本文主要是介绍查询多对多关系的数据时避免出现重复,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据的关系有三种,一对一、一对多以及多对多。处理难度上多对多的关系的数据是最难处理的,多对多的关系一般用在一些类型上,例如一个客户对应多个客户类型,一个类型又可以对应多个客户,这样就形成了多对多关系了。多对多关系在查询数据时一般回查出多条数据,就例如上面的客户以及客户类型,一般显示到页面时每个客户只需要出现一次就行,但是又要显示出所有的客户类型。但是如何按一般的联表查询得到的结果就是该客户有多少个客户类型就会显示有多少条该客户的信息。就如下图所示,中谷新良这个客户有三个客户类型,而这个公司就出现了三遍。

因为不需要客户出现多次,所有接着需要做的就是把重复的客户去除掉,把客户类型拼接起来集中显示到一条该客户的信息上。
首先,要连表查询出每个客户的客户类型,也就是说每条数据都必须要有客户ID和客户类型两个字段。

然后需要声明三个变量,一个是存放客户类型的,就是把每个客户的客户类型处理好了之后临时存放到这个变量里面;第二个是存放客户ID的,这个变量主要是用来筛选客户的,这是去重复了的核心代码;第三个变量是一个列表,把最终处理好的客户以及客户类型放到里面,供后续操作继续使用,是连接的桥梁。
CustomerVo是实体类,自己创建的,内容根据实际添加。

接着就可以对上面查询出来的数据进行处理了,处理时需要用到两个foreach循环,而且属于嵌套关系,循环的内容都是上面查询出来的每个客户的客户类型。第一个foreach循环是为了筛选客户的,第二个foreach循环是为了筛选客户类型的。先看看第二个foreach循环,一进去到第二个foreach循环就立马要进行判断,如果第一个循环的客户ID等于第二个循环的客户ID就可以进行客户类型的拼接,因为既然客户ID相等了那这个客户类型肯定就是该个客户的了。
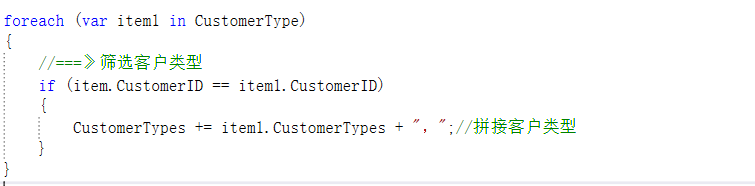
拼接完成后,就要对上面声明的几个变量进行处理,处理这几个变量的地方一定是要在第二个循环的外面,因为客户类型是要显示到页面上的,为了美观一般都会去掉最后一拼接的符号。
然后就要为列表添加数据了,客户类型添加的是第一个循环的客户ID,类型是拼接好的客户类型。添加完成后就要吧客户类型这个变量清空,避免影响下一次的操作。最后把客户ID拼接上,这时为了在第一个循环里进行判断是否已经处理过该客户。

图中红色圈内的是筛选客户的操作,也就是去重复,首先要把拼接好的客户ID分割成数组形式,再利用Contains这个属性去判断该次的客户是否在该数组中,存在返回true,不存在返回false,如果存在就不进行任何操作,不存在就继续进行第二个循环。使用Contains一定要注意,该数组一定是一个字符串数组,而且前面要要IList这个属性,否则是使用不了的。

然后就可以接着在下面正常的连表操作了,但是需要查询客户类型是就需要连处理好的那张表,就是listCustomerType这张。
处理好之后就是这样子的

这篇关于查询多对多关系的数据时避免出现重复的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






