本文主要是介绍bitmap基础介绍+holo实现离线UV计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
bitmap
- 基础介绍
- bitmaping 数据结构
- bitmap计算算子集成
- 二阶段分布式计算:
- RoaringBitmap构造方案
- 分桶方案
- 建序方案
- holo官网 离线UV计算
- 创建用户映射表
- 创建聚合结果表
- 更新用户映射表和聚合结果表
- 更新聚合结果表
- UV、PV查询
基础介绍
RoaringBitmap主要为了解决UV指标计算的问题。旨在建立一种可以多维分析的精准UV数据模型,并且可以低成本地实现交并差等集合运算UV指标。
PV和UV指标一直是各类业务中广泛存在并且重点关注的实时指标。其中对于PV指标而言,由于其具备可加性,因此当对维度组合或者时间维度进行上卷时,可以直接求和得出我们所要的累计结果。但是去重指标UV则具备不可加性,他是一种对UID去重计数的指标,如果在维度上卷时直接求和会导致结果偏大。即UV指标一旦定制化生成,就很难具备再计算的能力,需要用户事先计算好。例如。
- 模型包含每天的UV,但是要算多天的去重UV,则需要从特定时间点重新开始算。
- 模型包含每个城市的UV,但是要算全国的去重UV,则需要去掉城市维度再次聚合计算。
根据历史经验,去重指标有许多解决方案可供设计。主要分为两类,一类是前置计算方案,通过Count Distinct将UV预聚合后存储起来,查询时直接路由到对应UV指标。一类是后置计算方案,将user_id转变成可去重的结构,在查询时通过集合运算,算出UV指标。
- 前置计算方案,即最常用的Count Distinct算子,统计时根据uid是否存在来决定计次,通常基于DWD模型或者UID粒度的DWS模型,生成UV指标存储在ADM模型中。
- 后置计算方案,通常将user_id存储在可去重结构,可去重结构包括非精准去重的HyperLogLog与ThetaSketch,以及精准去重的RoaringBitmap。
bitmaping 数据结构
RoaringBitmap是效压缩位图,采取的是2^ 32位(4294967296)的Bitmap,可以存储[0,2^32 -1]区间范围的用户编号。但是RoaringBitmap会对这个2^32bit的Bitmap做很多压缩操作,将Bitmap尽可能地压缩在很小的存储量级。其核心思想是:
- 对于每个用户编号k,会被划分成二进制的高16位(k / 2^16)和低16位(k mod 2^16)。
- 其中高16位称为共享有效位,又可称为分桶号。属于roaring bitmap的一级索引,总计最多可包含2^16=65536个桶。共享有效位只存储一份,可以由多个编号共用,因此很大程度上减少了空间消耗。
- 每一个桶由一个Container 来存放一个数值的低16位。其中container是RBM新创造的概念,其核心目标是为了更高效地压缩和存储数据。Container 总共包括三种数据结构: Array Container ,Bitmap Container和RunContainer。Array Container 存放稀疏的数据,Bitmap Container 存放稠密的数据。此外,如果Array Container和Bitmap Container可以用行程编码压缩,就会替换成RunContainer存储。
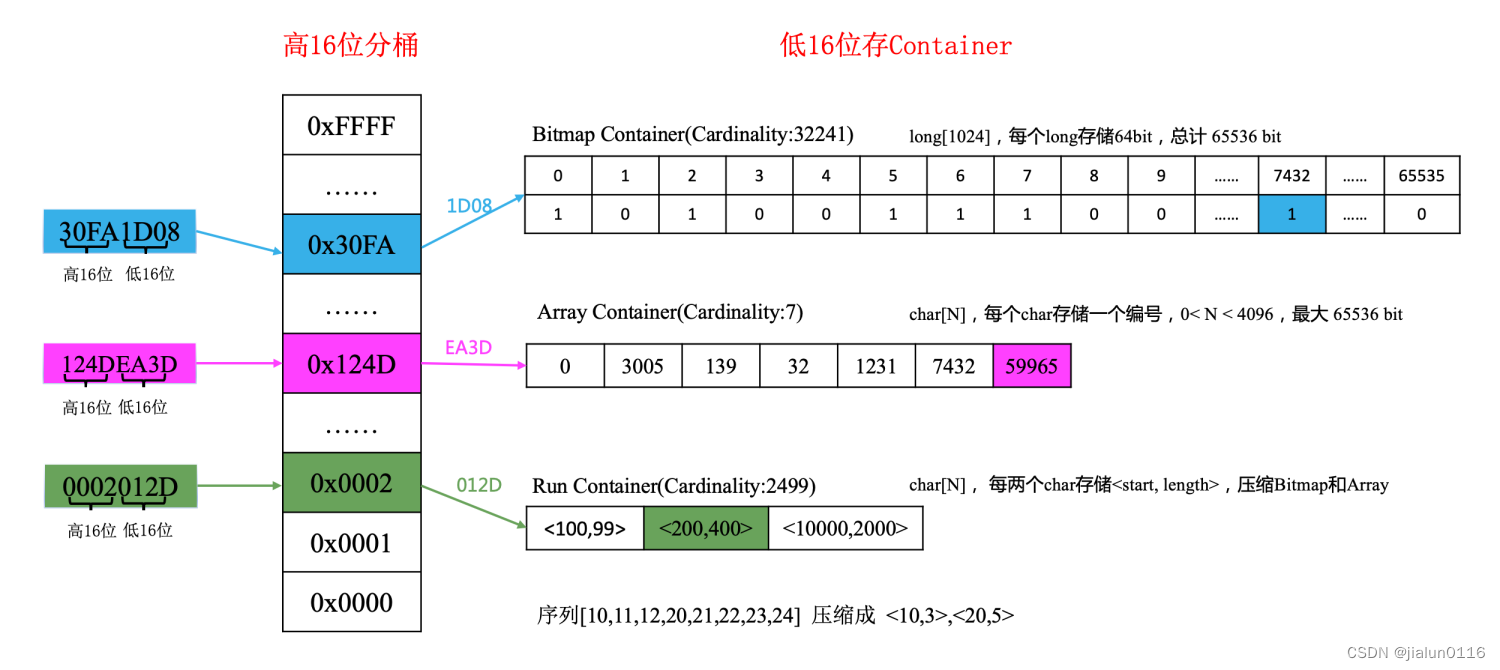
- Array Container:使用short数组存储低16位,元素排序后放入short数组中。没有数据压缩机制,在数据稀疏场景存储效率高。
- Bitmap Container:long数组存储低16位,数据内容对应long类型的bit位,数据稠密存储效率很高。如:1,5,6表达成一个long值为00110001.
- Run Container:低16位使用short数组存储,将连续数据值存储为[起始点,连续个数的格式]。在数据连续性好的场景存储效率高。例如数据[11,12,13,14,15]将存储为两个short数值[11,4]。
在存储效率方面,数据量离散且小于4096时使用array最优,在数据量大且无规律时bitmap最优,在数据连续性比较好的情况下,RunContainer的存储效率最优。
时间复杂度方面Bitmap时间复杂度为O(1)高于Array和Run存储的nlog(n)。
bitmap计算算子集成
hologres本身是兼容postgres开源生态,pg版本的roaringbitmap插件通过简单适配,很容易集成在hologres中。roaringbitmap插件:https://github.com/zeromax007/gpdb-roaringbitmap。
holo中roaringbitmap函数使用文档 :https://help.aliyun.com/zh/hologres/user-guide/roaring-bitmap-functions?spm=a2c4g.11186623.0.0.df1b5791jxHiiU
典型计算算子:
二阶段分布式计算:
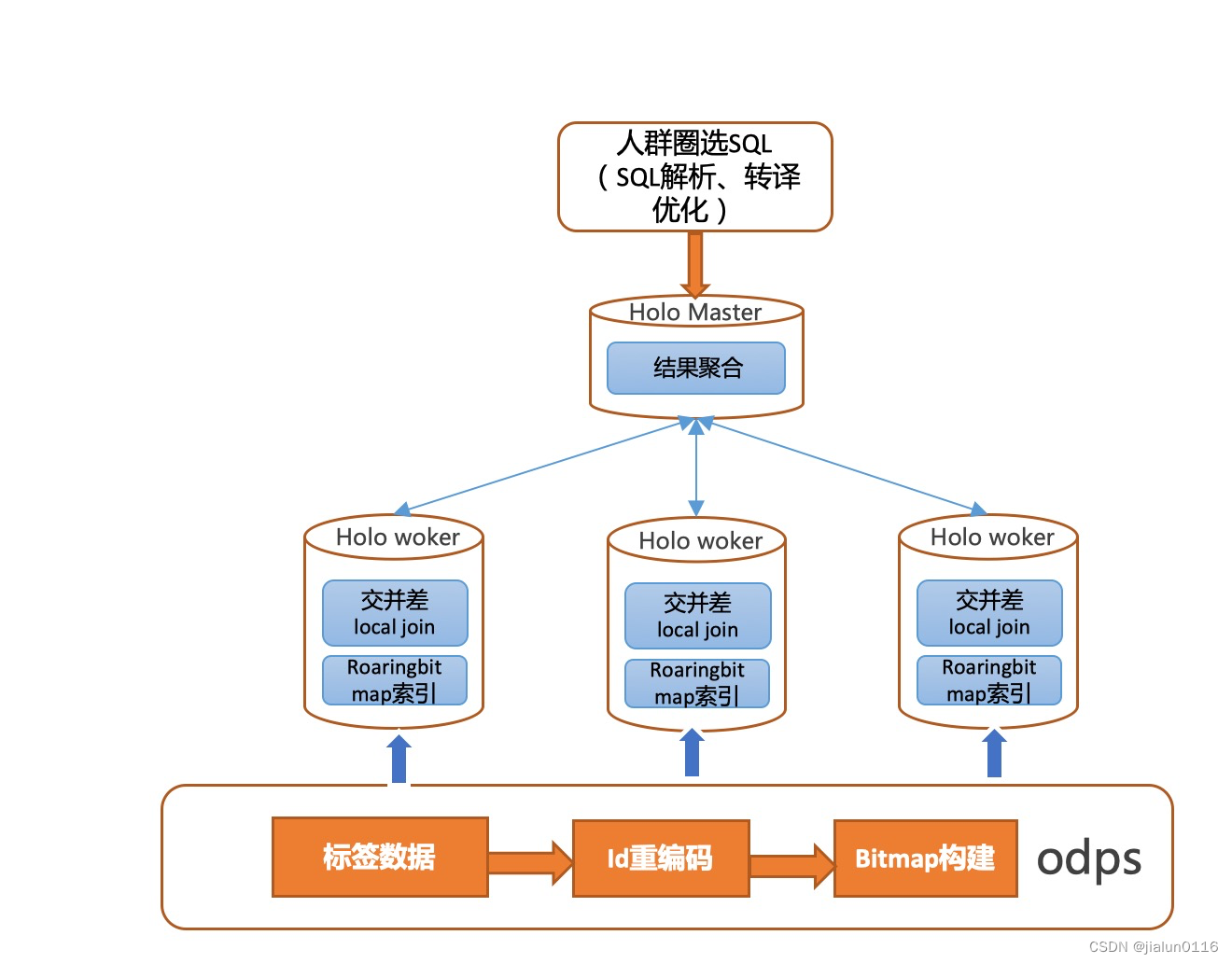
数据的分布键按桶号和bitmap高16位打散到hologres各个计算节点。在进行交并差集计算过程中,由于各个节点之间数据完全独立,每个节点可以单独进行计算,并将计算结果直接汇总到master节点计算进行聚合。整个计算过程是一个二阶段计算过程,完全没有数据shuffle, 整体计算非常高效。
RoaringBitmap构造方案
RoaringBitmap使用过程中,主要遇到的问题,就是如何将user_id存入到RoaringBitmap数据结构中。因为RoaringBitmap不能像HyperLogLog那样,可以直接将user_id存入Bitmap数据结构中。为了能将亿级的编号存入Bitmap中,探索过如下两种方案。
分桶方案
主要解决:数据量过多
分桶方案采取分治的思想,即将一个大用户集切成多个桶,每个桶的量级足以存到42亿的Bitmap中,并且桶中的UID互斥,没有重合的UID。
而分桶的方案包括很多,例如可以采取前几位分桶,或者后几位分桶,只要能够保证剩下的几位都可以存在Bitmap里面。在实时场景中,由于要考虑Explorer的机器数,因此既需要保障每个桶内的UV量级均匀的同时,也需要保障每台机器在存储桶的个数也是均匀的。如下图所示,但是由于ODPS没有存储机器数的概念,因此其分桶的个数可以更加灵活,只需要保障每个分桶下的UID数是相同的即可。
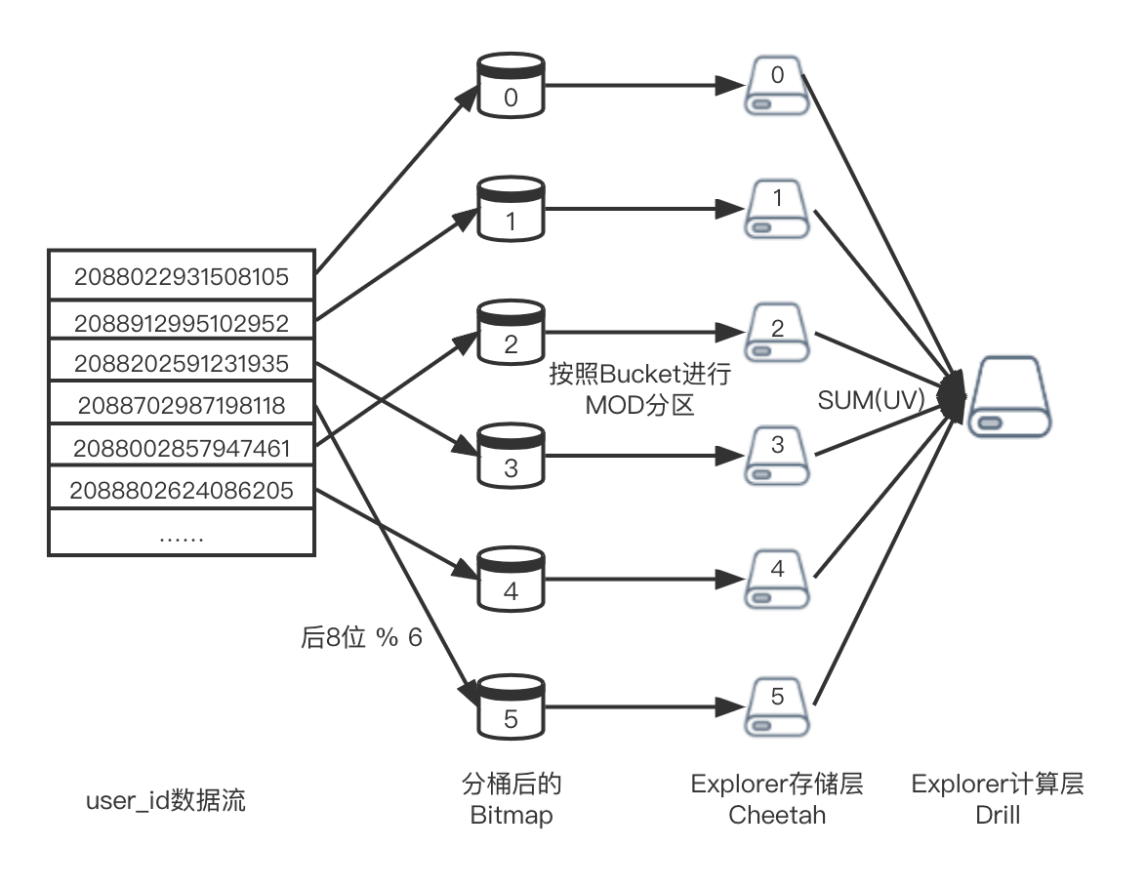
此外,为了防止数据条数膨胀太多,我们默认会采取分10个桶。如果UID量级比较大,用户也可以选择性地增加分桶个数。为了将UID均匀地划分到10个桶上面,我们采取取轮询分桶的方式,即对于第1个编号放在第1个桶里,第2个编号放在第2个桶里,不断轮询分配,直到第11个编号,又重新从第1个桶开始划分。因此最终的分桶方法为。
例如将2088022931508105按10个桶划分,则其分桶号和用户编号为
分桶号 = 93150810 % 10 = 0
用户编号 = concat(reverse(022),93150810 / 10 ) = 2209315081
分10个桶,等同于将UID的倒数第二位作为分桶号,剩下的有效位重排后作为编号。
分桶方案的优势:
- 不需要依赖外部表的输入,纯粹根据支付宝ID的特性生成新的编号,且分桶数相同的表可以相互做关联。
- 在ODPS中,存储空间大小与分桶个数关系不大,即不同的分桶个数下表的存储空间的大小都差不多。但是分桶个数与bitmap聚合算子使用的机器数呈正相关,即分桶的个数越多,则ODPS reduce时的线程数,或者Explorer查询和存储的机器数也会越多,可以充分利用分布式集群的资源,提高查询效率。
分桶方案的局限性
- 只能适用于支付宝ID,其余字符串类型的基数统计无法使用。
- 分桶后会存在数据膨胀,由于分桶个数最少为10,因此至少表的数据会膨胀10倍。在部分场景对数据条数有限制时,需要限制聚合表维度组合的个数。
- 在下游消费时,需要二次聚合,有一定的使用成本。
建序方案
建序方案也是当时实时场景中最早探索的方案,并且在一些开源的RoaringBitmap技术分享中,也是广泛使用此类方案的。例如《Flink+Hologres精准去重》 、《Hologres使用Flink+RoaringBitmap实现实时UV计算》 等。
其核心思想在于,在存储用户ID编号时,会先从一张【用户映射表】中获取用户新的编号,然后再将新的编号存储到RoaringBitmap中。【用户映射表】需要覆盖所有用户,如果用户不存在则将新的用户append至表中,并新增一个唯一编号
对于映射表的设计,首先为了保证每个新增用户的新编号是唯一的,可以采取自增主键的方式,并存储在新字段user_no中,此外,为了兼容分桶方案的编号,建序表保留了两个字段:bucket_no和bucket_user_no,分别作为分,分桶号和分桶后的用户编号。
建序方案的优势:
- 不需要分桶,也不会产生数据膨胀。
- 在下游查询时,单次聚合即可,消费成本更低。
- 可以对任意字符串都生成对应的编号,因此非支付宝ID的数据也可以存储bitmap算基数。
建序方案的局限性
- 无法利用分布式集群的资源,由于仅会有一个桶,因此如果采用Explorer进行加速,不会进行计算下推,只能使用一台Explorer机器,查询性能会大打折扣。
- 用户映射表需要高保链路来保障,首先映射表本身上游的写入任务不能发生延迟,防止下游消费的UID没有生成编号的情况,否则会导致结果不精准。其次映射表会被大量任务依赖,因此对查询请求量要求也更高。
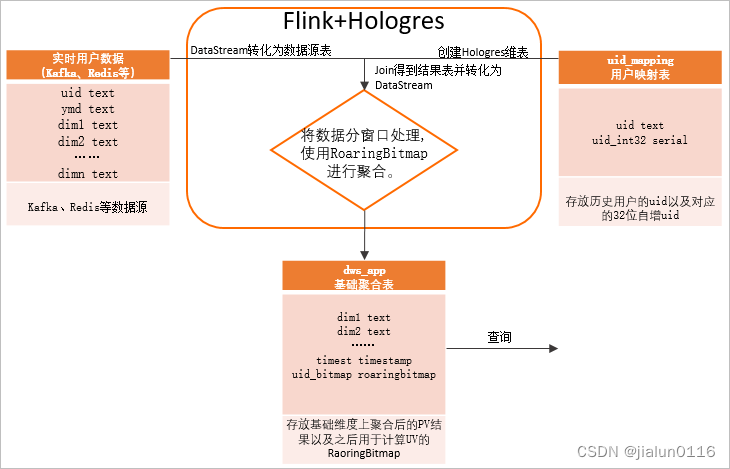
holo官网 离线UV计算
- 创建一张用户明细表,用于存放业务所有维度的明细数据。
- 创建一张历史用户映射表,存放历史每个访问过的用户ID(uid)和对应的int32数值,其中int32主要是Serial类型,便于与明细表做用户uid映射。说明RoaringBitmap类型要求用户ID必须是32位int类型且越稠密越好(用户ID最好连续),而常见的业务系统或者埋点中的用户ID很多是字符串类型,因此使用uid_mapping类型构建一张用户映射表。用户映射表利用Hologres的Serial类型(自增的32位int)来实现用户映射的自动管理和稳定映射。
- 把T+1(上一天)的明细表和历史用户映射表做Inner Join得到基础维度表。
- 根据业务逻辑,将基础维度表按照最细粒度基础维度group by,把上一天的所有数据根据最大的查询维度聚合出的uid结果放入RoaringBitmap中,并存放在聚合结果表(每天百万条)。
- 按照查询维度查询聚合结果表,对其中关键的RoaringBitmap字段做or运算进行去重后并统计基数,即可得出对应用户数UV,计数条数即可计算得出PV,达到亚秒级查询。
创建用户映射表
创建名称为uid_mapping的用户映射表,用于映射uid到32位INT类型,其DDL如下所示。
RoaringBitmap类型要求用户ID必须是32位int类型且越稠密越好(用户ID最好连续),而常见的业务系统或者埋点中的用户ID很多是字符串类型,因此使用uid_mapping类型构建一张映射表。映射表利用Hologres的Serial类型(自增的32位int)来实现用户映射的自动管理和稳定映射。
说明: 该表在本例每天批量写入场景,可为行存表也可为列存表,没有太大区别。如需要做实时数据(例如和Flink联用),需要是行存表,以提高Flink维表实时JOIN的QPS。
BEGIN;
CREATE TABLE public.zc_uid_mapping (uid text NOT NULL,uid_int32 serial,PRIMARY KEY (uid));--将uid设为clustering_key和distribution_key便于快速查找其对应的int32值
CALL set_table_property('public.zc_uid_mapping', 'clustering_key', 'uid');
CALL set_table_property('public.zc_uid_mapping', 'distribution_key', 'uid');
CALL set_table_property('public.zc_uid_mapping', 'orientation', 'row');
COMMIT;
创建聚合结果表
创建名称为dws_app的聚合结果表,用于存放RoaringBitmap聚合后的结果,其DDL如下所示。
基础维度为之后进行查询计算pv和uv的最细维度,这里以country、 prov、 city为例构建基础维表。
begin;
create table dws_dau_app(client_type text,ipv text,ds text NOT NULL, --日期字段uid32_bitmap roaringbitmap, -- UV计算pv integer, -- PV计算primary key(client_type,ipv,ds)--查询维度和时间作为主键,防止重复插入数据
);
CALL set_table_property('public.dws_dau_app', 'orientation', 'column');
--clustering_key和event_time_column设为日期字段,便于过滤
CALL set_table_property('public.dws_dau_app', 'clustering_key', 'ds');
CALL set_table_property('public.dws_dau_app', 'event_time_column', 'ds');
--distribution_key设为group by字段
CALL set_table_property('public.dws_app', 'distribution_key', 'client_type,ipv,ds');
end;
更新用户映射表和聚合结果表
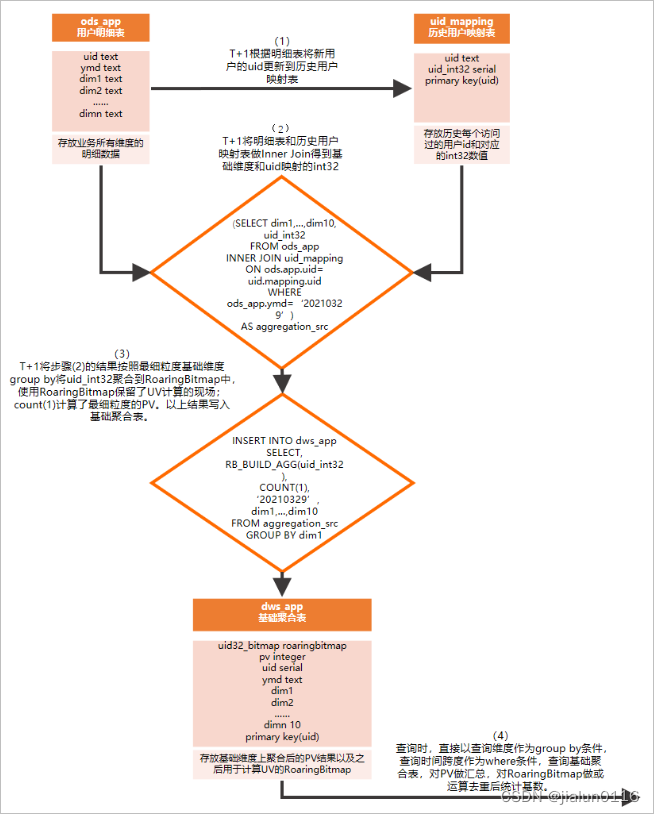
更新用户映射表每天从上一天的uid中找出新客户(用户映射表uid_mapping中没有的uid)插入到用户映射表中,命令如下。
WITH
-- 其中ymd = '20210329'表示上一天的数据user_ids AS ( SELECT imeisi FROM xxx WHERE ds = '20231119' AND imeisi is not null GROUP BY imeisi ),new_ids AS ( SELECT user_ids.imeisi FROM user_ids LEFT JOIN zc_uid_mapping ON (user_ids.imeisi = zc_uid_mapping.uid) WHERE zc_uid_mapping.uid IS NULL )
INSERT INTO zc_uid_mapping SELECT new_ids.imeisi
FROM new_ids
更新聚合结果表
更新完用户映射表后,将数据做聚合运算后插入聚合结果表,主要步骤如下。
undefined 通过明细表Inner Join用户映射表,得到上一天的聚合条件和对应的uid_int32。
undefined 按照聚合条件做聚合运算后插入RoaringBitmap聚合结果表,作为上一天的聚合结果。
undefined 每天只需进行一次聚合,存放一份数据,数据条数等于UV的量。明细表每天几亿的增量,在聚合结果表每天只需存放百万级数据。
插入数据至聚合结果表命令如下。
WITH aggregation_src AS
( SELECT client_type,is_ipv as ipv, uid_int32 FROM (SELECT imeisi,client_type,is_ipvfrom xxx t1WHERE t1.ds = '20231119' and t1.imeisi is not null)t1INNER JOIN zc_uid_mapping t2ON t1.imeisi = t2.uid
)
INSERT INTO dws_dau_app
SELECT client_type,ipv,'20231119' ds,RB_BUILD_AGG(uid_int32),COUNT(1)
FROM aggregation_src
GROUP BY client_type,ipv
;
UV、PV查询
查询时,从dws_app聚合结果表中按照查询维度做聚合计算,查询Bitmap基数,得出Group By条件下的用户数,命令如下。
-- 多天去重
SELECT client_type,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv-- ,rb_or_cardinality_agg(uid32_bitmap),sum(pv) AS pv
FROM dws_dau_app
WHERE ds in ('20231119','20231120')
GROUP BY client_type;-- 等价于
SELECT ds,client_type,count(distinct imeisi)
FROM xxx
WHERE ds in ('20231119','20231120')
GROUP by ds,client_typeSELECT client_type,ds ,RB_OR_AGG(uid32_bitmap),RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv,sum(pv) AS pv
FROM dws_dau_app
WHERE ds in ('20231119','20231120')
AND client_type = 'travel'
GROUP BY client_type,ds
;
-- 等价于
SELECT ds,client_type,count(distinct imeisi)
FROM xxx
WHERE ds in ('20231119','20231120')
GROUP by ds,client_type-- 两天同端的来访去重
SELECT client_type,RB_CARDINALITY(RB_AND_AGG(xx))
FROM
(SELECT client_type,ds ,RB_OR_AGG(uid32_bitmap) xx,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv,sum(pv) AS pvFROM dws_dau_appWHERE ds in ('20231119','20231120')GROUP BY client_type,ds
)t
GROUP BY client_type
;-- 等价于
SELECT t1.client_type,count(distinct t1.imeisi)
FROM xxx t1
INNER JOIN xxx t2
ON t1.imeisi = t2.imeisi
AND t1.client_type = t2.client_type
WHERE t1.ds = '20231119'
AND t2.ds = '20231120'
GROUP by t1.client_type
这篇关于bitmap基础介绍+holo实现离线UV计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





