本文主要是介绍深度学习七日打卡营day02(2)十二生肖图片分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学会了用初级网络LeNet进行手写数字识别的训练,下面我们用更高级的网络进行十二生肖分类的任务
课程链接:深度学习七日打卡营
深度学习七日打卡营第二天(2)
- 1.高级卷积神经网络简介
- LeNet
- AlexNet
- VGG
- GoogleNet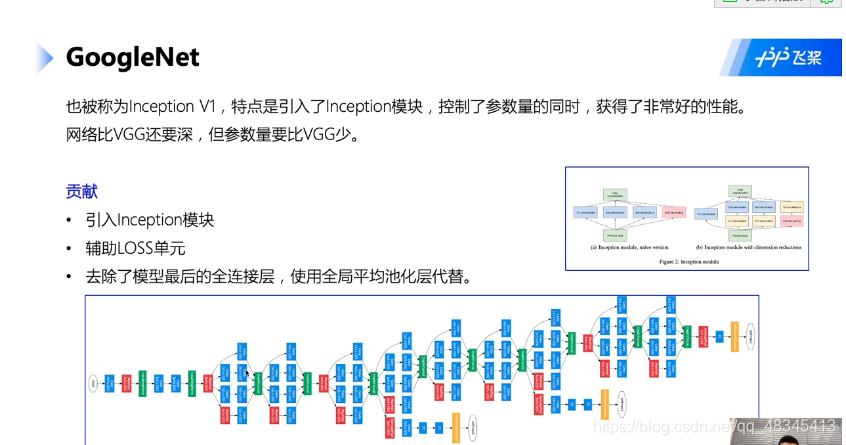## ResNet
- 2.十二生肖分类
- 2.1 数据准备
- 2.1.1数据标注
- 2.1.2 数据集定义
- 2.2网络搭建
- 2..2.1ResNet50网络介绍
- 2.2.1.1 系列网络
- 2.2.1.2 网络结构
- 2.2.1.3 残差区块
- 2.2.1.4 ResNet网络其他版本
- 2.2.2 网络构建
- 2.2.3 网络结构可视化
- 2.3 模型训练优化
- 2.4 保存模型
- 2.5 模型评估测试
- 2.6 模型部署保存
- 总结
1.高级卷积神经网络简介

LeNet

AlexNet
VGG

GoogleNet ## ResNet
## ResNet

2.十二生肖分类
下面开始用ResNet50网络进行十二生肖图像分类任务的实现
2.1 数据准备
!unzip -q -o data/data68755/signs.zip
数据集为已经准备好的数据集,上传的压缩包,我们先对数据进行解压
2.1.1数据标注
解压后的数据集如下所示,为让计算机识别到每一幅图对应的标签,我们应对其进行数据标注操作
├── test
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
├── train
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
└── valid├── dog├── dragon├── goat├── horse├── monkey├── ox├── pig├── rabbit├── ratt├── rooster├── snake└── tiger
代码如下:
#导入相关库
import os
from PIL import Image
from config import get# 数据集根目录
DATA_ROOT = 'signs'# 标签List
LABEL_MAP = get('LABEL_MAP')# 标注生成函数
def generate_annotation(mode):# 建立标注文件with open('{}/{}.txt'.format(DATA_ROOT, mode), 'w') as f:# 对应每个用途的数据文件夹,train/valid/testtrain_dir = '{}/{}'.format(DATA_ROOT, mode)# 遍历文件夹,获取里面的分类文件夹for path in os.listdir(train_dir):# 标签对应的数字索引,实际标注的时候直接使用数字索引label_index = LABEL_MAP.index(path)# 图像样本所在的路径image_path = '{}/{}'.format(train_dir, path)# 遍历所有图像for image in os.listdir(image_path):# 图像完整路径和名称image_file = '{}/{}'.format(image_path, image)try:# 验证图片格式是否okwith open(image_file, 'rb') as f_img:image = Image.open(io.BytesIO(f_img.read()))image.load()if image.mode == 'RGB':f.write('{}\t{}\n'.format(image_file, label_index))except:continuegenerate_annotation('train') # 生成训练集标注文件
generate_annotation('valid') # 生成验证集标注文件
generate_annotation('test') # 生成测试集标注文件
定义generate_annotation()方法,调用其进行训练文件的标注
其中需要从标注文件config.py里面引入get方法,文件如下:
__all__ = ['CONFIG', 'get']CONFIG = {'model_save_dir': "./output/zodiac",'num_classes': 12,'total_images': 7096,'epochs': 20,'batch_size': 32,'image_shape': [3, 224, 224],'LEARNING_RATE': {'params': {'lr': 0.00375 }},'OPTIMIZER': {'params': {'momentum': 0.9},'regularizer': {'function': 'L2','factor': 0.000001}},'LABEL_MAP': ["ratt","ox","tiger","rabbit","dragon","snake","horse","goat","monkey","rooster","dog","pig",]
}def get(full_path):for id, name in enumerate(full_path.split('.')):if id == 0:config = CONFIGconfig = config[name]return config
最终结果产生训练集、验证集和测试集
标签标注结果如下:

2.1.2 数据集定义
#导入相关库
import paddle
import numpy as np
from config import getpaddle.__version__
from dataset import ZodiacDatasettrain_dataset = ZodiacDataset(mode='train')
valid_dataset = ZodiacDataset(mode='valid')print('训练数据集:{}张;验证数据集:{}张'.format(len(train_dataset), len(valid_dataset)))
| 训练数据集:7096张;验证数据集:639张 | |
|---|---|
通过dataset文件进行 ZodiacDataset()类的编写,从而实现数据集的定义,其文件内容如下:
import paddle
import paddle.vision.transforms as T
import numpy as np
from config import get
from PIL import Image__all__ = ['ZodiacDataset']# 定义图像的大小
image_shape = get('image_shape')
IMAGE_SIZE = (image_shape[1], image_shape[2])class ZodiacDataset(paddle.io.Dataset):#方法定义"""十二生肖数据集类的定义"""def __init__(self, mode='train'):"""初始化函数"""assert mode in ['train', 'test', 'valid'], 'mode is one of train, test, valid.'self.data = []with open('signs/{}.txt'.format(mode)) as f:for line in f.readlines():info = line.strip().split('\t')if len(info) > 0:self.data.append([info[0].strip(), info[1].strip()])if mode == 'train':self.transforms = T.Compose([T.RandomResizedCrop(IMAGE_SIZE), # 随机裁剪大小T.RandomHorizontalFlip(0.5), # 随机水平翻转,概率为百分之五十T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化])else:self.transforms = T.Compose([T.Resize(256), # 图像大小修改T.RandomCrop(IMAGE_SIZE), # 随机裁剪T.ToTensor(), # 数据的格式转换和标准化 HWC => CHWT.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化])def __getitem__(self, index):"""根据索引获取单个样本"""image_file, label = self.data[index]image = Image.open(image_file)if image.mode != 'RGB':image = image.convert('RGB')image = self.transforms(image)return image, np.array(label, dtype='int64')def __len__(self):"""获取样本总数"""return len(self.data)
通过 assert方法判断mode的三种形式,‘train’, ‘test’, ‘valid’,并对不同类别的数据集进行数据预处理,调用API接口对图像进行翻转裁剪等数据增强操作,并对像素点进行数据处理(transforms API)
2.2网络搭建
2…2.1ResNet50网络介绍
2.2.1.1 系列网络

2.2.1.2 网络结构

2.2.1.3 残差区块

2.2.1.4 ResNet网络其他版本

2.2.2 网络构建
network = paddle.vision.models.resnet50(num_classes=get('num_classes'), pretrained=True)
可以直接调用高层API接口进行训练。设置pretrained等于true,加载前人已经训练好的参数进行训练
也可以自己用sequential接口逐层网络搭建
2.2.3 网络结构可视化
model = paddle.Model(network)
model.summary((-1, ) + tuple(get('image_shape')))

2.3 模型训练优化
EPOCHS = get('epochs')
BATCH_SIZE = get('batch_size')def create_optim(parameters):step_each_epoch = get('total_images') // get('batch_size')lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=get('LEARNING_RATE.params.lr'),T_max=step_each_epoch * EPOCHS)return paddle.optimizer.Momentum(learning_rate=lr,parameters=parameters,weight_decay=paddle.regularizer.L2Decay(get('OPTIMIZER.regularizer.factor')))##Adama调优换成Momentum调优# 模型训练配置
model.prepare(create_optim(network.parameters()), # 优化器paddle.nn.CrossEntropyLoss(), # 损失函数paddle.metric.Accuracy(topk=(1, 5))) # 评估指标# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集valid_dataset, # 评估数据集epochs=EPOCHS, # 总的训练轮次batch_size=BATCH_SIZE, # 批次计算的样本量大小shuffle=True, # 是否打乱样本集verbose=1, # 日志展示格式save_dir='./chk_points/', # 分阶段的训练模型存储路径callbacks=[visualdl]) # 回调函数使用
配置相关参数,学习率,,学习率优化器,训练批次,优化器,损失函数和评估指标等

acc_top1:预测的第一个值是正确答案
acc_top5:预测的前五个值包含正确答案
其中,我们可以训练可视化visualdl工具的回调函数
visualDL打开页面如下:

2.4 保存模型
model.save(get('model_save_dir'))
2.5 模型评估测试
测试数据集引入
predict_dataset = ZodiacDataset(mode='test')
print('测试数据集样本量:{}'.format(len(predict_dataset)))
| 测试数据集样本量:646 | |
|---|---|
通过 ZodiacDataset类进行测试数据集的加载
载入保存好的模型,导入测试集进行结果的预测,将预测结果导入result中
from paddle.static import InputSpec# 网络结构示例化
network = paddle.vision.models.resnet50(num_classes=get('num_classes'))# 模型封装
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1] + get('image_shape'), dtype='float32', name='image')])# 训练好的模型加载
model_2.load(get('model_save_dir'))# 模型配置
model_2.prepare()# 执行预测
result = model_2.predict(predict_dataset)
模型测试验证
# 样本映射
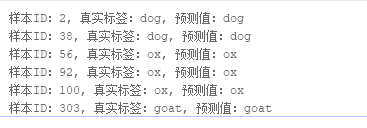
LABEL_MAP = get('LABEL_MAP')# 随机取样本展示
indexs = [2, 38, 56, 92, 100, 303]for idx in indexs:predict_label = np.argmax(result[0][idx])real_label = predict_dataset[idx][1]print('样本ID:{}, 真实标签:{}, 预测值:{}'.format(idx, LABEL_MAP[real_label], LABEL_MAP[predict_label]))
2.6 模型部署保存
model_2.save('infer/zodiac', training=False)
总结
今天用ResNet50网络完成了对十二生肖的分类任务,其中数据标注文件需要好好理解,直接调用高层API进行训练的方式无疑更加简便,其中可视化visualDL工具在帮助我们处理训练结果时,以及完成科研论文方面无疑大有裨益
这篇关于深度学习七日打卡营day02(2)十二生肖图片分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




