本文主要是介绍李宏毅——元学习meta learning1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
李宏毅——元学习meta learning1
- 导语
- meta-learning
- meta-learning的步骤
- 什么叫一组learning algorithm
- 如何评价一个F的好坏
- meta learning vs machine learning
- 怎么找最好的learning algorithm
- benchmark
- omniglot
- 如何使用
- 当前的方法
- MAML
- 算法
- 例子
- toy examle
- omniglot& mini-imageNet
- 实际实现
- 在翻译上的应用
- Reptile
- 想法
- 其他算法
- 思考
导语
什么是meta learning:学习如何去学习
例子:
机器学习了一堆任务后,再过去经验上,成为一个更好的学习者
比如做语音辨识,图像辨识后,学习文字分类更快

life-long和meta-learning的区别:
life-long是一个模型一直学习
meta不是一个模型,而是学会更好的学习
meta-learning

在meta-learning中,把学习算法也当作一个函数F,吃进去的是训练资料,吐出来另外一个function
可以视为
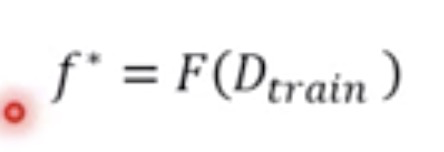
区分machine learning和meta learning
meta是要找一个大写的F,输入是训练资料,输出是模型

机器学习的三个步骤:
定义一个function set,定义loss,然后找到最好的function。
meta的话,只是把f改成F,learning algorithm F。

meta-learning的步骤
什么叫一组learning algorithm
在gradient descent中,算法如下图
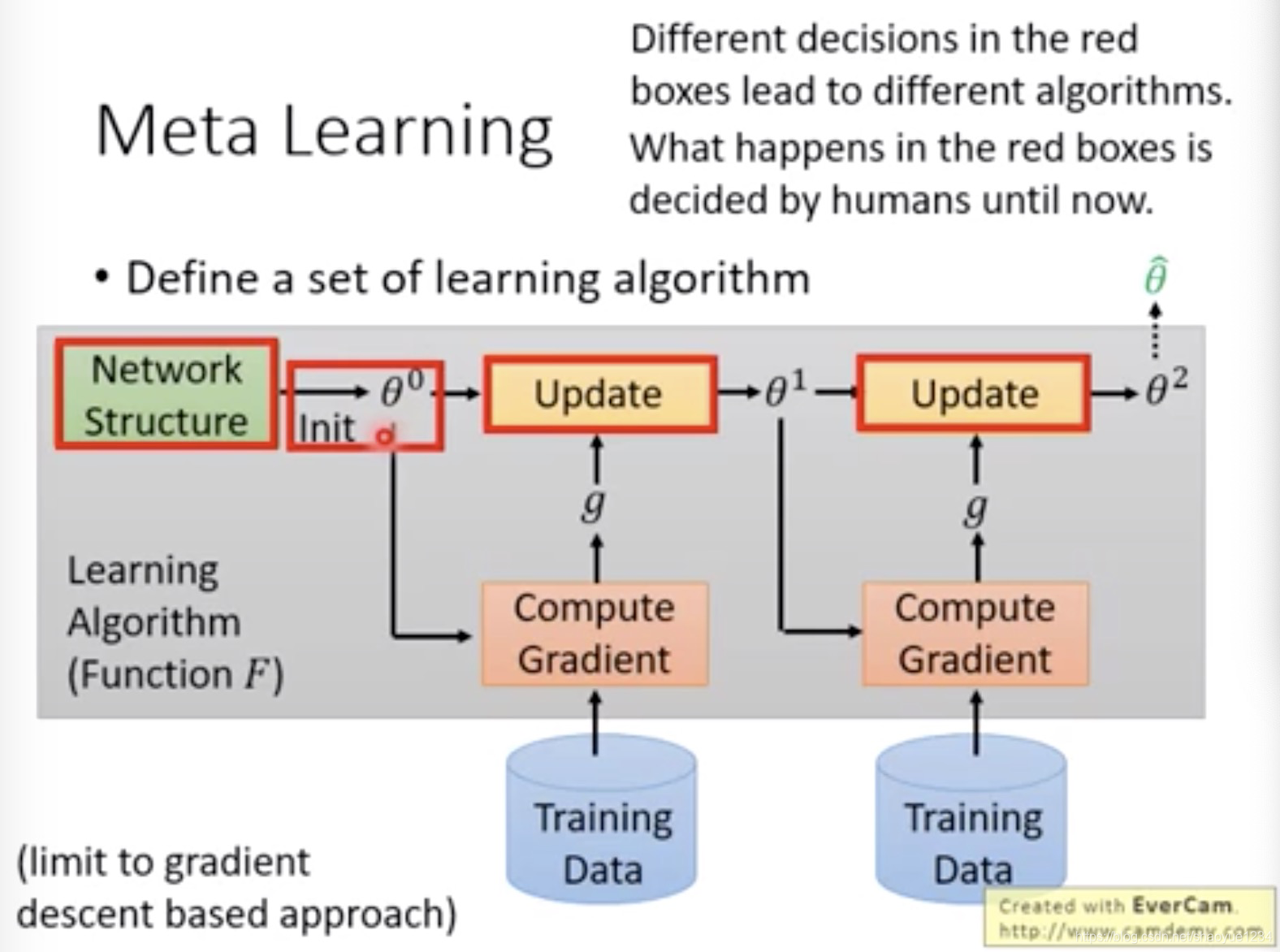
整个圈起来的过程,就可以看作是一个Learning Algorithm
。红色的方块选择不同设计的时候,就等于选择了不同的算法。
现在都是人为决定这些红色部分,让机器自己去学习如何决定红色部分,就是达成了meta learning的一部分。
如何评价一个F的好坏
训练一个猫狗分类任务,用测试数据测试任务表现怎么样,在机器学习中,要用一组数据来考量好坏,meta-learning中,要用一组任务来考量好坏。

右上角的L即为loss。
meta learning vs machine learning
在machine learning中,准备训练资料和测试资料
在meta learning中,准备训练任务及其对应的资料
其中也有可能需要validation task。
meta-learning在few-shot中可能使用,因为训练资料少,跑的比较快,可以比较好评估。
在few-shot中,通常把train和test称为support set和query set。

怎么找最好的learning algorithm
首先根据loss找到最好的F,然后对新任务进行训练,在用测试数据进行测试,来评估表现。

benchmark
omniglot

如何使用
在few-shot classification中
决定多少Way,多少个shot。way表示多少个类别,shot表示多少个example。
在实际训练中,要将符号分为训练组和测试组。
训练时从训练组中找N个character,然后找到K个example。测试时方法一样,但是从测试组中选。

当前的方法
MAML
算法

学习红框部分的初始化参数。训练网络,得到最好的theta,而这个theta是取决于如何初始化的,即可用Loss函数评估网络的好坏
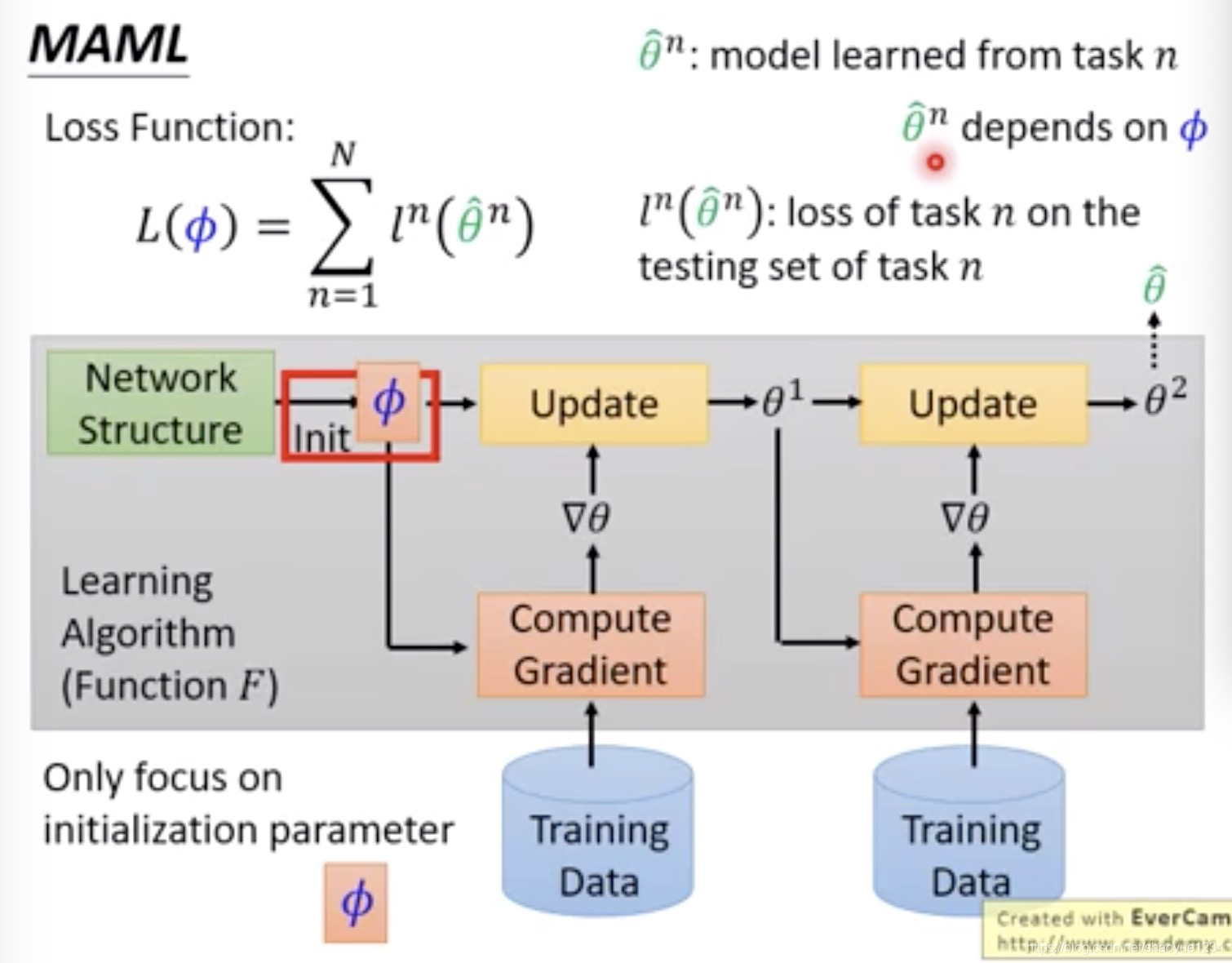
如何最小化loss呢
可以利用gradient descent。
区分MAML与model pre-training
在model pre-training中,用正在训练的模型来计算loss,而maml中使用训练好的模型

下图中横轴是model parameter,如果是maml中,我们不在意现在的表现,比如图中的phi做初始的参数,将顺着gradient的方向,在两个任务上都走的很好

在model pre-training中,在意现在的表现,但不保证训练后会好。

所以两者的区别在于黄框中的字。MAML在乎潜力,model pre-training中在乎当前表现。

MAML在实战时,假设参数只更新一次,模型就是下图。
theta和phi的关系就是右下角的式子。
只更新一次的理由:快,phi棒到只更新一次就很好,在测试实战时可以更新多次,few-shot中数据有限

例子
toy examle
每个任务的做法都是估计function,可以多选ab,构造多个task

使用model pre-training,获得的是水平线
做MAML,获得的是下面的线。

omniglot& mini-imageNet

其中first order approx是一种变形:


在论文中,为了简便


实际实现
首先用一个taskm,获得thetam,然后用thetam来更新phi,如此下去。
跟model pre-training相比,maml要更新两次

在翻译上的应用
横轴代表每一个任务上用的训练资料,metaNMT表示MAML,multiNMT表示pre-training,通常meta比较好。

Reptile

想法
可以update很多次,然后根据二者之间的差,让phi走过去

做的和model pre-training很相似。
他们之间的区别如下:
pre-train走的方向是g1,MAML是g2,reptile是g1+g2

其他算法
除了找初始参数,还能找网络架构、activation等,或者如何更新

思考


这篇关于李宏毅——元学习meta learning1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









