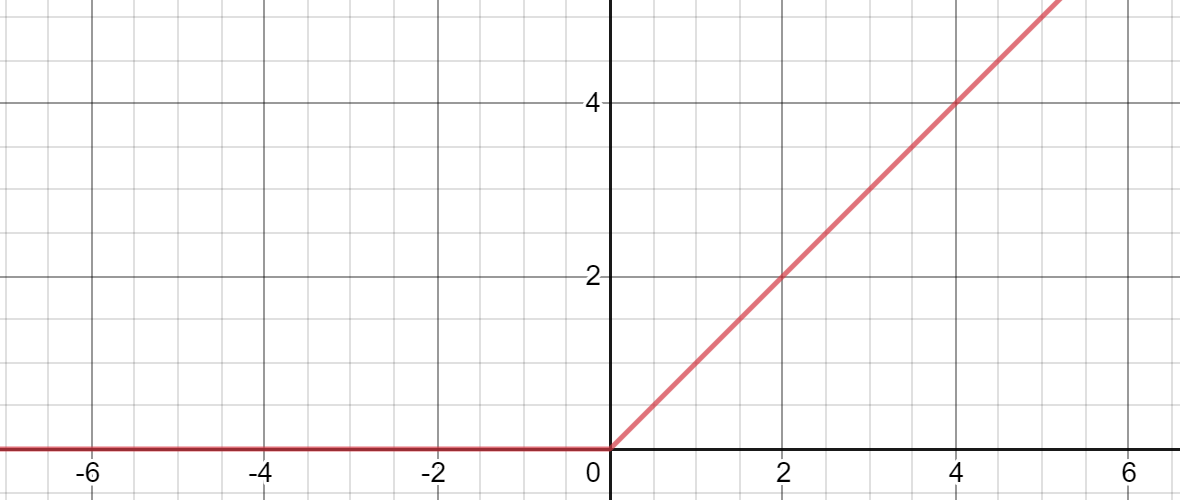
Unlike curved activation functions like sigmoid or tanh, it doesn’t have a complex derivation or relation with the nature of probability — it is two lines. In fact, it can be difficult to see why ReLU works at all.
与诸如S型或tanh的曲线激活函数不同,它与概率的性质没有复杂的推导或关系-它是两条线。 实际上,很难理解ReLU为何起作用 。
We can peek into the answer by taking a look at feature maps of networks solving a two-circle problem over time with different activations.
我们可以通过查看随着时间的推移以不同的激活来解决两圆问题的网络的特征图来窥视答案。
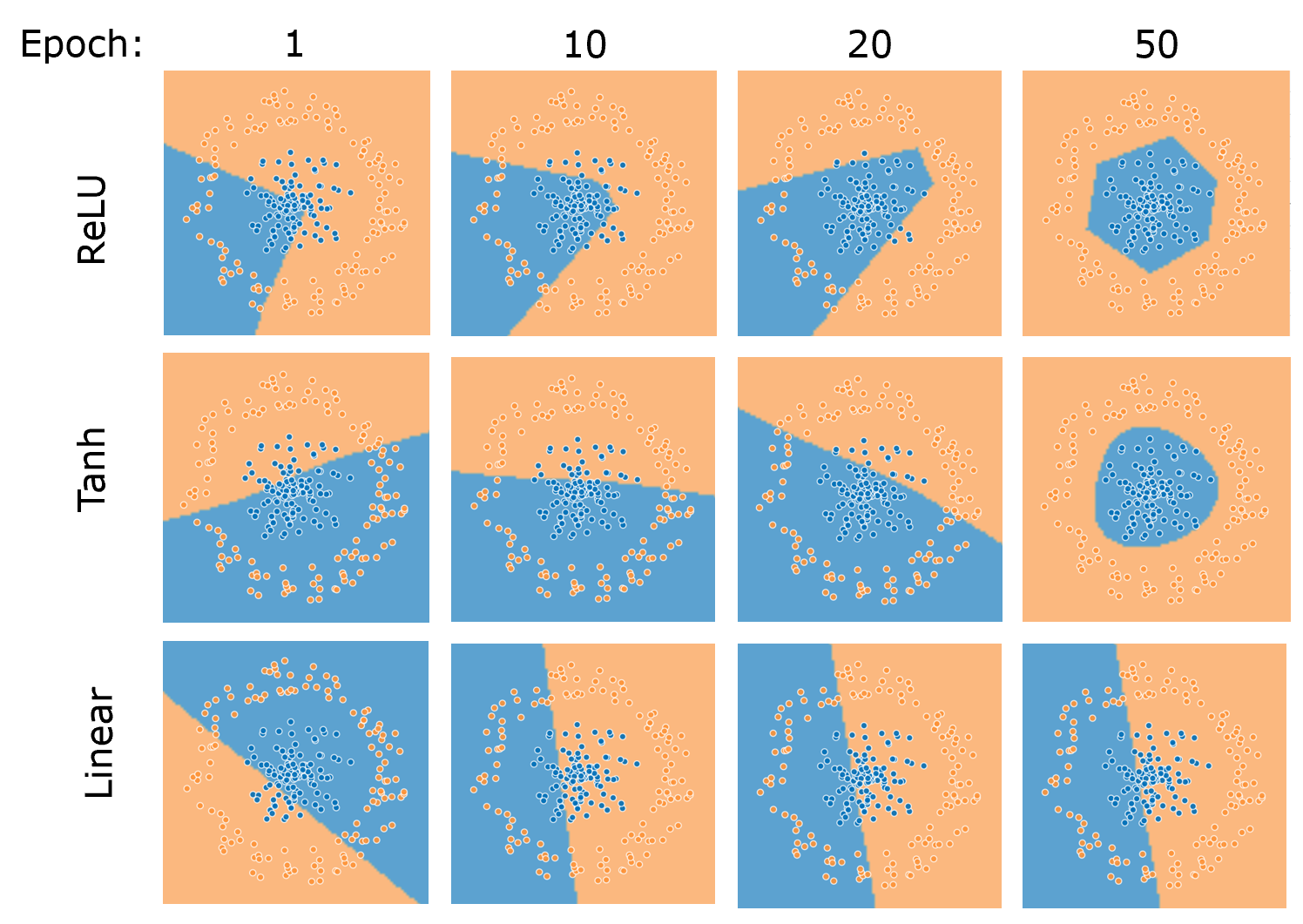
ReLU draws the feature boundaries using corners, or junctions of lines, whereas a curved activation like tanh draws a curved envelope around the inside circle. The shape of the feature boundaries drawn by the network has heavy dependence on the choice of activation.
ReLU使用拐角或直线的交点绘制要素边界,而诸如tanh的弯曲激活则在内部圆周围绘制弯曲的包络线。 网络绘制的特征边界的形状在很大程度上取决于激活的选择。
Like all other activation functions, ReLU serves as a unit of a neuron, acting as some degree of freedom to the feature boundaries. However, it’s simple: the junction of two lines, rather than some trigonometric or exponential curve. Hence, the derivative is exceptionally easy to compute (if you’d even call it computing): 1 for the right half and 0 for the left half.
像所有其他激活功能一样,ReLU充当神经元的单元,对特征边界起一定程度的自由度。 但是,这很简单:两条线的交汇点,而不是某些三角或指数曲线。 因此,导数非常容易计算(如果您甚至称其为计算):右半部分为1,左半部分为0。
Additionally, ReLU isn’t bounded on both sides; because the gradient is constant, there’s no need to worry of a vanishing gradient that plagues networks populated with bounded activations.
此外,ReLU并非两侧都有界。 由于梯度是恒定的,因此无需担心梯度消失的困扰,这些梯度困扰着充满激活作用的网络。
There is, however, a concern about the left half of ReLU, which yields 0 regardless of the input and perpetuates a malicious cycle. Say that prior to an input being passed through the activation, it is multiplied by a very large negative weight. The output of the neuron is 0, whose gradient is also 0.
但是,人们担心ReLU的左半部分,不管输入如何,该半部分都会产生0,并会持续一个恶意周期。 假设在输入通过激活之前,它乘以很大的负权重。 神经元的输出为0,其梯度也为0。
This gives the network essentially no information about the state of the weight in relation to the loss. Perhaps a weight of -3 is closer to performing better than -100,000; but the network wouldn’t know since the output for both is 0. Therefore, the weight is never updated because it is never updated — at this point, it is proclaimed to be ‘dead’.
这使得网络基本上没有有关重量状态的信息。 权重-3可能比-100,000更接近于表现; 但是网络不会知道,因为两者的输出均为0。因此,权重永远不会更新,因为它永远不会更新-在这一点上,它被称为“死”。
Note that bounded functions like sigmoid and tanh do not have this problem because their gradients are never equal to 0.
请注意,像Sigmoid和tanh这样的有界函数不会出现此问题,因为它们的梯度永远不会等于0。
Leaky ReLU uses the equation max(ax, x), opposed to max(0, x) for ReLU, where a is some small, preset parameter. This allows for some gradient to leak in the negative half of the function, which can provide more information to the network for all values of x.
泄漏的ReLU使用方程式max(ax, x) ,与ReLU的max(0, x)相反,其中a是一些小的预设参数。 这允许某些梯度在函数的负一半中泄漏,从而可以为x的所有值向网络提供更多信息。
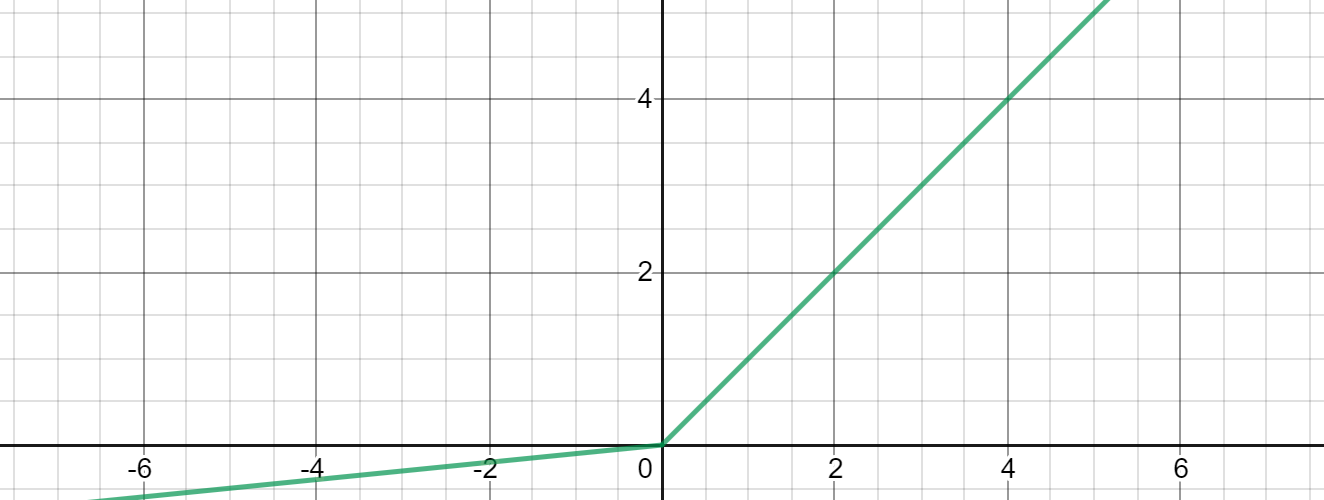
Using Leaky ReLU makes sense, but empirically it has shown, at best, to have a slight advantage over ReLU. Most of the time, ReLU performs at the same level or even better than its alternative. Why is this the case?
使用泄漏的ReLU是有意义的,但从经验上看,它最多显示出比ReLU略有优势。 在大多数情况下,ReLU的性能与同类产品相同甚至更好。 为什么会这样呢?
Are dead neurons a significant threat?
死亡的神经元是否构成重大威胁?
- Remember that there are always biases added to weights. If weights are initialized properly and biases act as supports, there should be a healthy gradient stream from the start. 请记住,权重总是存在偏差。 如果权重初始化正确,并且偏见作为支持,那么从一开始就应该有一个健康的渐变流。
- Dead neurons form with overwhelmingly large negative weights. This can form two ways: a) the network is initialized poorly, or b) there is an exploding gradients problem that causes massive updates to weights. There are solutions to both. 死亡的神经元以极大的负重形成。 这可以形成两种方式:a)网络初始化不佳,或b)爆炸梯度问题导致权重的大量更新。 两者都有解决方案。
- A dead neuron does not necessarily mean that the neuron’s output will be zero at testing; it all depends on the distribution of the inputs. This is, however, a small possibility. 死亡的神经元并不一定意味着在测试时神经元的输出将为零。 这一切都取决于投入的分配。 但是,这种可能性很小。
- A dead neuron is not always permanently dead; the introduction of new training data can activate weights again through gradient descent. This is, again, a small possibility. 死亡的神经元并不总是永久死亡。 新训练数据的引入可以通过梯度下降再次激活权重。 再次,这是一个小可能性。
- Given the size of modern neural nets, a few dead neurons has little to no impact. One can even argue that it acts like a fixed Dropout of sorts, restricting the network from passing inputs forward. 考虑到现代神经网络的规模,一些死亡的神经元几乎没有影响。 甚至可以说它像固定的Dropout,限制了网络将输入转发出去。
The primary issue — that is, massive updating of the weights, can be addressed through batch normalization, which smooths the loss space for more natural gradients; standard regulation, which prevents neurons from having weights that are too large in the first place; or even a properly set learning rate, which can reduce the step size of weights.
主要问题-权重的大量更新可以通过批量归一化解决 ,这可以平滑损失空间以实现更自然的梯度; 标准规则 ,首先防止神经元的权重过大; 甚至是正确设置的学习率 ,都可以减少权重的步长。
That being said, there are only two downsides towards using Leaky ReLU:
话虽如此,使用Leaky ReLU仅存在两个缺点:
The choice of a is not learnable like in Parametric ReLU, instead it must be set. Choosing the wrong value could do more detriment than good.
像在Parametric ReLU中一样,学习a的选择不是很容易,而是必须设置它。 选择错误的值可能弊大于利。
- There’s not much usage of ReLU variants in the academic community, so most academics not directly studying activation functions will choose ReLU for an apples-to-apples comparison. ReLU变体在学术界没有太多用途,因此大多数不直接研究激活功能的学者都会选择ReLU进行苹果对苹果的比较。
In general, Leaky ReLU just hasn’t caught on that much in the deep learning community because there is no significant advantage. Granted, it has few reasons not to use, and some make the argument that a method with potential benefit and small downsides is reason enough for continuous usage.
通常,由于没有明显的优势,Leaky ReLU在深度学习社区中只是没有受到太大关注。 当然,它没有理由不使用,并且有些人认为,具有潜在利益和小的缺点的方法足以继续使用。
If you incorporate good practices into your network, like regularization (e.g. dropout, L1/L2), batch normalization, well-chosen optimizers with proper learning rates, etc., with most datasets dead neurons shouldn’t be much of a problem. But as some say — better safe than sorry.
如果您将良好做法(例如正则化(例如,辍学,L1 / L2),批处理规范化,具有适当学习率的精心选择的优化器)整合到网络中,则对于大多数数据集而言,死去的神经元应该不是什么大问题。 但是正如某些人所说,安全要比后悔好。
翻译自: https://towardsdatascience.com/is-leaky-relu-actually-an-improvement-over-relu-7702fdd58240
相关文章:
这篇关于是泄漏的relu实际上是对relu的改进的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






