本文主要是介绍ObjectBox: From Centers to Boxes for Anchor-Free Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ObjectBox: From Centers to Boxes for Anchor-Free Object Detection
ECCV2022 oral
paper:https://arxiv.org/abs/2207.06985
code:https://github.com/MohsenZand/ObjectBox
摘要
本文提出了 ObjectBox,一种新颖的单阶段Anchor-free且高度通用的目标检测方法。与现有的Anchor-based和Anchor-free的检测器相比,原有方法在标签分配中更偏向于特定的目标尺度,ObjectBox仅使用目标中心位置作为正样本,并在不同的特征级别平等对待所有目标,而不管物体的大小或形状。具体来说,ObjectBox的标签分配策略以Anchor-free的方式将目标中心位置视为与形状和大小无关的Anchor,并允许在每个目标的所有尺度上进行学习。为了支持这一点,将新的回归目标定义为从中心单元位置的2个角到边界框4个边的距离。此外,为了处理尺度变化的目标,作者提出了一种定制的 IoU 损失来处理不同大小的框。因此,本文提出的目标检测器不需要跨数据集调整任何依赖于数据集的超参数。
在 MS-COCO 2017 和 PASCAL VOC 2012 数据集上评估ObjectBox,并将结果与最先进的方法进行比较。ObjectBox 与之前的作品相比表现得更好。
介绍
当前最先进的目标检测方法,无论是两阶段还是单阶段方法,都假设边界框,为每个框提取特征,并标记目标类别。他们都对共享的局部特征进行边界框定位和分类任务。一种常见的策略是在卷积特征图上使用手工制作的密集Anchor来为共享的局部特征生成丰富的候选框。这些Anchor生成边界框大小和纵横比的一致分布,这些分布是基于目标和Anchor之间的IoU分配的。
anchor-based方法因为在目标检测中的效果而占据主导地位,但是有明显的缺点。
- 首先,使用先验anchor会引入额外的超参数来指定大小和纵横比,会削弱对其他数据集的泛化能力
- 其次,定位时必须密集的覆盖图像,以最大限度的提高召回率,然而只有少数anchor与gt重叠,导致正负样本的巨大不平衡,需要采取其他措施解决,增加了额外的计算成本
- anchor box必须根据数据集设计数量、比例、纵横比,该参数的变化很大程度上影响到模型的性能
为了应对以上问题,开发了许多anchor-free检测器,分为keypoint-based和center-based方法。
- keypoint-based:使用关键点定位对象,例如中心点和角点,并将其分组以限制对象的空间范围,然而需要复杂的组合分组算法
- center-based:使用ROI区域和中心位置来定义正样本,直接回归边界框
 有研究表明,在center-based方法中,anchor-based和anchor-free之间的主要区别为正负样本的定义,为了区分正负样本:
有研究表明,在center-based方法中,anchor-based和anchor-free之间的主要区别为正负样本的定义,为了区分正负样本: - anchor-based方法使用IoU在空间和尺度维度上选择正样本
- anchor-free方法使用空间和尺度约束,首先在空间维度中找到候选正样本,然后在尺度维度中选择正样本
然而两种方法都需要施加约束阈值来划分正负样本,忽略了一个事实,即对于不同大小、形状或遮挡条件的对象,最佳边界可能会有所不同。
本文中平等地对待所有尺度中的所有对象,只从对象的中心位置进行回归。为了支持这一点,我们将新的回归目标定义为从包含对象中心的网格单元的两个角到边界框边界(L/R/B/T)的距离。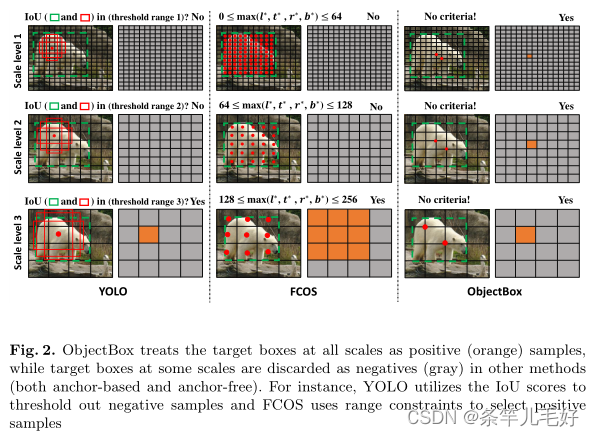
本文贡献为提出了一种新型的anchor-free目标检测器ObjectBox,能更好地处理标签分配问题。此外该方法即插即用,可轻松用于各种数据集。更具鲁棒性和通用性,并获得最先进的结果。
相关工作
anchor-based目标检测器
为了以不同的纵横比在不同的尺度上定位对象,faster R-CNN引入anchor box作为固定大小的bounding box方案。anchor box背后的基本原理是使用一组预定义形状(即尺寸和纵横比)作为bounding box proposal,这一想法在其他对象检测方法中已变得常见。
为了实现实时性能,一阶段检测器使用anchor,在一次预测中直接预测bounding box和类概率,最具代表性的是SSD、RetinaNet和YOLO。
anchor-free目标检测器
anchor-based方法需要预定义产参数来指定anchor box的大小和纵横比。指定这些超参数需要启发式调优和经验技巧,并且依赖数据集分布,缺乏通用性。提出achor-free方法克服anchor box的缺点。
keypoint-based方法检测特定的对象点,例如中心点和角点,并将其分组以进行bounding box预测。尽管与anchor-based的方法相比,它们的性能有所提高,但分组过程耗时,并且通常会导致较低的召回率。一些代表性示例包括CornerNet[、ExtremeNet、CenterNet和CentripetalNet。
center-based方法使用ROI区域或中心位置来确定正样本,这使得它们与基于固定的方法更具可比性。例如,FCOS将对象边界框内的所有位置都视为候选正值,并在每个比例维度中找到最终正值。它计算了从这些正位置到边界框四边的距离。然而,它从远离对象中心的位置生成了许多低质量的预测边界框。为了抑制这些预测,它使用中心度分数来降低低质量边界框分数的权重。此外,它利用5级FPN(特征金字塔网络)在不同级别的特征地图上检测不同大小的对象。中心凹框预测了物体中心可能存在的位置,以及每个正位置的边界框。FSAF(特征选择无锚)将anchor-free分支连接到RetinaNet中特征金字塔的每一层。
标签分配
有研究表明,如果使用相同的标签分配策略,则anchor-based和anchor-free方法可以获得近似的结果。在标签分配中,每个特征映射点根据对象的真实度和分配策略标记为正负。
ATSS(自适应训练样本选择)提出了一种基于对象统计特征的动态策略。通过从检测器模型计算anchor分数并最大化概率分布分数的可能,将anchor分配建模为概率过程。
OTA(最优运输分配)提出将标签分配表述为最优运输问题,将每个gt描述为特定数量标签的供应商,并将每个anchor定义为需要单元标签的需求者。如果一个anchor从给定gt获得足够多的正标签,将被视为该gt的一个正anchor。
然而这些策略不能保持不同对象之间的平等,往往会为较大的对象分配更多的正样本。
Objectbox
基于对象中心位置的标签指定
输入图像中具有中心(x,y)的边界框可以使用其角点定义(x1,y1)(x2,y2),表示该尺度中左上角和右下角各自的坐标。
预测了3种不同尺度下的边界框,以处理对象尺度变化。

将中心映射到尺度i的中心位置,计算从右下角到左和上边界(L和T)的距离,以及从左上角到右和下边界(R和B)的距离:
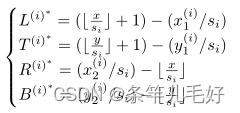
对应的预测如下:
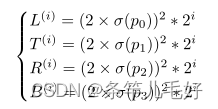
其中σ表示sigmoid函数,(p0,p1,p2,p3)表示网络对距离值的预测,乘以很顶的比例增益来区分不同的比例。整体网络输出包括每个比例的每个位置的预测
公式确保了在不同条件下回归的所有距离都为正,如图3(b)所示,对于较大步幅完全包含在网格内的小物体,也可以将4个距离计算为正值,我们将所有对象视为不同尺度下的正样本。因此无论对象大小,它都从所有尺度中学习,以从多个层次实现更可靠的回归。由于ObjectBox只考虑每个对象的中心位置,每个对象的正采样数与对象大小无关。
本文方法通过使用每个尺度上边界框的中心位置来为每个对象生成多个预测。
box回归
由于{L,T,R,B}是距离,可以使用均方误差分别及逆行回归,然而这种策略将忽略bounding box的完整性。提出IoU损失,以考虑预测和gt区域的重叠。
在本文的例子中,感兴趣的是最小化两个box的距离,每个box由4个距离值给出。当我们从具有不同大小的对象的不同尺度中学习时,bounding box回归损失应该是尺度不变的。
提出了一种根据本文方法定制的IoU损失,该损失也可以改进其他的anchor-free检测器。本文提出的损失是SDIoU,代表基于尺度不变距离的IoU,直接应用于网络输出,即对象中心到左上角和右下角的距离。
与CIoU类似,考虑了非重叠区域、重叠和相交区域以及最小的包围区域。
首先计算非重叠面积S:
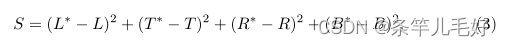
通过计算相交区域对角线长度平方来获得相交区域I:

w和h分别是交叉区域的宽和高:
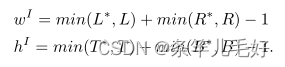
覆盖预测和gt的的最小面积由通过其长度的平方计算:

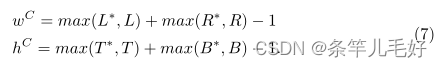
通过最小化C,预测box可以在4个方向上向gt移动,最终将SDIoU计算为:


实验
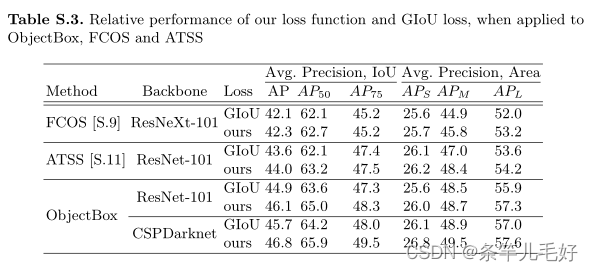
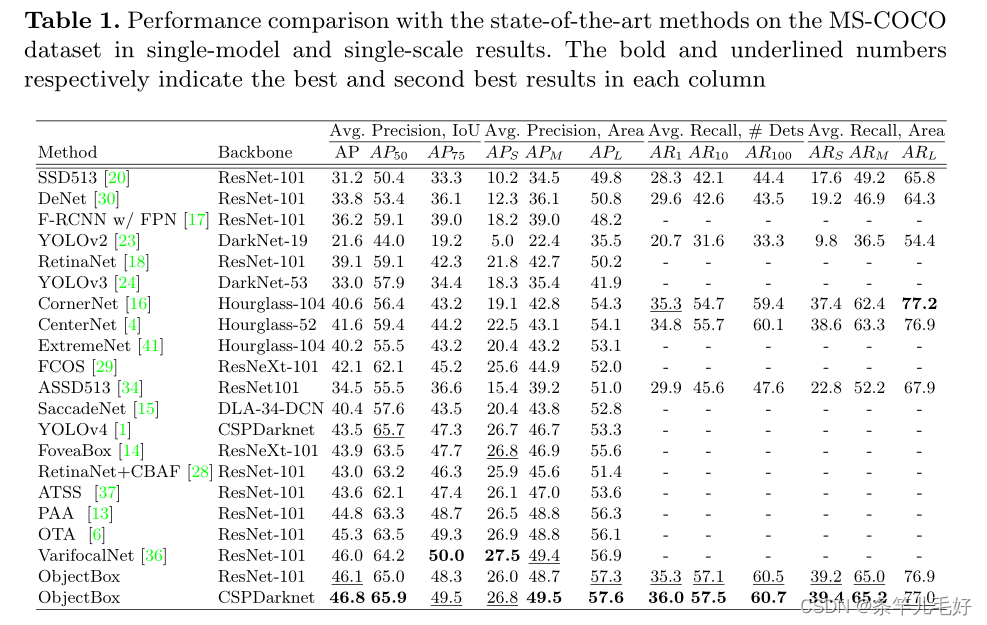 ObjectBox更加准确,使用CSPDarknet主干实现了46.8%的最佳AP性能。我们的方法在使用ResNet-101主干网时也达到了46.1%的次优性能。
ObjectBox更加准确,使用CSPDarknet主干实现了46.8%的最佳AP性能。我们的方法在使用ResNet-101主干网时也达到了46.1%的次优性能。
召回率的改进表明,本文方法可以检测更多的容易重叠的小目标。
消融实验
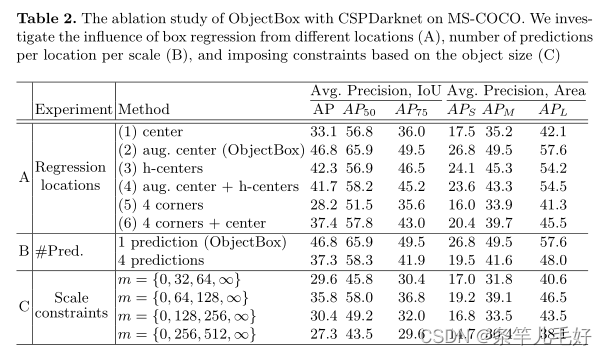
表2A通过选择从不同位置回归box,展示了不同位置回归的影响。定义了6种情况:
- 只有一个位于中心的位置
- 中心位置与邻近位置一起(ObjectBox)
- 框中心与左上角和右下角两个点之间的连接线的中心点(h-centers)
- (2)中的中心位置加上(3)中的所有位置(aug. Center + h-centers)
- 边框的四个角
- (5)中的角点加中心位置
表2B分析了每个位置的预测数量的影响,当在每个位置预测4个box时,性能下降
表2C显示不同尺度对特征图的影响
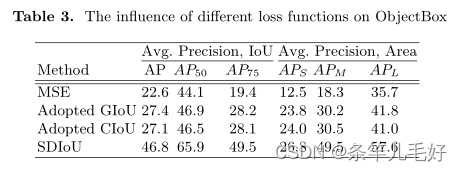
证明SDIoU的有效性
结论
ObjectBox是一种无锚对象检测器,无需任何超参数调整。它使用对象中心位置,并使用新的回归目标进行边界框回归。此外,通过放松标签分配约束,它在所有特征级别中平等地对待所有对象。量身定制的IoU损失还可以最大限度地减少新回归目标与预测目标之间的距离。事实证明,与其他基于锚和无锚的方法相比,使用现有主干架构(如CSPDarknet和ResNet-101)的ObjectBox更具优势。
补充


这篇关于ObjectBox: From Centers to Boxes for Anchor-Free Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





