本文主要是介绍otp语音芯片20秒40秒80秒160秒长度是什么意思 为什么会有秒数区分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、OTP语音芯片秒数简介
关于语音芯片OTP类型的芯片,基本都是sop8封装的,其中有个参数很奇怪,就是他分了好多种语音长度,比如:20秒、40秒、80秒、160秒、320秒等等 。而flash型的语音芯片KT148A支持420秒,就不分秒数,用户可以自行重复更换语音,很方便
OTP的工艺
传统的OTP语音芯片,基本都是台系的,他们的技术还是停留在10年前:OTP工艺,8寸晶圆,原因也很简单
flash型的介绍和展望
而目前flash型的语音芯片,就完美的解决这个问题,以及这些看似合理,实际不合理的产品定位
一、OTP语音芯片秒数简介
关于语音芯片OTP类型的芯片,基本都是sop8封装的,其中有个参数很奇怪,就是他分了好多种语音长度,比如:20秒、40秒、80秒、160秒、320秒等等 。而flash型的语音芯片KT148A支持420秒,就不分秒数,用户可以自行重复更换语音,很方便
一开始,我很不理解,为什么要做这样的区分
因为一旦种类多了之后,无论是仓储,烧录,样品,售前乃至售后,都会是一件很麻烦的事情,相当于同一款芯片,最后定义就会有七八个型号,甚至更多,好麻烦
后来仔细看了之后,发现这个不同秒数的价格还相差很大,基本上秒数越长,价格都是成本的增长,这明显不符合逻辑
因为从技术的角度,做到统一,这个问题应该是很好解决的
1、就像市面上的一些单片机,内部的晶圆实际是一样,但是在出厂的时候,通过烧录软件把多余的空间给封闭起来,不让用,从而区分出来不同的产品类别,然后实现阶梯性的定价策略,容量最大的比容量最小的,价格高那么一点点
2、因为芯片晶圆在生产阶段,讲究的就是一个量,以及生产周期过长,只能说优化工艺,然后累积更多的量去下单,才能降低生产成本。
3、典型的就是:宏晶STC系列的MCU,型号:STC89C52和STC89C512 ,就是这么干的
-
OTP的工艺
传统的OTP语音芯片,基本都是台系的,他们的技术还是停留在10年前:OTP工艺,8寸晶圆,原因也很简单

第一、就是这玩意单价太低,利润还行,但是不足以支撑好的生产工艺,以及设计工艺
第二、搁在10年前,这类型的产品,其实出货量很大,但是现在全世界消费水平的提升,一些低端的产品都用上了更好的芯片,所以这类型的OTP芯片,明面上数量还在增长,但是利润是逐年逐年的降低的,属于夕阳产品,但是又不可或缺
第三、所以对于芯片原厂来说,就没有必要去更新工艺,或者说投入资源去研发,已经足够使用了
剩下的就是拼价格,大家都卷起来
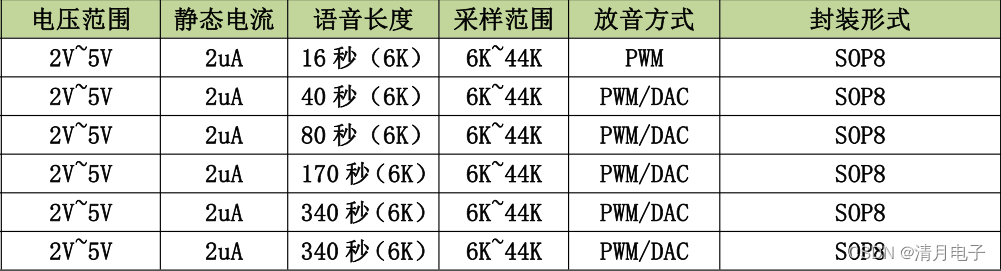
1、其中20秒、40秒、80秒之类的指标,其实都是最低采样率的存储长度
并且播放出来的声音,效果其实是很差的,也就是说,标注的20秒语音空间,要稍微好一点的音质,存储容量基本上只够支撑12秒左右的语音长度
2、并且20秒的芯片晶圆,和40秒的芯片晶圆,他还不一样。目的肯定是为了省成本
但是实际真正落实到芯片的成本上,相差不了多少的,可是最终的售价,就差很远了,典型的低秒数引流,高秒数搏利润的模式
-
flash型的介绍和展望
而目前flash型的语音芯片,就完美的解决这个问题,以及这些看似合理,实际不合理的产品定位
因为flash的工艺已经是足够成熟,足够量大,工艺也是在逐年的更新,它是基础产品,就像电阻电容一样,哪里都需要用到,量也是逐年逐年的增长,属于稳定、成长类型的好产品,看看GD的上市财报就知道了,摇钱树一样的存在
所以将一颗spiflash合封到语音芯片里面去,不仅不会增加太多成本,反而可以实现产品的高度统一,规模化提升效率
这样设计的语音芯片,就不会存在多少秒数的区别,一开始定义就是为了最大秒数的存在
因为足够标准,足够统一,所以围绕芯片本身成本之外的成本,就可以分摊得足够低,以后只会更低
这样的思路才是一个好产品,无其他 ,正如:KT148A-SOP8语音芯片一样
当然,合适才是最重要的一件事,一些需要低秒数的产品定位,还是推荐OTP,因为他便宜,够用 。这个就需要自己去仔细的选型和对比挑选了
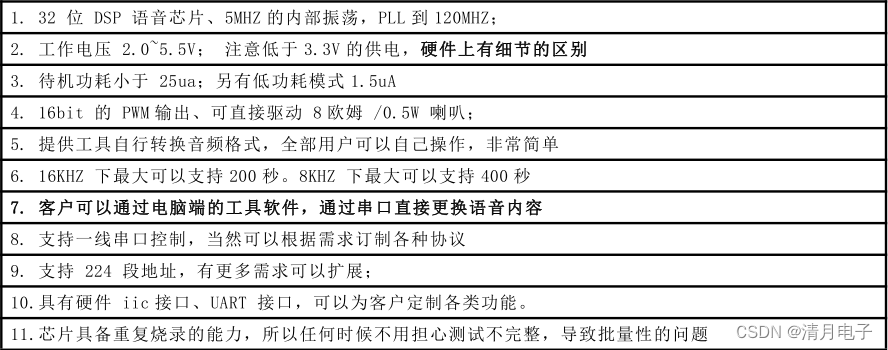
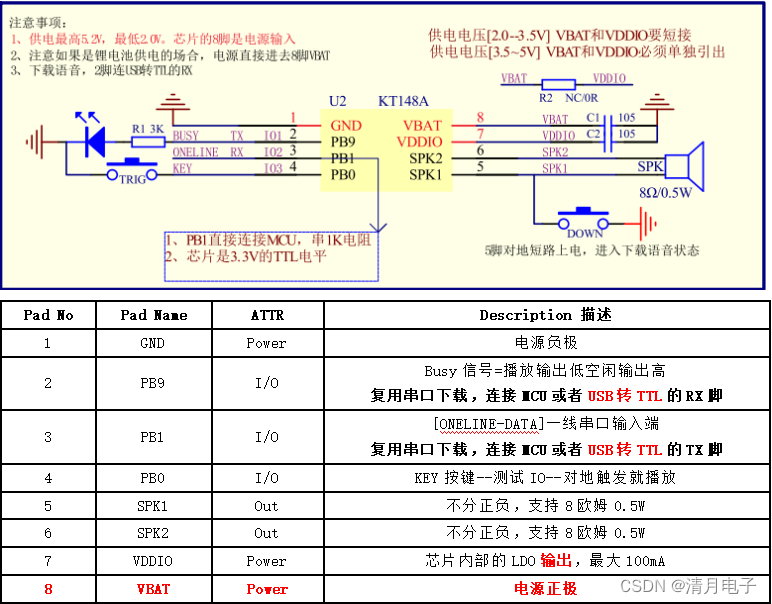
KT148A是一款32位的DSP语音芯片,标准的SOP8封装。内置420KByte的语音空间,最大支持420秒的语音长度,支持多段语音,同时支持直驱0.5W的扬声器,支持用户更换语音,目前该芯片的优势如下:
1、性价比高,相比较传统的OTP芯片来说,工艺的提升大大降低了成本,同时芯片可重复烧录
2、用户可以自行的更换声音,通过电脑端的串口即可自己完成,无需其他昂贵的工具
3、芯片自带足够的空间,可以追求更高的音质效果
这篇关于otp语音芯片20秒40秒80秒160秒长度是什么意思 为什么会有秒数区分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






