本文主要是介绍maxwell采集数据到kafka报错,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题: 启动maxwell后出现数据更新后就出现以下报错。

13:29:14,727 ERROR MaxwellKafkaProducer - TimeoutException @ Position[BinlogPosition[binlog.000002:12215591], lastHeartbeat=1700717043797] -- maxWellData: medical:consultation:[(id,212)]
13:29:14,728 ERROR MaxwellKafkaProducer - Expiring 35 record(s) for maxWellData-0: 30005 ms has passed since batch creation plus linger time
排查过程:
1.排查maxwell:配置maxwell输出到控制台,发现采集数据后正常输出,说明maxwell配置正常。
[root@VM-4-10-centos maxwell]# bin/maxwell --user='maxwell' \
> --password='maxwell' \
> --host='10.0.4.10' \
> --producer=stdout
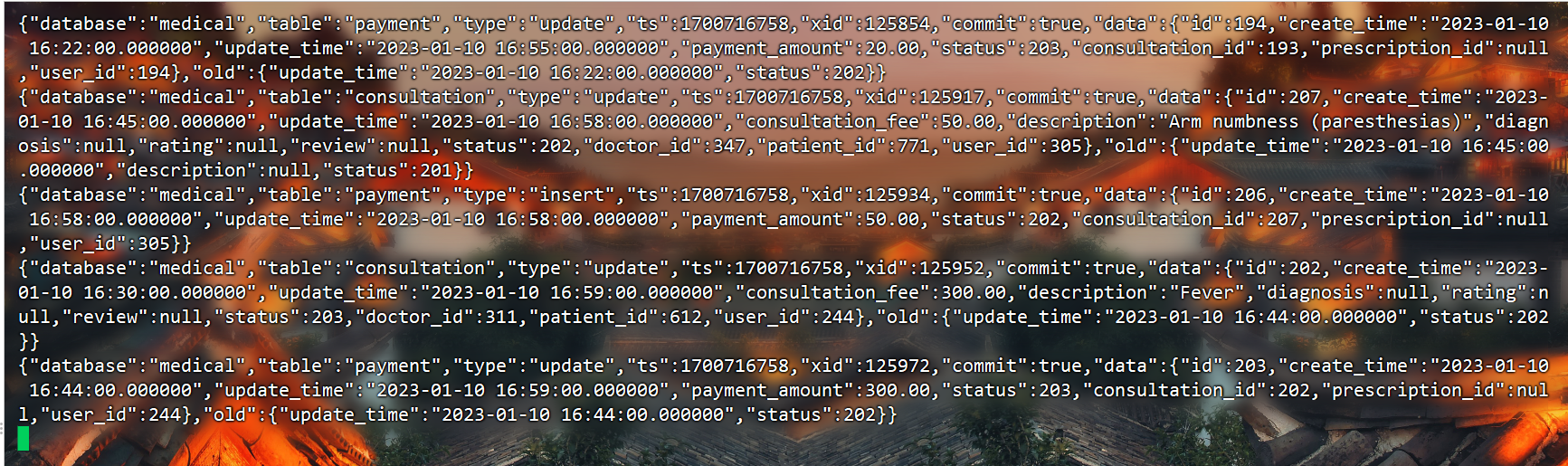
2.使用logstash采集数据到kafka
logstash使用说明:https://blog.csdn.net/m0_52606060/article/details/134499513?spm=1001.2014.3001.5501
input {generator {message => '14.49.42.25 - - [12/May/2019:01:24:44 +0000] "GET /articles/ppp-over-ssh/ HTTP/1.1" 200 18586 "-" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2b1) Gecko/20091014 Firefox/3.6b1 GTB5"'count => 1}
}output {stdout {codec => rubydebug}kafka {bootstrap_servers => "101.91.153.39:9092,61.171.111.6:9092,61.171.100.138:9092"codec => json_linestopic_id => "maxWellData"}
}
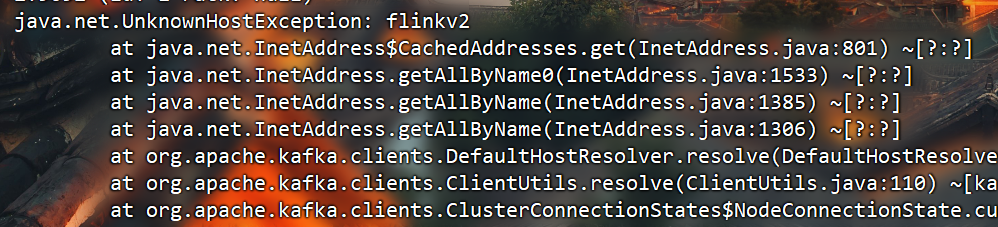
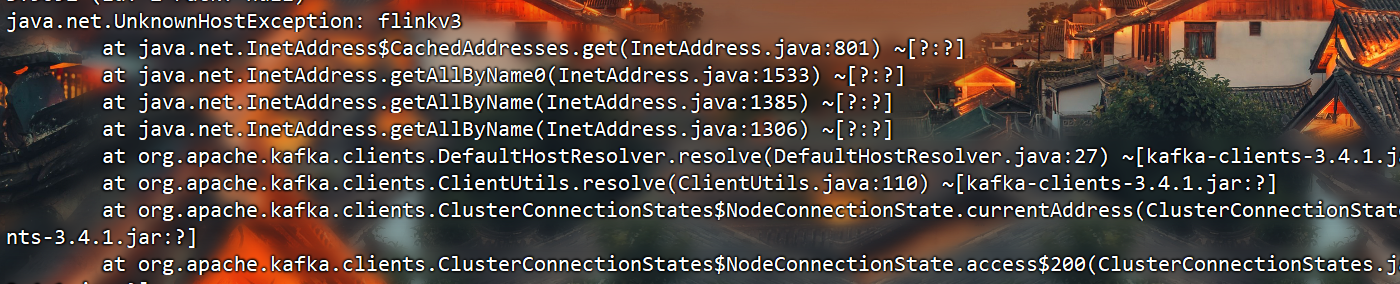

问题:logstash也无法输出数据到kafka,报错无法识别主机名称(图中报错的是我的内网ip映射别名)。这个地址是远程服务器的实例名称(天翼云服务器)。自己配置的明明是ip,程序内部却去获取他的别名,那如果生产者所在机器上没有配置这个ip的别名,就不能解析到对应的ip,所以连接失败报错。
原因:我用的阿里云服务器部署的maxwell向天翼云kafka集群发送数据不在同一个内网下,使用公网IP导致识别不了。 解决方法:做对应hosts映射。

修改后重新启动logstash发现数据写入kafka成功。

再次启动maxwell,发现写入kafka正常。

这篇关于maxwell采集数据到kafka报错的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!