本文主要是介绍爬取春秋航空航班信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、使用fiddler爬取小程序春秋航空航班信息
-
使用Fiddler爬取春秋航空微信小程序(手机上由于网络问题,无法进入,使用电脑版)
-
搜索航班信息
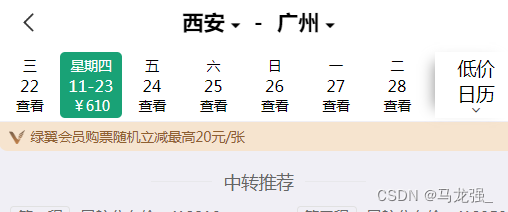
-
搜索记录
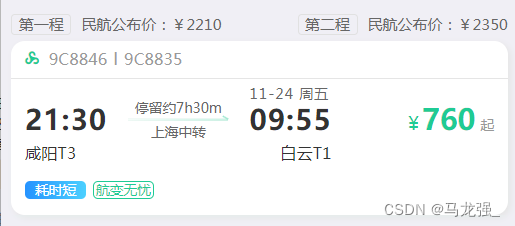
-
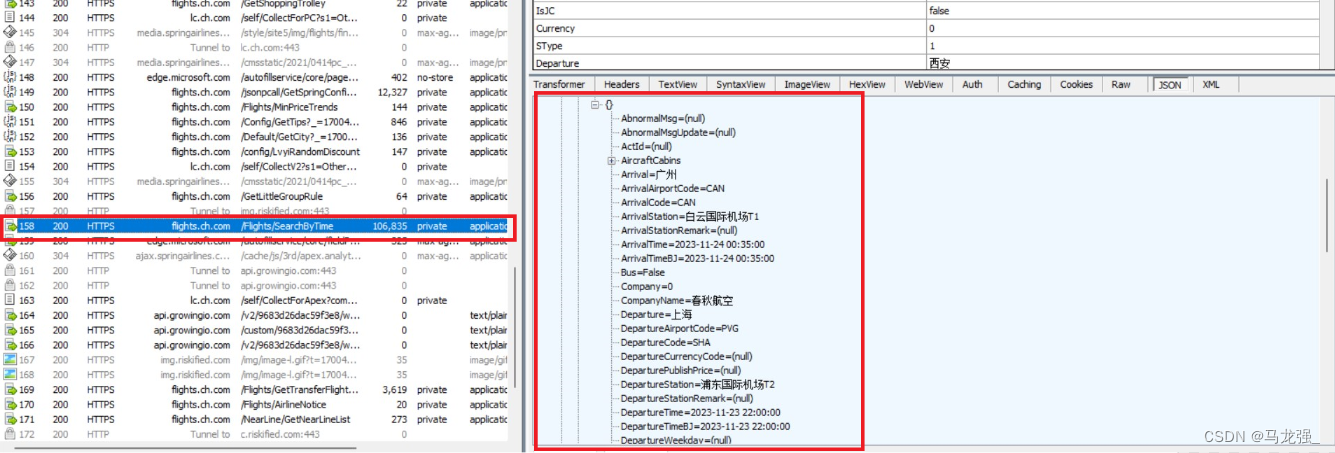
使用Fiddler查找url(没有得到有效url)
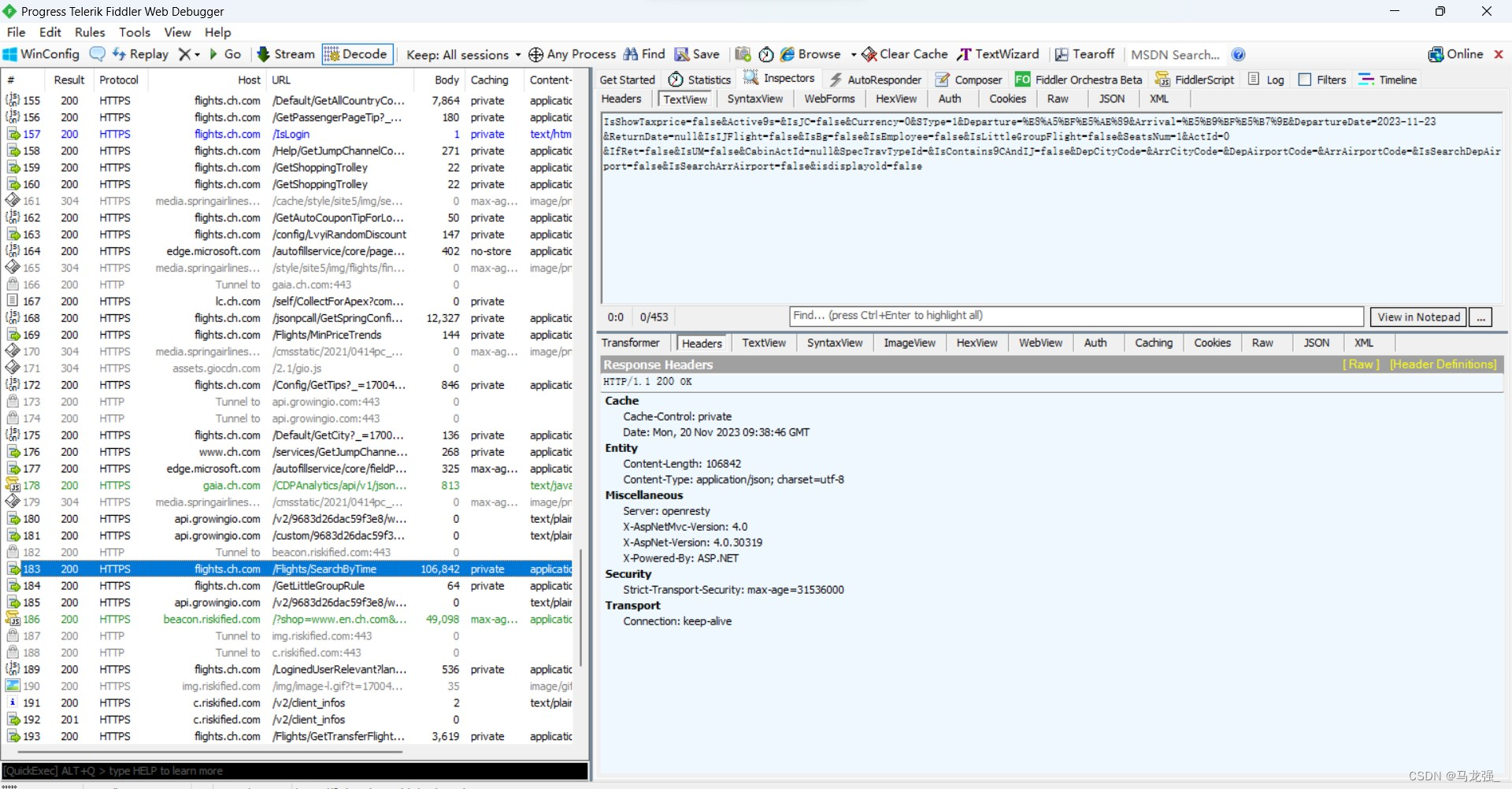
-
继续查找,发现航班信息列表(打开查看,列表为空)
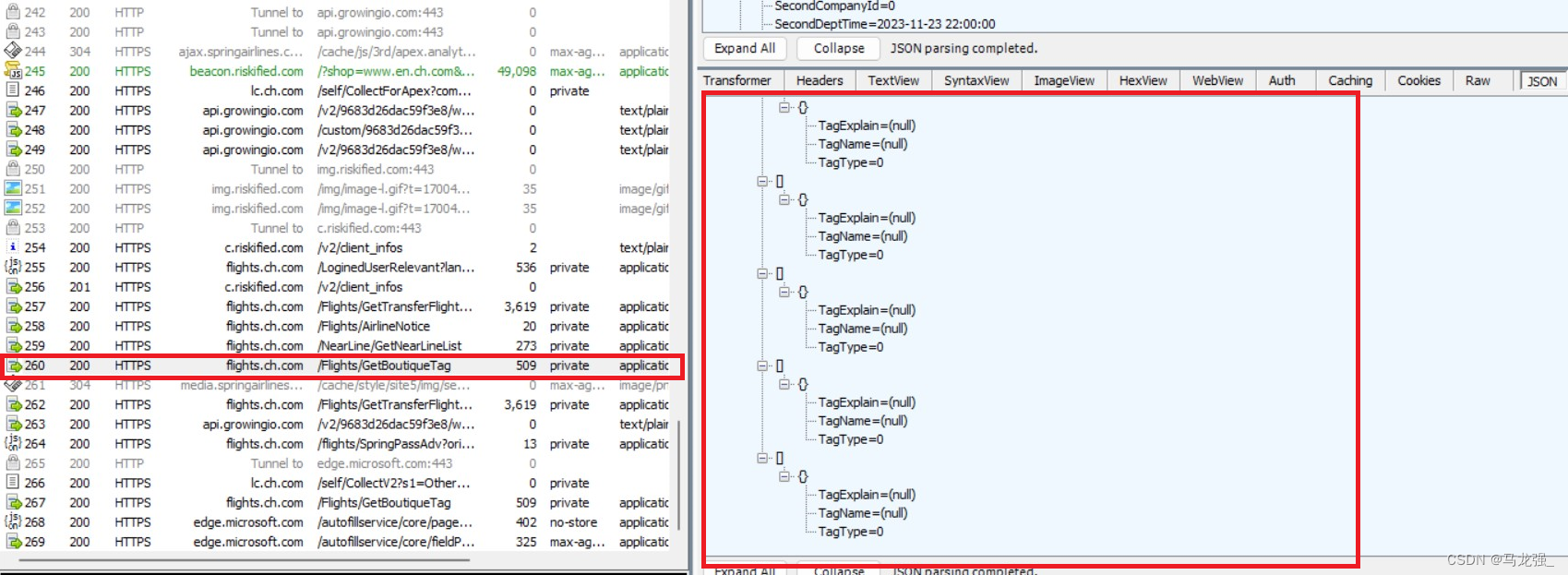
-
重新搜索,再次查找(发现航班信息,但url无效,不能正常使用)
微信小程序好像被加密了,无法正常爬取
二、使用网页版春秋航空,爬取网页信息
-
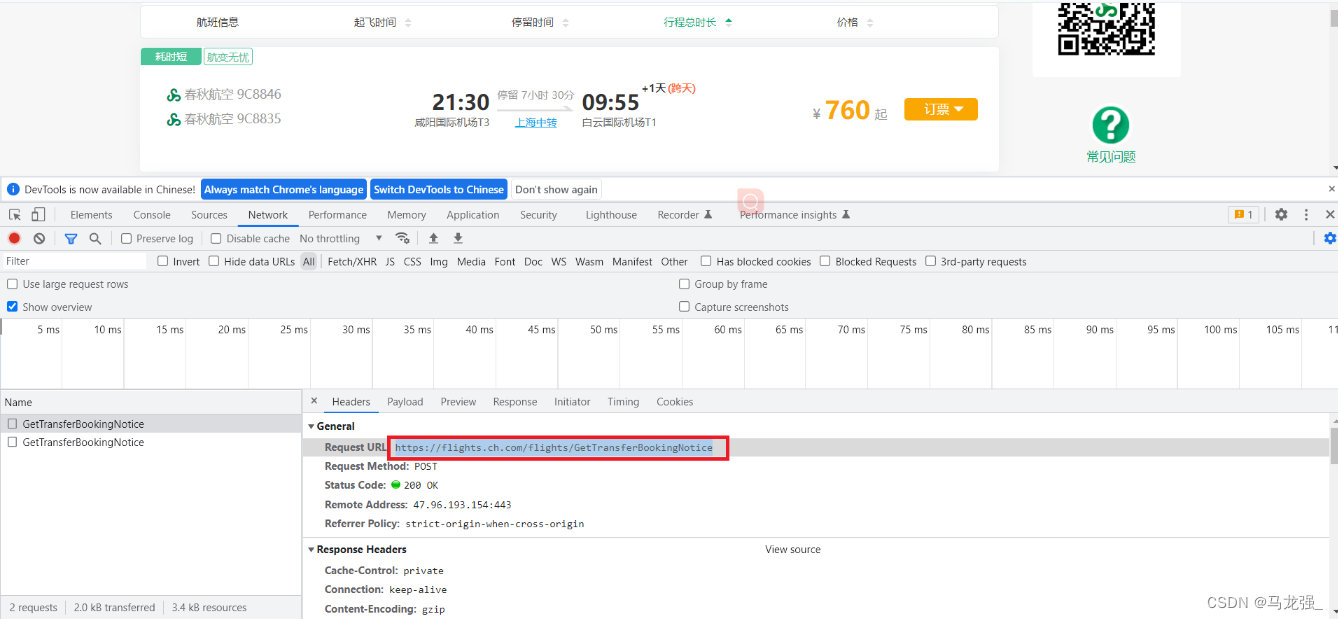
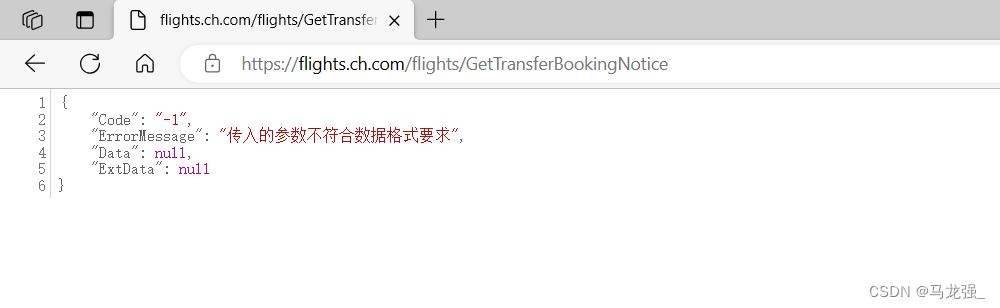
进入网页查找url(发现一个貌似url的内容,打开发现无效)
-
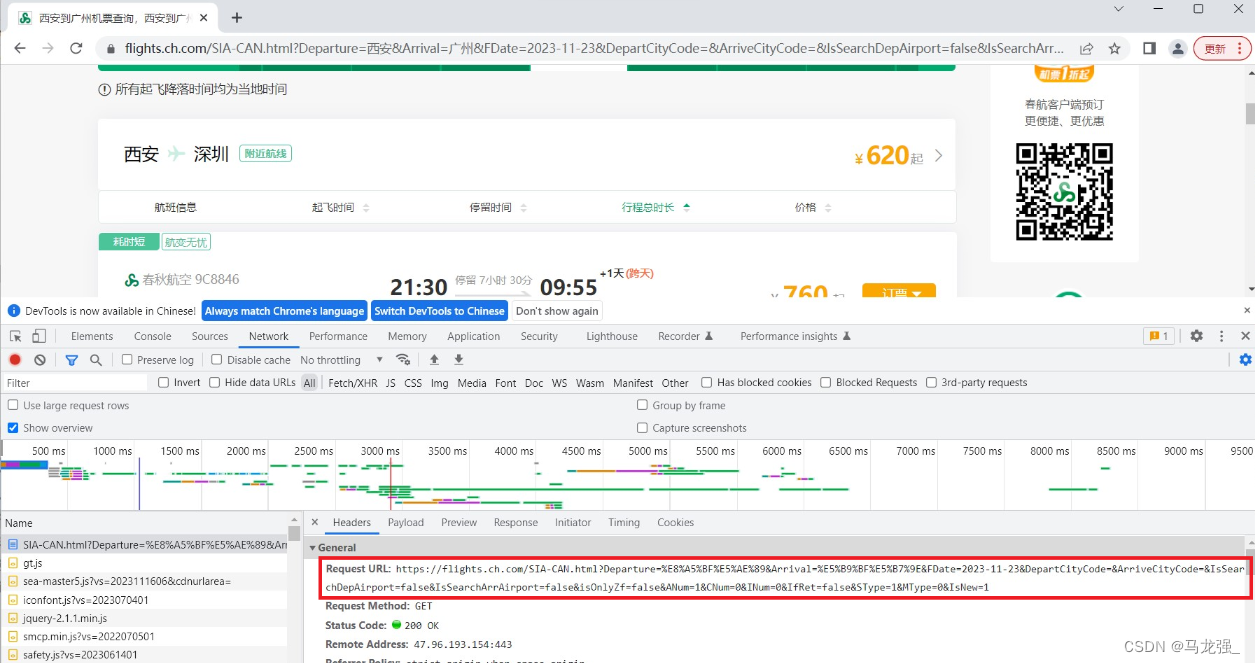
继续查找url(找到航班信息网页信息,查找到url)
- 相关代码
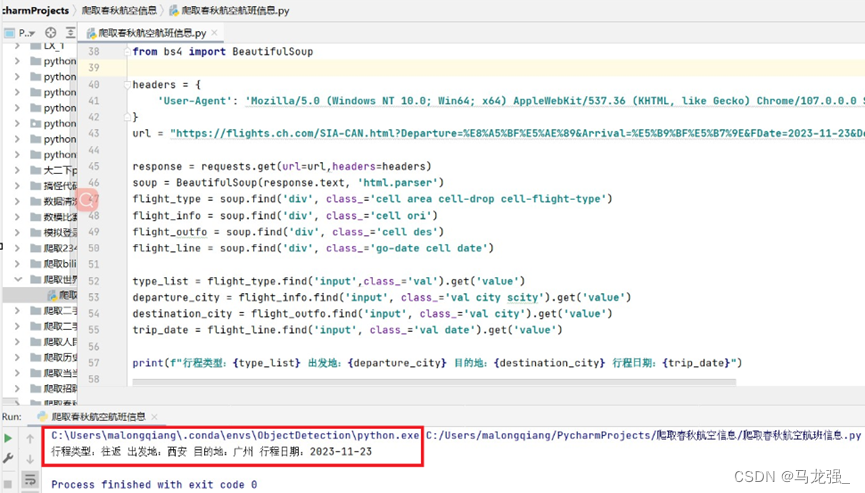
import requests
from bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
}
url = "https://flights.ch.com/SIA-CAN.html?Departure=%E8%A5%BF%E5%AE%89&Arrival=%E5%B9%BF%E5%B7%9E&FDate=2023-11-23&DepartCityCode=&ArriveCityCode=&IsSearchDepAirport=false&IsSearchArrAirport=false&isOnlyZf=false&ANum=1&CNum=0&INum=0&IfRet=false&SType=1&MType=0&IsNew=1"response = requests.get(url=url,headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
flight_type = soup.find('div', class_='cell area cell-drop cell-flight-type')
flight_info = soup.find('div', class_='cell ori')
flight_outfo = soup.find('div', class_='cell des')
flight_line = soup.find('div', class_='go-date cell date')type_list = flight_type.find('input',class_='val').get('value')
departure_city = flight_info.find('input', class_='val city scity').get('value')
destination_city = flight_outfo.find('input', class_='val city').get('value')
trip_date = flight_line.find('input', class_='val date').get('value')print(f"行程类型:{type_list} 出发地:{departure_city} 目的地:{destination_city} 行程日期:{trip_date}")
爬取结果
这篇关于爬取春秋航空航班信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






