本文主要是介绍点餐速度碾压收银员,揭秘阿里云AI点餐机背后的黑科技,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
云栖大会武汉峰会首日,阿里巴巴语音交互首席科学家鄢志杰在现场演示了阿里云AI点餐技术。
先回顾一下当时的场景:
在没有任唤醒词的情况下,客户以每秒5个字的速度,向一台机器点单,并频繁更换语句,这台机器对每次对话均作出了精准应答。

演示结果显示,点34杯咖啡,人工需要两分半的时间,而AI收银员只需要49秒。
相信大家还记得去年12月阿里巴巴对外宣布的上海地铁语音售票概念机,同样是通过语音交互来完成整个购票过程,实际上,二者背后的技术核心都是阿里巴巴多模态语音交互方案。
云栖社区了解到,这套新的方案在技术上的最大突破,是使用了阿里巴巴达摩院机器智能技术实验室全球领先的流式多轮多意图口语理解技术,打破了智能系统常见的“语音唤醒+语音指令”传统命令式交互方式,使得人工智能对人类随意自然的口语表达的理解能力达到了全新的高度。最后,结合商业场景下的业务知识图谱技术,该能力可以迅速复制到交通、新零售、城市服务等各行各业,提供可快速定制的AI语音交互服务。
那么全新点餐机都有哪些亮点呢?以下是阿里巴巴达摩院语音交互团队给出的答案:
语音点餐机解决的是什么业务痛点?市场上的产品有什么问题?
点餐本身,对于很多咖啡师来说,是一项相对枯燥而重复的工作,他们更愿意将时间花在为顾客制作好的咖啡、制作咖啡的时候与顾客沟通了解需求和反馈,而不是将时间花在点餐这件事情上。而对于顾客来说,高峰期的排队问题也让一些顾客十分头疼,很多时间都浪费在咖啡点餐的排队等待上了。
市场上的点餐机,普遍都是触控方式的,不便于顾客快速寻找商品。特别是对于一些客人比较客制化的需求,点起来比较麻烦。
市场上常见的语音交互产品,目前普遍都是“唤醒词+语音指令”的形式,对于比较复杂的需求容易理解不了,并且真正像人与人交流那样做自然交互。
语音点餐机是用来做什么的?
语音点餐机是基于阿里巴巴达摩院机器智能技术实验室的多模态人机语音交互方案的一款典型产品。它以人机交流的方式,能够像与服务员对话一样,实现极为自然的口语化的下单。它解决的最主要问题是在嘈杂的真实餐厅场景下,通过点餐机帮助顾客快速下单,缓解快餐行业在排队高峰期的顾客体验问题。
本次方案的主要亮点是什么?
主要的亮点包括两方面:
一方面是在通过语音、计算机视觉、触控等多模态融合的技术,使得公众空间的人机交互成为可能,并将之落地于业务场景,推进商业化;另一方面,首创流式多意图口语理解引擎,极大地提升了对人类随意、自然的口语表达的理解力,实现人机交流式的语音交互。
本次方案最大的技术突破是什么?
最大的技术突破主要在于流式多意图口语理解引擎,它主要包括三个部分:多模态流式理解、多轮多意图理解、业务知识图谱自适应。
1、多模态流式理解
人类在口语表达的过程中,往往不会完全顺畅和自然,可能会有很多思考、犹豫、停顿和更改。目前业界常见的语音交互系统,实际都只能称为语音指令交互,人通过唤醒词加语音的一句话指令形式,与机器进行交互。而在这个方案里,阿里开创性地利用多模态输入的优势,将除了文本内容以外更多的“元信息”,例如语速语调、字间停顿、发音、气息、面部表情、嘴型、人机距离、场景感知等,应用在后续的语义分割、纠错、补全与消岐等多个复杂环节,得到了比单纯文本信息准确得多的效果,能够做到真正的人机交流式的语音交互,而非传统的唤醒+命令式的语音交互。传统上将语音识别、对话系统等模块简单拼接的交互系统无法做到这样的能力。阿里巴巴的这套人机语音交互系统,实现了语音、视觉等输入模态与口语理解对话系统的深度融合,一改各模块之间简单级联的关系,在对话系统的统筹下进行深度信息交换和决策联合。
通过这套系统,顾客可以用与人交流完全相同的方式去和系统交互,可以把包含多个任务的一长串话语断续地说完,或者干脆一气呵成,也可以自然地想到什么说什么,做到交流中随时纠正、指代、简化表述,甚至不完全准确地陈述。
2、多轮多意图
点咖啡的场景,看似简单实际复杂,且具有典型代表性。每一种咖啡都会附带多个属性、不同种类和属性也会组合成各类复杂的套餐,每个顾客还有自己独特的偏好,有时甚至会提一些店里没有提供的个性化需求。顾客在实际点单过程中,一句多义以及由于不流利带来的多句一义的情况非常常见,如“两杯拿铁,需要做成冷的,少冰加脱脂奶,嗯…然后还要个卡布奇诺,放点焦糖,对了,一杯拿铁在这里吃,其它的带走,哦,都是大杯”。为此,我们通过大量的数据分析、抽象、实验和验证,设计了一套多轮多意图自然口语理解自学习系统,该系统能够在复杂多模态信息的流式输入下,结合上下文动态理解语句,并不断根据最新输入修正此前对意图的判断。
3、业务知识图谱自适应
衡量一套系统价值的另一个重要的点是将它应用在不同领域,不同场景的难易程度。例如我们会关心系统已经在点咖啡领域证明了其有效性,当场景换成了快餐店里的语音点餐、车站机场的交互问询购票、书店药店等零售领域的自助语音购买时,系统能不能适应需求,需要多少迁移工作量。为此我们设计了一套通用的知识图谱处理体系,把整套算法流程所需要用到的领域业务知识,结构化地呈现在知识图谱中,做到了算法与业务领域的隔离,使得绝大多数情况下迁移至新的领域的工作量只剩下根据业务知识设计好知识图谱。而知识图谱的填写被设计成直观的、并不需要任何专业技能就可以完成的任务。除此之外,我们还设计了完善的机制允许业务变现过程中不同层级、具备不同技能的人员均可以利用自已的知识定制,修正系统处理结果。例如除了业务人员外,具备一定编程能力的人员可以把一些复杂不通用的领域独有的知识通过后处理程序加入系统。
这些技术最近有什么新的进展吗?
流式多轮多意图口语理解技术涉及到多个子任务,包括:实体信息抽取(例如产品名),长句语义分割(即将流式口语输入切分为语义完整的句子),意图识别,多元的关系抽取(譬如产品及其属性之间的关系),实体链接,实体指代消解等。这些子任务在学术界都是非常重要的研究课题,也已经有一些比较有效的算法。但是,如果将这些子任务分别实现,然后通过级联的方式串联在一起来解决流式多意图理解问题,会带来三个问题:1 每个子任务均需大量的标注数据,整体的标注压力巨大,难以快速扩展到新的业务。2 每个子任务都可能会产生自身的错误,错误在子任务间传递和积累对最终的系统性能破坏巨大。3 业务知识紧耦合在各个子模块中,系统在不同业务之间的迁移成本巨大。
为了克服级联方式构建系统的问题,我们提出了一个新的系统化的解决方案。首先,该方案是一个端到端的模型,直接对从用户的流式口语输入到对用户多个意图的最终理解进行建模,不再依赖子任务的模型和它们的级联,这样极大的减少了各个子任务之间的错误积累和传递。其次,该方案在架构上将算法和业务分离,使用业务知识图谱有效地表达业务相关的知识,利用序列到序列的深度学习模型自动学习出用户口语输入到意图结构化表达的映射关系, 利用业务知识图谱表达业务逻辑,对于这个自动的映射学习模型进行强化学习以达到弱监督的目的。 这样一方面整个系统只需要少量端到端的数据标注进行训练,大大减少了标注压力; 另一方面由于知识图谱的松耦合度,使得扩展到新的业务变得更为便捷。
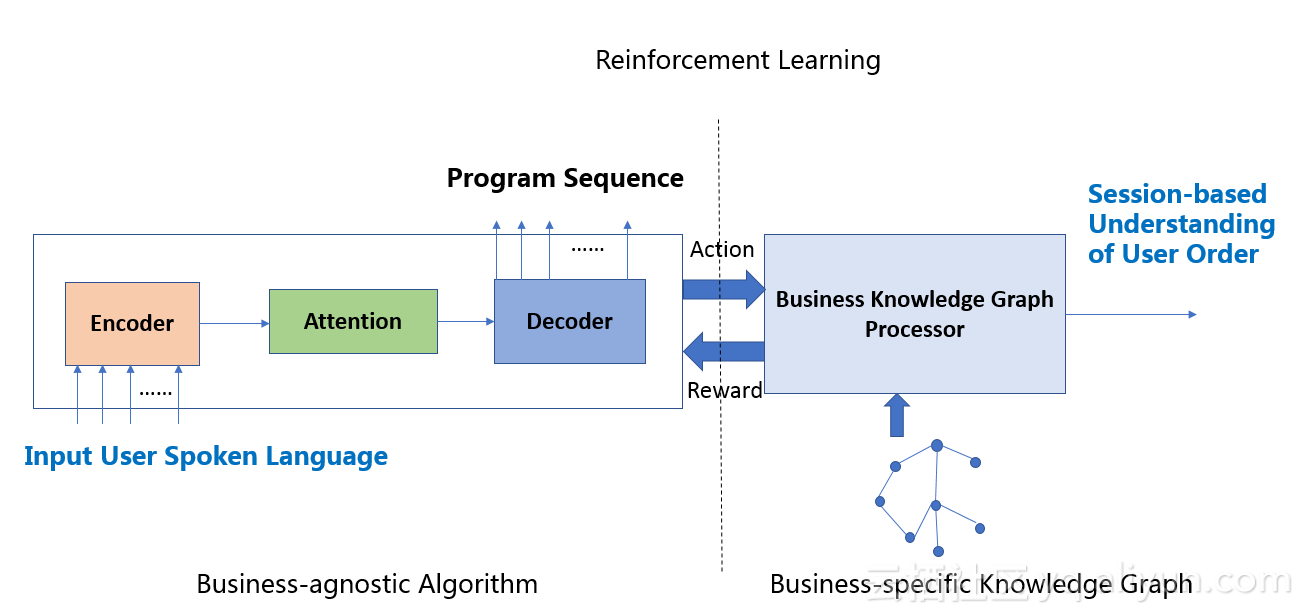
流式多轮多意图口语理解算法架构图
这套方案接下来会在哪些领域做商业拓展?
展望未来,这项新技术可以应用于公共服务(火车站、地铁、机场)、新零售(餐厅、贩卖机、零售店)、企业服务(智能前台、交互式导览)等场景中,如餐厅快速点餐机、咖啡售卖机、公司智能前台、商场导览机、机场问询机等等。
这套解决方案是阿里自主研发的吗?有哪些核心技术?
整套方案完全由阿里巴巴达摩院机器智能技术实验室自主研发,在阿里云做商业化输出。其中包含了机器智能技术实验室在声源定位,语音增强、人脸和图像识别、远场语音识别、语音合成、自然语言处理、流式口语理解、业务知识图谱自适应、长句多意图理解、对话管理、多模态融合人机交互等方面的最新前沿研究成果。而这里的所有核心技术均为阿里巴巴独家/自有专利技术,并将逐步通过学术论文对外公开。
在地铁这类有强噪声的公众场合下,也能够正常使用?是如何做到的?克服了哪些主要技术难点?
阿里达摩院在语音交互研究方向的研究上,一直以来都非常重视强噪声强干扰下的人机交互问题,在车机、家居环境的强噪场景下取得了一系列技术突破。这次针对地铁和咖啡馆这类强噪声环境,首次创新研发了基于机器学习的大型麦克风阵列技术,结合深度优化的声学结构和多模态语音提取,能够自动从强干扰背景语音中提取出目标说话人语音,实现嘈杂干扰环境下的语音识别。并且,针对咖啡馆的咖啡磨豆声和人声,同时进行本地和云端的动态全链路模型匹配,实现端到端的自适应优化,保障每一次顺滑的语音交互。
阿里云的“智能语音交互”已经在智能语音领域做了哪些探索?取得了哪些成绩?
在法庭庭审识别、智能客服、视频审核和实时字幕转写、声纹验证、物联网等多个场景成功应用。全国有近300家法院和超过6000家法庭在使用ET,每年有超过1.2亿次客服电话由ET协助人类接听。
在传统语音交互产品方面,阿里云智能语音交互研究的技术平台能够精准转换用户的语音为对互联网内容和服务的意图,触达手机、IoT设备、互联网汽车、电视、智能音箱等各类终端,如与斑马网络、上汽合作的的荣威互联网汽车、与海尔合作的人工智能电视等。
在下一代人机交互产品方面,已经落地语音售票机于上海地铁让市民使用,并落地真实语音点餐机在阿里园区咖啡馆试运行。这篇关于点餐速度碾压收银员,揭秘阿里云AI点餐机背后的黑科技的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









