本文主要是介绍使用openai的居里模型(curie)进行微调(fine-tuning),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用openai的居里模型(curie)进行微调(fine-tuning)(亲测可用)
- 简介
- OpenAI和GPT系列模型的基本介绍
- 什么是微调(fine-tuning)
- 什么模型可以用来微调
- 微调的基本步骤
- 实现过程
- 环境准备
- 1、linux环境下安装OpenAI命令行界面(CLI)
- 2、设置环境变量
- 3、准备训练数据
- 4、创建微调模型
- 4、使用创建好的微调模型
- 删除微调模型
简介
OpenAI和GPT系列模型的基本介绍
OpenAI是一家人工智能研究实验室,由Elon Musk、Sam Altman等多位知名创业者和科学家在2015年共同创立。OpenAI的目标是确保人工通用智能(AGI)的发展能够惠及全人类。他们承诺将以尽其所能的方式避免使人工通用智能成为几个控制权集中的实体使用的工具,并且如果出现与OpenAI价值观相符的安全和价值导向的竞争项目,则OpenAI会停止竞争并开始协助该项目。
GPT系列模型是OpenAI开发的一种大型自然语言处理模型。“GPT"代表"生成预训练 Transformer”,这种模型通过预训练和微调两个阶段进行训练。在预训练阶段,模型学习预测来自Internet的文本数据中的下一个字词;在微调阶段,模型进一步在特定任务的标注数据上进行训练以优化性能。GPT-1、GPT-2和GPT-3就是这个系列的三个版本,每个新版本的模型都比前一个版本有着更多的参数和更强大的性能。
什么是微调(fine-tuning)
微调(fine-tuning)是机器学习中一个常见的概念,它所指的是在预训练模型的基础上进行的二次训练。预训练模型通常在大规模的数据集上进行训练,以抓取一种普遍的、底层的特征表示。然后,微调通过在具体任务相关的小规模数据集上进一步训练预训练模型来适应特定的任务。
与全新训练相比,微调有以下几个主要区别:
数据需求:微调需要的数据量较少,因为预训练模型已经在大规模的数据集上学习了丰富的特征表示。而全新训练需要大量的标注数据。
训练时间和计算资源:微调通常需要的训练时间和计算资源较少,因为它只需对预训练模型进行轻微的调整。反观全新训练,由于需要从零开始学习所有的特征表示,因此需要更多的时间和计算资源。
性能:预训练模型有助于提高模型性能,尤其在数据稀缺的情况下,因为预训练模型捕获的底层知识可以迁移到特定的任务中。全新训练的模型可能无法达到同样的性能,除非有足够的数据进行训练。
可泛化性:预训练模型由于在大规模数据集上经过训练,其学习到的特征表示具有良好的可泛化性,使得它们能够适应各种不同的任务。全新训练的模型则只专注于特定任务的数据,而这些数据可能不足以提供广泛的特征表示。。
什么模型可以用来微调
目前,微调仅适用于以下基础模型:davinci、curie、babbage、ada
注意:2023年7月6日,OpenAI宣布停用ada、babbage、curie和davinci模型。这些模型,包括经过微调的版本,将于2024年1月4日关闭。OpenAI正在积极努力实现对升级版GPT-3模型以及GPT-3.5 Turbo和GPT-4进行微调的功能,并建议等待这些新选项可用后再进行微调,而不是基于即将被弃用的模型。
微调的基本步骤
- 准备并上传训练数据
- 训练一个新的微调模型
- 使用训练好的微调模型
实现过程
环境准备
我们在实现微调的过程中,使用到了下面这些环境或者准备:
- OPENAI_API_KEY :使用openai的fine-tuning功能必须拥有OpenAI的API秘钥,获取的方法在网上有很多;
- Linux服务器 我所使用的Linux服务器为centos8的系统;
1、linux环境下安装OpenAI命令行界面(CLI)
pip install --upgrade openai
2、设置环境变量
在使用OpenAI的微调命令之前,你需要配置 OPENAI_API_KEY 环境变量。这有两种可选方法:
使用以下命令在每次登录服务器后初始化环境变量:export OPENAI_API_KEY="<OPENAI_API_KEY>"。请注意,此方法仅对当前会话有效,下次登录时还需重新设置。
将 OPENAI_API_KEY 设置为系统级环境变量。将上述命令添加到/etc/profile 文件的末尾,然后执行
source /etc/profile 命令让修改生效。
3、准备训练数据
① 训练数据格式要求
数据必须是一个JSONL文档,其中每一行都是一个prompt和completion值对。下面是JSONL数据格式例子:
 由于JSONL格式的数据不便于我们集成,OpenAI提供了一个工具来验证、提供建议和重新格式化我们的数据,此工具允许我们将CSV、TSV和XLSX等三种格式的文件转换为OpenAI可接受的JSONL格式。我们准备的文件需要有两列:‘prompt’(我们要问的问题)和 ‘completion’(我们期望模型的回答)。准备好数据后,执行以下命令:
由于JSONL格式的数据不便于我们集成,OpenAI提供了一个工具来验证、提供建议和重新格式化我们的数据,此工具允许我们将CSV、TSV和XLSX等三种格式的文件转换为OpenAI可接受的JSONL格式。我们准备的文件需要有两列:‘prompt’(我们要问的问题)和 ‘completion’(我们期望模型的回答)。准备好数据后,执行以下命令:
// <LOCAL_FILE> 为需要转换的文件的路径
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
运行此命令后,该工具会解析指定文件(CSV、TSV、XLSX),并生成一个.jsonl格式的文件。这个文件就是预处理完成的数据,可以直接用于模型微调。
说明:训练样本越多,效果就越好。数据集大小每翻倍,模型质量线性增加,但是同时训练样本越多, 成本也越高,请根据自己的需求去选择样本数据。
4、创建微调模型
我们需要使用 OpenAI CLI 去创建我们的微调模型,执行以下命令:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
其中 BASE_MODEL是基础模型的名称(ada、babbage、curie 或 davinci)。您可以使用后缀参数自定义微调模型的名称。
运行上面的命令会做几件事:
- 使用文件 API上传文件(或使用已经上传的文件)
- 创建微调作业
- 流式传输事件直到作业完成(这个过程可能比较久,官方文档说可能只需要几分钟或者几小时,我当时是超过了一天才完成,,耐心等候即可)
我们也可以在创建微调模型时使用更多的高级参数来让我们的,模型达到更加理想的效果,也就是说,调整用于微调的高级参数通常可以产生产生更高质量输出的模型。特别是,您可能需要配置以下内容:
model:要微调的基本模型的名称。您可以选择“ada”、“babbage”、“curie”或“davinci”之一。要了解有关这些模型的更多信息,请参阅模型文档。n_epochs默认为 4。训练模型的时期数。一个纪元指的是训练数据集的一个完整周期。batch_size默认为训练集中示例数量的 0.2%,上限为 256。批量大小是用于训练单个正向和反向传递的训练示例数。总的来说,我们发现更大的批次大小往往更适用于更大的数据集。learning_rate_multiplier默认为 0.05、0.1 或 0.2,具体取决于 final batch_size。微调学习率是用于预训练的原始学习率乘以该乘数。我们建议使用 0.02 到 0.2 范围内的值进行试验,以查看产生最佳结果的值。根据经验,我们发现较大的学习率通常在较大的批量大小下表现更好。compute_classification_metrics默认为 false。如果为 true,为了对分类任务进行微调,在每个 epoch 结束时在验证集上计算特定于分类的指标(准确性、F-1 分数等)。
我们可以在 OpenAI CLI 上的命令行添加请求参数来配置这些额外的高级参数,例如:
openai api fine_tunes.create \-t file-JD89ePi5KMsB3Tayeli5ovfW \-m ada \--n_epochs 1
可以使用以下命令来查看所有自己所创建的微调模型:
openai api fine_tunes.list
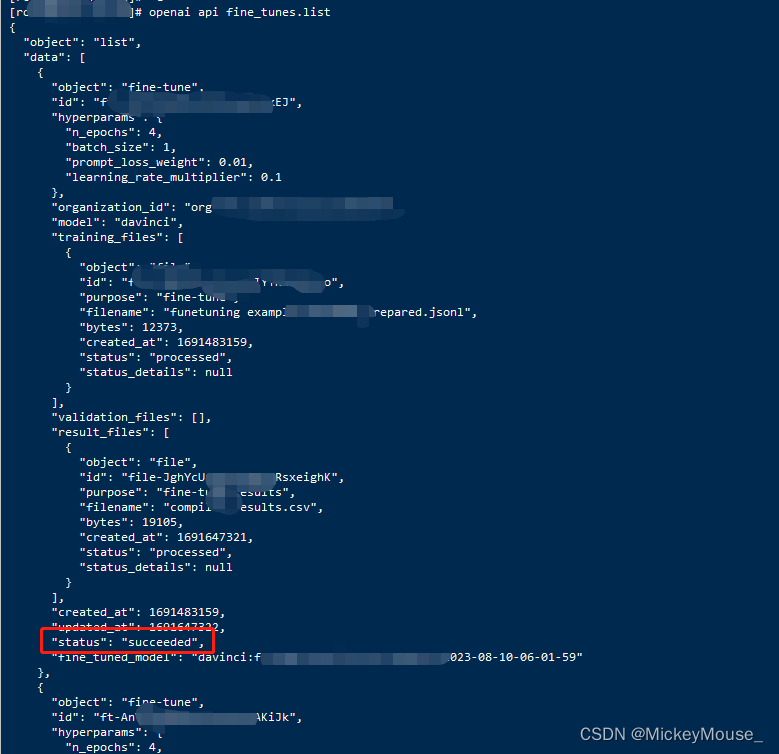
如图所示,status表示当前模型的状态,在创建完成之前他的状态是pendding,success则表示微调模型已经创建成功,即可开始使用,fine_tuned_model即表示我们的微调模型的名称。
4、使用创建好的微调模型
当作业成功后,我们就可以将此模型指定为我们的 Completions API 的参数,并向它发出请求。我们可以登录openai,然后在Playground发请求,也可以直接使用命令行的形式发送请求,这里使用命令行为例:
curl https://api.openai.com/v1/completions \-H "Authorization: Bearer $OPENAI_API_KEY" \-H "Content-Type: application/json" \-d '{"prompt": YOUR_PROMPT, "model": FINE_TUNED_MODEL}'
我们也可以在请求中添加其他参数,比如temperature、frequency_penalty、presence_penalty等,请求如下:
{"id": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7","object": "text_completion","created": 1589478378,"model": "gpt-3.5-turbo","choices": [{"text": "\n\nThis is indeed a test","index": 0,"logprobs": null,"finish_reason": "length"}],"usage": {"prompt_tokens": 5,"completion_tokens": 7,"total_tokens": 12}
}
id(string): 完成的唯一标识符。object(string): 对象类型,始终为 “text_completion”。created(integer): 完成创建时间的 Unix 时间戳。model(string): 用于完成的模型。choices(array): 模型针对输入提示生成的完成选项列表。每个选择包含一个 ‘text’ 子字段。text(string): 完成的文本。
-index( integer)logprobs(object or null)finish_reason(string)finish_reason(string): 模型停止生成令牌的原因。如果模型达到了自然停止点或提供的停止序列,该值会是 “stop”;如果达到了请求中指定的最大令牌数量,该值会是 “length”。usage(object): 完成请求的使用统计信息。此对象包含有如下子字段:prompt_tokens(integer): 提示中的令牌数量。completion_tokens(integer): 生成的完成中的令牌数量。total_tokens(integer): 请求中使用的总令牌数量(提示 + 回答)。
删除微调模型
删除微调模型有两中方式:
- 使用OpenAI CLI命令行的方式:
openai api models.delete -i <FINE_TUNED_MODEL>
- 使用 cURL:
curl -X "DELETE" https://api.openai.com/v1/models/<FINE_TUNED_MODEL> \-H "Authorization: Bearer $OPENAI_API_KEY"
这篇关于使用openai的居里模型(curie)进行微调(fine-tuning)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




