2019独角兽企业重金招聘Python工程师标准>>> 
相信大部分同学曾经都学习过快速排序、Huffman、KMP、Dijkstra等经典算法,初次学习时我们惊叹于算法的巧妙,同时被设计者的智慧所折服。于是,我们仔细研读算法的每一步,甚至去证明算法的正确性,或者是去尝试优雅地实现这些算法。总之,我们会花费很大的时间精力去理解这些智慧的结晶。
然而,现在对于这些经典的算法你仍然了然于胸吗?就算现在你仍然记得这些算法的步骤,你敢确保一年后、十年后自己不会忘记?我想没有多少人敢保证吧。
我们当然希望自己掌握一个算法后,就永远不会忘记,最好还能举一反三,利用算法中的思想去解决新的问题。然而,现实与美好的愿景往往是背道而驰,不要说举一反三,我们甚至经常忘记那些算法本身。
背算法与设计算法
为什么会这样?简单来说,因为我们从来就没有真正掌握过这些算法,我们只不过是在背诵别人发明的算法,就像我们背诵历史书上的那些历史事件一样,时间久了自然会慢慢遗忘。
我们接触到某个算法时,看到的只是对算法过程的讲解,对其正确性的证明,或者对其效率的分析(想想大名鼎鼎的《算法导论》,《算法》是如何讲解某一算法的),我们不会看到那些牛人是如何“灵机一动”设计出了这惊天地泣鬼神的算法。也就是说我们只是知其然,并没有知其所以然。当我们不知道一个算法的来龙去脉,不知道设计它经历的那些思维历程时,就很容易忘记它的具体内容。相反,那些牛人就不会忘记自己设计的算法。
所以,当看到别人牛逼的闪闪发光的算法后,我们一定要探寻算法背后那“曲径通幽”的思维之路。只有经历了思维之路的磨难,才配得上永远占有一个算法,并有可能举一反三,或者是设计一个巧妙算法。刘未鹏在知其所以然(三):为什么算法这么难?中探索了Huffman编码的思维历程,值得一看。顺便说一下,探索算法背后的思维历程不是件容易的事,要知道就是霍夫曼本人也是花了一个学期才想出它的编码算法。
下面我们以LeetCode上一个好问题,来探索这个问题的算法背后的思维之路。关于什么是好问题,刘未鹏在跟波利亚学解题上有一个不错的观点:好问题即测试一个人思维的习惯的题目,通常考察你的联想能力、类比能力、抽象能力、演绎能力、归纳能力、观察能力、发散能力等。
一个好问题
LeetCode 84题:Largest Rectangle in Histogram,给定一个直方图(下图a),求直方图中能够组成的所有矩形中,面积最大为多少。对于图a来说,我们很容易看出来面积最大的矩形为高度为5和6的直方图组成的矩形(图b隐形部分),其面积为5 * 2 = 10。
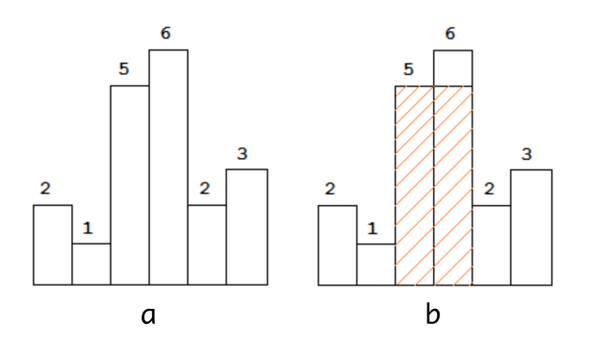
题目描述
其实这个题稍微加以变化,就是另一个相当有趣的问题:Maximal Rectangle.
这道题目一个显而易见的解决方法就是暴力搜索:找出所有可能的矩形,然后求出面积最大的那个。要找出所有可能的矩形,只需要从左到右扫描每个立柱,然后以这个立柱为矩形的左边界(假设为第i个),再向右扫面,分别以(i+1, i+2, n)为右边界确定矩形的形状。
这符合我们本能的思考过程:要找出最大的一个,就先列出所有的可能,比较大小后求出最大的那个。然而不幸的是,本能的思考过程通常是简单粗暴而又低效的,就这个题目来说,时间复杂度为N^2 。那么有没有一种更加高效的解决办法呢?
一个好算法
我第一次面对这个题时,并没有想出一个漂亮的解决方案。因为从给定的条件来看,似乎找不到一个约束条件使得满足这个条件的矩形面积最大,也就是说无法缩减问题的规模,因此必须找出所有可能的矩形,这样的话效率肯定是N^2 。
然而去Google了一下,立即发现了一个时间复杂度O(n)的算法,当时就被这神奇的解法所震撼到。它的代码十分简单,简单到一开始我根本就看不懂,不明白为什么这样子求出的就是最大的矩形。网上好多所谓的解题报告里面只是人云亦云地给出了算法的步骤,没有算法正确性的证明,更没有我们最想要的关于解题思路。
我也先给出算法步骤和代码,看看你是不是同样一头雾水。在程序中维护一个栈,栈中元素为直方图中bar的下标,然后从头开始扫描每个bar:
-
如果当前bar的高度大于栈顶bar的高度,则将当前bar的下标入栈;
-
否则执行出栈操作,记录弹出下标对应的bar的高度,并计算出一个面积,然后用这个面积更新最大面积。
代码也是相当简洁,python源码如下:
deflargestRectangleArea(self,height):
height.append(0)
size= len(height)
no_decrease_stack= [0]
max_size= height[0]
i= 0
whilei< size:
cur_num= height[i]
if(notno_decrease_stack or
cur_num> height[no_decrease_stack[-1]]):
no_decrease_stack.append(i)
i+= 1
else:
index= no_decrease_stack.pop()
ifno_decrease_stack:
width= i- no_decrease_stack[-1]- 1
else:
width= i
max_size= max(max_size,width* height[index])
returnmax_size
高效而难以理解,这就是那些神奇算法的共性。
一个思维历程
那么这个算法真的就是我等凡夫俗子不能想出来的?难道我们只能仰望高山,恨自己智商不高?我还真不服气呢,于是又静下心去思考这个问题。
这次我们不从已知条件推结果,而直接从结论入手,就是说假设现在已经找到了面积最大的那个矩形。接着我们来分析该矩形有什么特征,然后可以用下面两种方法之一来缩减问题的规模(因为这两种方法都不用找出所有的矩形一一比较)。
-
找出满足这些特征的矩形,面积最大的矩形肯定是其中之一;
-
排除那些不满足这些特征的矩形,面积最大的矩形在剩下的那些矩形里面。
为了使考虑情况尽可能全面,画了许多直方图,防止使用原题目图片可能存在的一些特定假设,其中一个直方图如下图:
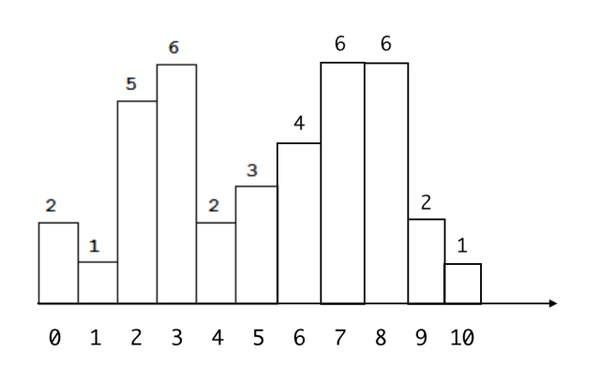
题目情况分析
通过不断地对多个直方图的观察,发现面积最大的那个矩形好像都包含至少一个完整的bar,那么这条规律适用于所有的直方图吗?我们用反证法来证明,假设某个最大矩形中每个竖直块都是所在的bar的一小段,那么这个矩形高度增加1后仍然是一个合法的矩形,但新的矩形面积更大,与假设矛盾,所以面积最大的矩形必须至少有一个竖直块是整个bar。
至此我们找到了面积最大矩形的一个特性:各组成竖直块中至少有一个是完整的Bar。有了这条特性,我们再找面积最大的矩形时,就有了一个比较小的范围。具体来说就是针对每个bar,我们找出包含这个bar的面积最大的矩形,然后只需要比较这N个矩形即可(N为bar的个数)。
那么问题又来了,如何找出“包含某个bar的面积最大的矩形呢”?对于上面的直方图,包含下标为4的bar的最大矩形如下图橘黄色部分:
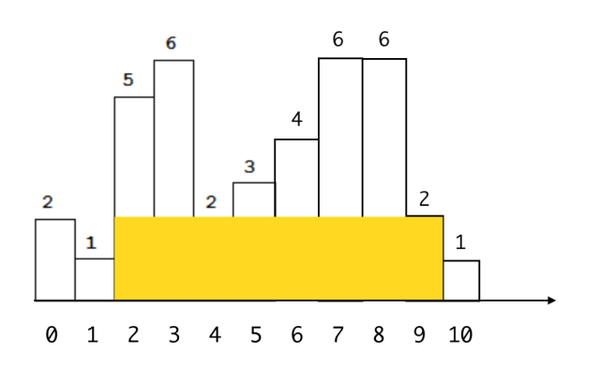 局部最大矩形
局部最大矩形
简单观察一下,就会发现要找到包含某个bar的最大矩形其实很简答,只需要找到高度小于该bar的左、右边界即可,上图中分别是下标为1的bar和下标为10的bar。
至此问题已经变为“对于给定的bar,如何确定高度比它小的左、右边界”。其实求左边界和右边界是同样的求法,下面我们考虑求每个bar的左边界。最直接的思路是对于每个bar,扫面其前面所有的bar,找出最后一个高度小于它的bar,这样的话时间复杂度明显又是N^2 ,Holy Shit。
到这里似乎没有路可走了,但如果我们继续绞尽脑汁地去想,可能(或许你对栈理解的很深入,或许是你在一个类似的问题中用到了栈,当然你也可能想到动态规划的思想,那也是可行的)会联想到栈这一数据结构。用栈维护一个高度递增的bar的集合,也就是说栈底到栈顶部对应的bar的高度越来越大。那么对应一个刚读入的bar,我们只需要比较它的高度和栈顶对应bar的高度,如果当前bar比较高,则弹出栈顶元素继续比较,直到栈顶bar比它低或者栈为空。之后,将当前bar入栈,更新栈内的递增序列。
我们从左到右扫一遍得到每个bar对应的左边界,然后从右到左扫一遍得到bar的右边界。两次扫描过程中,每个bar都只有出栈、入栈操作,所以时间复杂度为O(N)。通过这样的预处理,即可以O(N)的时间复杂度得到每个bar的左右边界。之后对于每个bar求出包含它的最大面积,也即是由左右边界和bar的高度围起来的矩形的面积。再做N次比较,即可得出最终的结果。
这里先预处理用两个栈扫描两次得到左、右边界,再计算面积,是按照推导过程一步一步来的。当我们写完程序后,再综合看这个问题,可能会发现其实没必要这样分开来做,我们可以在扫描的同时,维护一个递增的栈,同时在“合适的”时候计算面积,然后更新最大面积。具体实现方法就是前面给出的那个神奇的算法,不过现在看来一点也不神奇了,我们已经探索到了它背后的思维历程。
当然,条条道路通罗马,上面思维过程只是其中一条通往解决方案的路径,你可能以另一种思维过程找到了答案。不过,我们上面的整个推导过程没有涉及一些类似“神谕”的启发,只是一些简单的方法:比如从结论推导、反证法、归纳总结、联想(可能联想到栈有点难)等,因此每个人都可以学会,并且很容易被大脑记住。值得注意的是,我们的整个思考过程并不简简单单地跟上面写的那样是线性的,它更可能是树形的,只是我们剪去了那些后来证明行不通的枝。
解题的万能思考法则?
人类在漫长的进化史中,解决了各种各样的问题。例如
-
如何度过一条湍急的河流
-
如何保留火种
-
如何治愈天花
-
如何制造一个会飞的机器
-
…
同时也对自己的思维方式进行总结和反思,笛卡尔曾经试图将人类思维的规则总结为36条(最终完成了21条)。
那么有没有一个解题的万能思考法则,按照这个法则去思考,最终能解决所有的问题或者是证明某个问题不可解?目前看来是没有这样的思考法则的,不然我们就可以制造出真正的会思考的机器了。
不过还是有许多思维方法值得我们去学习强化,波利亚在《How To Solve It》上总结了这些方法,如果想培养良好的思维习惯,那么这本书是必不可少的。








