本文主要是介绍成电分布式系统复习<上>,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一章
1、分布式系统的构建原因
构造分布式系统的主要动机是资源共享和协同计算
2、分布式系统举例
- WEB搜索:Google
- 大型多人在线游戏
- 金融交易
- 区块链系统
3、分布式系统的定义
- 分布式系统是指把多个处理机通过网络互连而构成的系统,系统的处理和控制功能分布在各个处理机上。
4、分布式系统的特征
- 并发性
多程序并发执行,共享资源 - 没有全局时钟
每个机器都有各自的时间,没有办法做到统一依靠交换信息进行程序间协调 - 故障独立性
一些进程出现故障,不能保证其他进程都能得知
5、分布式系统面临的挑战
-
异构性
1.网络协议不同
2.硬件,不同 CPU 字节序不同
3.操作系统不同,对上提供的 API 不同
4.编程语言不同
5.开发者实现方式不同 -
解决方案
1.中间件
在软件层应用,进而屏蔽底层的异构性
2.移动代码
代码在不同的机器间移动并执行;
虚拟机运行在不同的机器或系统上,代码在虚拟机上运行 -
开放性
1.计算机系统的开放性
一个系统是否可以扩充或以不同的方式重新实现
2.分布式系统的开放性
系统的关键接口是开放的
统一的通信机制 -
安全性
机密性、完整性(防止数据被篡改或破坏)、可用性(防止对所提供服务的干扰) -
可扩展性
要求扩展后,系统性能依旧保持在一定水平上 -
故障处理
检测故障:检测数据,比较难
屏蔽故障:重发没有收到的消息或者备份服务器
故障容错:系统设计成容忍错误的存在
故障恢复:记录日志 -
并发
正确性:多个进程并发访问共享资源,要保证被访问数据的正确性,不能出现不一致 -
透明性
访问、位置、并发、复制、故障、移动、性能、扩展透明
第二章
1. 分布式系统的物理模型
- 物理模型 (physical models):也就是从硬件方面来看如何组成分布式系统的
2. 分布式系统的体系结构模型
- 体系结构模型 (architectural models):从系统的计算元素执行的计算和通信任务方面来描述系统;C-S模型和对等模型是最常见的体系结构模型。
2.1 C/S、P2P两种不同结构
- c/s
它是所有网络应用的基础。客户/服务器分别指参与一次通信的两个应用实体,客户方主动地发起通信请求,服务器方被动地等待通信的建立。
优点:可以在用户态服务器中构造各种各样的API,为应用程序与服务间通过RPC调用进行通信提供一致的方法,且没有限制其灵活性,为分布式计算提供了适当的基础 - p2p
该结构可由若干互联协作的计算机构成,且至少具有如下特征之一
– 系统依存于边缘化(非中央式服务器)设备的主动协作;
– 每个成员直接从其他成员而不是从服务器的参与中受益;
– 系统中成员同时扮演服务器与客户端的角色;
– 系统应用的用户能够意识到彼此的存在,构成一个虚拟或实际的群体。
2.2 分层模型、层次化模型
-
分层模型:一个复杂的系统被分成若干层,每层利用下层提供的服务。最底层软硬件为上层提供服务,然后是中间件,中间件是一种软件,它提供基本的通信模块和其他一些基础服务模块,为应用程序开发提供平台。
-
层次化模型:–
3. 交互、故障、安全三种基础模型
-
交互模型:进程之间通过消息传递进行交互,实现系统的通信和协作功能。
有较长时间的延迟
时间是进程间进行协调的基本的参照,在分布式系统中,很难有相同的时间概念
交互模型的目的是依据同步分布式系统和异步分布式系统的不同来构造交互算法,可以对算法在实际分布式系统的行为提供一些想法 -
故障模型:计算机或者网络发生故障,会影响服务的正确性
故障模型的意义在于将定义可能出现的故障的形式,为分析故障带来的影响提供依据
设计系统时,知道如何考虑到容错的需求 -
安全模型: 分布式系统的模块特性以及开放性,使得它们暴露在内部和外部的攻击之下
安全模型的目的是提供依据,以此分析系统可能收到的侵害,并在设计系统时防止这些侵害的发生
4. 同步、异步两种不同的分布式系统
- 同步系统:有限制的系统
进程执行每一步的时间有个上限和下限
通过通道传递的每个消息在一个已知的时间范围内接收到
每个进程有一个本地时钟,他与实际时间的偏移率在一个已知的范围 - 异步系统:没有限制的系统
进程执行速度
消息传递延迟
时钟漂移率
第三章
1. 事件、进程历史概念

2. 时钟漂移及产生原因
- 时钟是基于固有频率晶体的震荡次数,对计数进行分割产生时间
- 但时钟振荡器在物理上有所不同,震荡频率不同,且时钟频率会随着温度不同而有所差别
- 时钟漂移指与名义上完美的参考时钟之间有所漂移,漂移量即为漂移率
3. 内部、外部物理时钟同步
- 外部同步:采用权威的外部时间源来同步
- 内部同步:无外部权威时间源,系统内时钟同步
4. 时钟正确性含义
- 基于漂移率,即硬件时钟 H 的漂移率在一个已知的范围内,该时钟正确
- 基于单调性,软件时钟中,满足较弱的单调性条件就够了。即时钟 C 与真实时间 t 单调前进
5. 物理时钟同步的三种方法
1、Cristian 方法
- 简单来说就是客户进程根据服务器时间和消息往返时间来设定时钟:T = t(server)+t(round)/2
2、Berkeley 算法
- 主机周期轮询从属机时间–>主机通过消息往返时间估算从属机的时间–>主机计算容错平均值–>
主机发送每个从属机的调整量
3、网络时间协议(Network Time Protocol,NTP)
- 设计目标:可外部同步
使得跨Internet的用户能精确地与UTC(通用协调时间)同步 - 服务器和客户端之间通过二次报文交换,确定主从时间误差,客户端校准本地计算机时间,完成时间同步,有条件的话进一步校准本地时钟频率。
6. 逻辑时间、逻辑时钟
逻辑时间的引入
- 节点具有独立时钟,缺乏全局时钟:后发生的事件有可能赋予较早的时间标记
- 分布式系统中的物理时钟无法完美同步
- 消息传输延迟的不确定性
逻辑时钟
- Lamport(1978)指出:不进行交互的两个进程之间不需要时钟同步,对于不需要交互的两个进程而言,即使没有时钟同步,也无法察觉,更不会产生问题。
- 所有的进程需要在事件的发生顺序上达成一致
7. 发生在先关系、并发关系及分布式系统中的事件排序
- 略
8. Lamport时钟、全序逻辑时钟及向量时钟
-
Lamport时钟

-
全序逻辑时钟:引入了进程标识符

-
向量时钟

9. 割集、割集的一致性、一致的全局状态概念
-
割集:分布式系统所有进程全局历史的子集,是进程历史前缀的并集
-
割集的一致性:割集 C 是一致的,即对于任意事件 e∈C,f→e⟺f∈C,即有果必有因
-
一致的全局状态:对应于一致割集(增量序列)的状态 S0 -> S1 -> S2 -> …(系统的执行可以描述成系统全局状态之间的一系列转换)
10.Chandy-Lamport快照算法
- 简单来说就是用来在缺乏类似全局时钟或者全局时钟不可靠的分布式系统中来确定一种全局状态。
- 算法流程
Initiating a snapshot
- 进程 Pi 发起: 记录自己的进程状态,同时生产一个标识信息 marker,marker 和进程通信的 message 不同
- 将 marker 信息通过 ouput channel 发送给系统里面的其他进程
- 开始记录所有 input channel 接收到的 message
Propagating a snapshot
- 对于进程 Pj 从 input channel Ckj 接收到 marker 信息:
- 如果 Pj是第一次收到marker(还未记录自己的状态),则
- Pj 记录自己的进程状态,同时将 channel Ckj置为空
- 向 output channel 发送 marker 信息
- 否则
- 记录其他 channel 在收到 marker 之前的 channel 中收到所有 message
- 所以这里的 marker 其实是充当一个分隔符,分隔进程做 local snapshot (记录进程状态)的 message。比如 Pj 做完 local snapshot 之后 Ckj 中发送过来的 message 为 [a,b,c,marker,x,y,z] 那么 a, b, c 就是进程 Pk 做 local snapshot 前的数据,Pj 对于这部分数据需要记录下来,比如记录在 log 里面。而 marker 后面 message 正常处理掉就可以了。
Terminating a snapshot
- 所有的进程都收到 marker 信息并且记录下自己的状态和 channel 的状态(包含的 message)
第四章
1. 分布式互斥的含义
- 在分布式系统里,排他性的访问方式,叫做分布式互斥,被这种互斥方式访问的共享资源叫做临界资源。
2. 解决分布式互斥的方法:中央服务器、环、组播+逻辑时钟、Maekawa投票算法
- 中央服务器

- 令牌环

- 组播+逻辑时钟
- 基本思想
进程进入临界区需要所有其它进程的同意
组播+应答,要进入临界区的进程组播一个请求消息,并且只有在其他进程都回答了这个消息时才能进入 - 并发控制
采用 Lamport 时间戳避免死锁,请求进入的消息形如 <T, pi>
T 是发送者的时间戳, pi 是发送者的标识符。
如果请求具有相等的时间戳,那么请求将根据进程的标识符排序。 - 伪码算法
RELEASED 表示在临界区外, HELD 表示在临界区内,WANTED 表示希望进入。

- 基本思想
- Maekawa投票算法
进程进入临界区需要部分其它进程的同意,不必要所有的对等进程都同意。每个进程关联一个选举集,每个选举集有相同数量进程。只要任意两进程使用的子集有重叠,只需要从其对等进程的子集获得进入许可即可
3. 分布式选举含义
- 集群一般是由两个或者两个以上的服务器组建而成,每个服务器都是一个节点。对于一个集群来说,多个节点到底是怎么协调,怎么管理的呢,解决方法是选出一个“领导”来复杂调度和管理其他节点。这个所谓的“领导”,在分布式中叫做“主节点”,而选“领导”的过程叫做“分布式选举”。
4. 解决分布式选举的方法:环、霸道
-
基于环的分布式选举算法
1.进程P构造一个包含自己进程编号的ELECTION给后继进程,如果直接后继进程没有响应,进程P就将消息发送给环上的下一个进程,直到找到一个正常运行的进程。
2.接收到ELECTION 消息的进程将自己的编号增加到ELECTION 消息中,然后按照同样的方式将消息发送给后继进程。
3.这样,消息在环上的传递将构造一个包含所有正常运行的进程的编号表。
4.当ELECTION消息最后回到召集选举的进程时,消息中最大编号的进程即成为选举的胜利者。
5.召集选举的进程将消息类型改为COORDINATOR,然后将消息沿着环重新发送一次,将选举结果通知所有的进程。
6.当COORDINATOR消息重新回到召集选举的进程时,算法终止。
同样,在环选举算法中,也可能同时存在多个召集选举的过程。当在这个时刻环结构不变时,最后的结果也是一致的,只是消息数量多一些,并无大碍。 -
bully算法

5. 基本组播、可靠组播的区别
- 基本组播
原语:B-multicast、B-deliver- A correct process will eventually deliver the msg, as long as the multicaster does not crash.
- B-multicast(g, m):对每个进程p∈g,send(p, m)
- 程p receive(m)时:p执行B-deliver(m)
- 可靠组播
原语:R-multicast、R-deliver- 协定 Agreement
如果一个正确的进程投递消息m,那么group中其它正确的进程终将投递m。
- 协定 Agreement
- 区别
B-multicast 不保证协定(如上)
6. 实现可靠组播的方法
协定表明了 B-Multicast 不能再基于一对一的 send 来实现,因为组播进程在 send 中途出现故障时,会导致剩余进程无法 Deliver 该消息。可行方案如下:
- 用b-multicast实现r-multicast
核心思想是让所有接收进程在 Deliver 之前执行一次 Multicast,即每一个正确接收的进程都作为组播进程的中继。这样即使组播进程中途故障,也会有正确接收的进程发出 Multicast 给剩余进程。缺点是效率低下,同组内 N 个进程都要接收同一个组播消息 N 次。且系统中的所有进程都要实现对重复消息的过滤

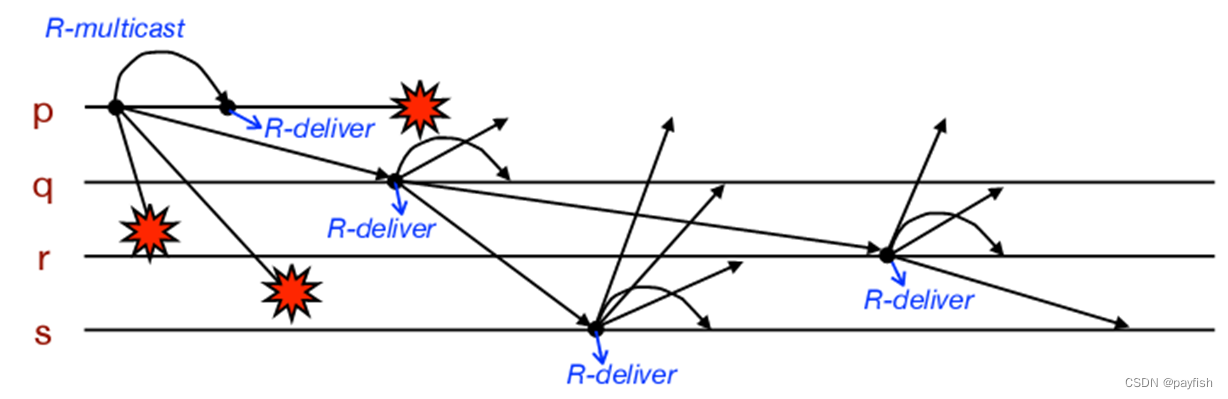
p进程崩溃导致消息到不了r、s进程,但是q进程通过B-multicast将消息发送到了r、s进程
- 用IP组播实现r组播
将 IP组播、捎带确认法、否定确认结合起来,实现可靠的 Multicast 和 Deliver
7. 共识、交互一致性及拜占庭将军问题含义
这三类问题统称为协定,即在一个或多个进程提议了一个值应当是什么后,使系统内所有进程对这个值达成一致的意见。
- 共识
共识问题:一个或多个进程提议一个值后,应达成一致意见- 基本要求
终止性,每个正确的进程最终设置它的决定变量
协定性,如果 Pi 和 Pj 是正确的且已进入决定状态,那么 di=dj
完整性,如果正确的进程都提议了同一个值,那么处于决定状态的任何正确进程都已选择该值
- 基本要求
- 拜占庭问题
- 三将军问题
假设有三个独立的拜占庭将军 A,B,C,他们之间只通过信使进行通信,现在他们需要协商一个问题:明天要进攻还是撤退。这种情况下,为达成一致只需要使用少数服从多数原则,即只要两个人意见相同即可。但不幸的是,三人当中可能会出现叛徒,考虑如下情况,A、B 做出了相反的决策,此时 C 分别向 A、B 发出不同的决策,这就会导致 A、B 采取不一致行动,从而导致失败。可以证明三将军问题是无解的,即无法找出三人之中的叛徒。
- 三将军问题
- 交互一致性
每一个进程提供一个值,最终就一个值向量达成一致- 决定向量:向量中每个分量与一个进程的值对应
可以应用在分布式机器获取其他所有机器的状态信息 - 算法要求
终止性,每个正确进程最终设置它的决定变量
协定性,所有正确进程的决定向量都相同g
完整性,如果进程 Pi 是正确的,那么所有正确的进程都把 Vi 作为他们决定向量中第 i 个分量
- 决定向量:向量中每个分量与一个进程的值对应
8. Raft算法
Raft 算法将系统中的节点分为三种不同的角色:
- Follower:默认节点状态
- Candidate:参选者,即参与竞选 Leader 的节点,会从 Follower 切换为 Candidate
- Leader:竞选成功的节点,会从 Candidate 切换为 Leader
系统中的主要流程如下:
- Leader 会定时(Heartbeat Timeout)向 Follower 发送心跳(Heartbeat),每个 Follower 都维护一个 Random Timeout,每收到一次心跳则重置超时倒计时(Election Timeout)
- Leader Election:任一 Follower 随机一段时间后(Election Timeout,150ms ~ 300ms)没收到心跳则可晋级 Candidate 并启动新的选举,得到多数 Follower 同意的 Candidate 即可当选 Leader,此时任期递增(Term+1)。如果多个 Candidate 同时启动选举,则会等待随机时间重新开始。
- Log Replication:客户端发起的变更操作均请求到 Leader,生成一个 Log Entry 并复制到所有 Follower,完成后 Leader 响应客户端。这样系统状态是一致的
- 网络分区时,系统会出现多个 Leader,当网络分区修复后,任期小的 Leader 会自动下台,小任期下的 Follower 均会回滚自己的 Log Entry 并和有效 Leader 保持一致
这篇关于成电分布式系统复习<上>的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







