本文主要是介绍电商库存系统的防超卖和高并发扣减方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果你要开发一个电商库存系统,最担心的是什么?闭上眼睛想下,当然是高并发和防超卖了!本文给出一个统筹考虑如何高并发和防超卖数据准确性的方案。读者可以直接借鉴本设计,或在此基础上做出更切合使用场景的设计。
01
背景
在今年的敏捷团队建设中,我通过Suite执行器实现了一键自动化单元测试。Juint除了Suite执行器还有哪些执行器呢?由此我的Runner探索之旅开始了!
下面用电商库存为示例,来说明如何高并发扣减库存,原理同样适用于其他需要并发写和数据一致性的场景。
1.1 库存数量模型示例
为了描述方便,下面使用简化的库存数量模型,真实场景中库存数据项会比以下示例多很多,但已经够说明原理。如下表,库存数量表(stockNum)包含商品标识和库存数量两个字段,库存数量代表有多少货可以卖。

传统通过数据库保证不超卖
库存管理的传统方案为了保证不超卖,都是使用数据库的事务来保证的:通过Sql判断剩余的库存数够用,多个并发执行update语句只有一个能执行成功;为了保证扣减不重复,会配合一个防重表来防止重复的提交,做到幂等性,防重表示例(antiRe)设计如下:

比如一个下单过程的扣减过程示例如下:
事务开始Insert into antiRe(code) value (‘订单号+Sku’)Update stockNum set num=num-下单数量 where skuId=商品ID and num-下单数量>0事务结束
面临系统流量越来越大,数据库的性能瓶颈就会暴露出来:就算分库分表也是没用的,促销的时候高并发都是针对少量商品的,最终并发流量会打向少数表,只能去提升单分片的抗量能力,所以接下来设计一种使用Redis缓存做库存扣减的方案。
02
Redis缓存做库存扣减的方案
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
2.1 综合使用数据库和Redis满足高并发扣减的原理
扣减库存其实包含两个过程:第一步是超卖校验,第二步是扣减数据的持久化;在传统数据库扣减中,两步是一起完成的。抗写的实现原理其实是巧妙的利用了分离的思想,分离开防超卖和数据持久化;首先防超卖是由Redis来完成的;通过Redis防超卖后,只要落库就可以;落库通过任务引擎,业务数据库使用商品分库分表,任务引擎任务通过单据号分库分表,热点商品的落库会被状态机分散开,消除热点。
整体架构如下:
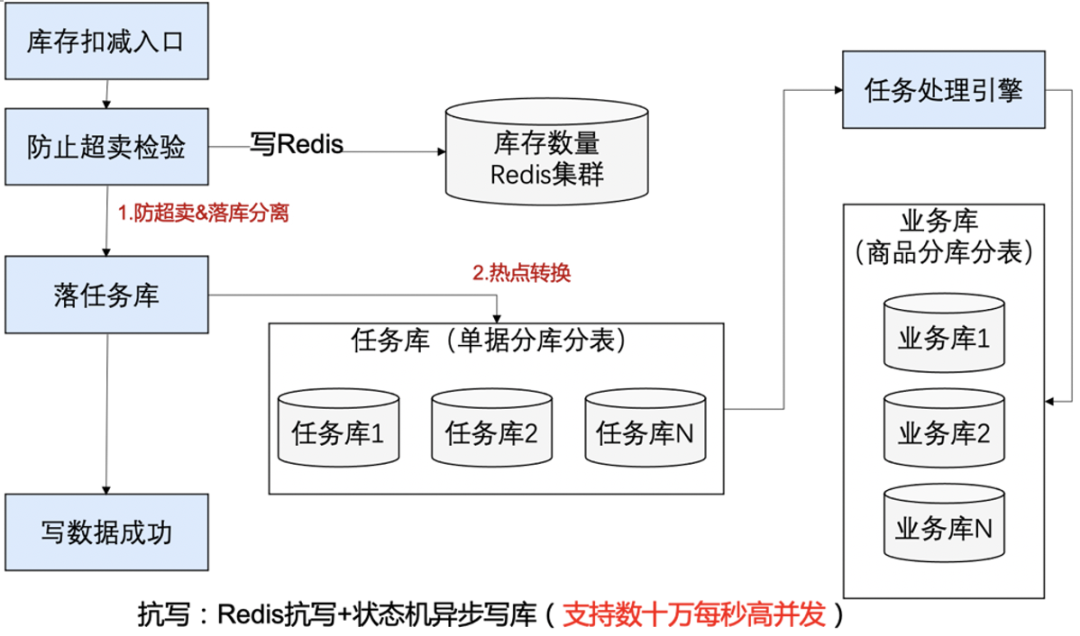
图1
第一关解决超卖检验:可以把数据放入Redis中,每次扣减库存,都对Redis中的数据进行incryby 扣减,如果返回的数量大于0,说明库存够,因为Redis是单线程,可以信任返回结果。第一关是Redis,可以抗高并发,性能Ok。超卖校验通过后,进入第二关。
第二关解决库存扣减:经过第一关后,第二关不需要再判断数量是否足够,只需要傻瓜扣减库存就行,对数据库执行如下语句,当然还是需要处理防重幂等的,不需要判断数量是否大于0了,扣减SQL只要如下写就可以。
事务开始Insert into antiRe(code) value (‘订单号+Sku’)Update stockNum set num=num-下单数量 where skuId=商品ID事务结束
要点:最终还是要使用数据库,热点怎么解决的呢?任务库使用订单号进行分库分表,这样针对同一个商品的不同订单会散列在任务库的不同库存,虽然还是数据库抗量,但已经消除了数据库热点。
整体交互序列图如下:

图2
2.2 热点防刷
但Redis也是有瓶颈的,如果出现过热SKU就会打向Redis单片,会造成单片性能抖动。库存防刷有个前提是不能卡单的。可以定制设计JVM内毫秒级时间窗的限流,限流的目的是保护Redis,尽可能的不限流。限流的极端情况就是商品本来应该在一秒内卖完,但实际花了两秒,正常并不会发生延迟销售,之所以选择JVM是因为如果采用远端集中缓存限流,还未来得及收集数据就已经把Redis打死。
实现方案可以通过guava之类的框架,每10ms一个时间窗,每个时间窗进行计数,单台服务器超过计数进行限流。比如10ms超过2个就限流,那么一秒一台服务器就是200个,50台服务器一秒就可以卖出1万个货,自己根据实际情况调整阈值就可以。
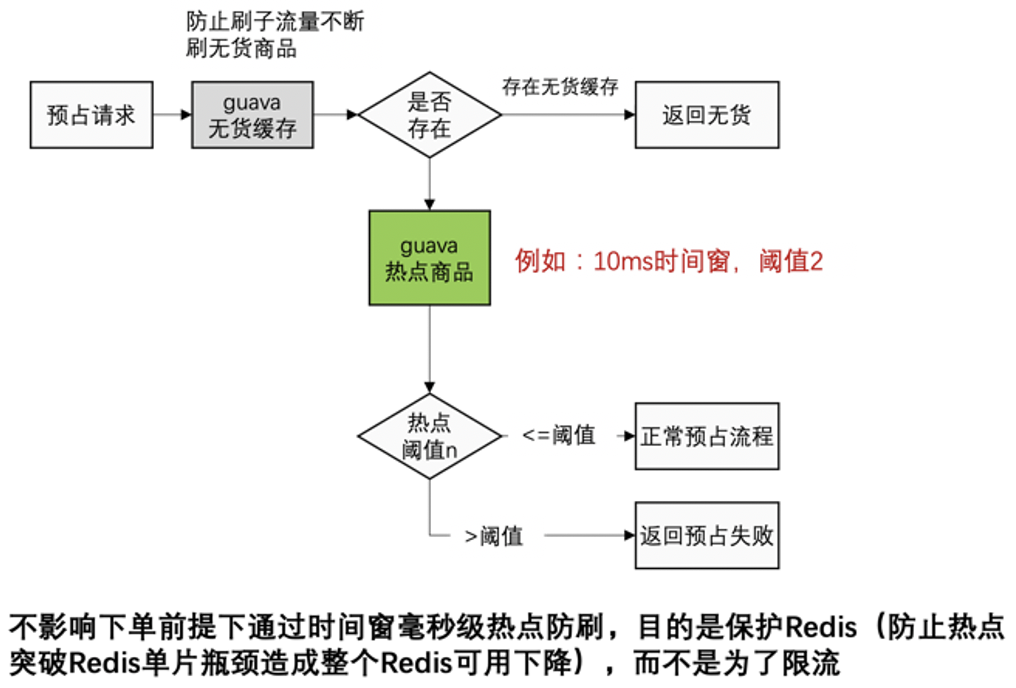
图3
2.3 Redis扣减原理
Redis的incrby 命令可以用做库存扣减,扣减项可能多个,使用Hash结构的hincrby命令,先用Reids原生命令模拟整个过程,为了简化模型下面将演示一个数据项的操作,多个数据项原理完全等同。
127.0.0.1:6379> hset iphone inStock 1 #设置苹果手机有一个可售库存(integer) 1127.0.0.1:6379> hget iphone inStock #查看苹果手机可售库存为1"1"127.0.0.1:6379> hincrby iphone inStock -1 #卖出扣减一个,返回剩余0,下单成功(integer) 0127.0.0.1:6379> hget iphone inStock #验证剩余0"0"127.0.0.1:6379> hincrby iphone inStock -1 #应用并发超卖但Redis单线程返回剩余-1,下单失败(integer) -1127.0.0.1:6379> hincrby iphone inStock 1 #识别-1,回滚库存加一,剩余0(integer) 0127.0.0.1:6379> hget iphone inStock #库存恢复正常"0"
2.3.1 扣减的幂等性保证
如果应用调用Redis扣减后,不知道是否成功,可以针对批量扣减命令增加一个防重码,对防重码执行setnx命令,当发生异常的时候,可以根据防重码是否存在来决定是否扣减成功,针对批量命名可以使用pipeline提高成功率。
// 初始化库存127.0.0.1:6379> hset iphone inStock 1 #设置苹果手机有一个可售库存(integer) 1127.0.0.1:6379> hget iphone inStock #查看苹果手机可售库存为1"1"// 应用线程一扣减库存,订单号a100,jedis开启pipeline127.0.0.1:6379> set a100_iphone "1" NX EX 10 #通过订单号和商品防重码OK127.0.0.1:6379> hincrby iphone inStock -1 #卖出扣减一个,返回剩余0,下单成功(integer) 0//结束pipeline,执行结果OK和0会一起返回
防止并发扣减后校验:为了防止并发扣减,需要对Redis的hincrby命令返回值是否为负数,来判断是否发生高并发超卖,如果扣减后的结果为负数,需要反向执行hincrby,把数据进行加回。
如果调用中发生网络抖动,调用Redis超时,应用不知道操作结果,可以通过get命令来查看防重码是否存在来判断是否扣减成功。
127.0.0.1:6379> get a100_iphone #扣减成功"1"127.0.0.1:6379> get a100_iphone #扣减失败(nil)
2.3.2 单向保证
在很多场景中,因为没有使用事务,你很难做到不超卖,并且不少卖,所以在极端情况下,可以选择不超卖,但有可能少卖。当然还是应该尽量保证数据准确,不超卖,也不少卖;不能完全保证的前提下,选择不超卖单向保证,也要通过手段来尽可能减少少卖的概率。
比如如果扣减Redis过程中,命令编排是先设置防重码,再执行扣减命令失败;如果执行过程网络抖动可能放重码成功,而扣减失败,重试的时候就会认为已经成功,造成超卖,所以上面的命令顺序是错误的,正确写法应该是:
如果是扣减库存,顺序为:1.扣减库存 2.写入放重码。
如果是回滚库存,顺序为:1.写入放重码 2.扣减库存。
2.4 为什么使用Pipeline
在上面命令中,使用了Redis的Pipeline,来看下Pipeline的原理。
非pipeline模式
request-->执行-->responserequest-->执行-->response
pipeline模式
request-->执行 server将响应结果队列化request-->执行 server将响应结果队列化-->response-->response
使用Pipeline,能尽量保证多条命令返回结果的完整性,读者可以考虑使用Redis事务来代替Pipeline,实际项目中,个人有过Pipeline的成功抗量经验,并没有使用Redis事务,正常情况下事务比pipeline慢一些,所以没有采用。
Redis事务
1)mutil:开启事务,此后的所有操作将被添加到当前链接事务的“操作队列”中
2)exec:提交事务
3)discard:取消队列执行
4)watch:如果watch的key被修改,触发dicard。
2.5 通过任务引擎实现数据库的最终一致性
前面通过任务引擎来保证数据一定持久化数据库,「任务引擎」的设计如下,把任务调度抽象为业务无关的框架。「任务引擎」可以支持简单的流程编排,并保证至少成功一次。「任务引擎」也可以作为状态机的引擎出现,支持状态机的调度,所以「任务引擎」也可以称为「状态机引擎」,在此文是同一个概念。
任务引擎设计核心原理:先把任务落库,通过数据库事务保证子任务拆分和父任务完成的事务一致性。
任务库分库分表:任务库使用分库分表,可以支撑水平扩展,通过设计分库字段和业务库字段不同,无数据热点。
2.5.1 任务引擎的核心处理流程
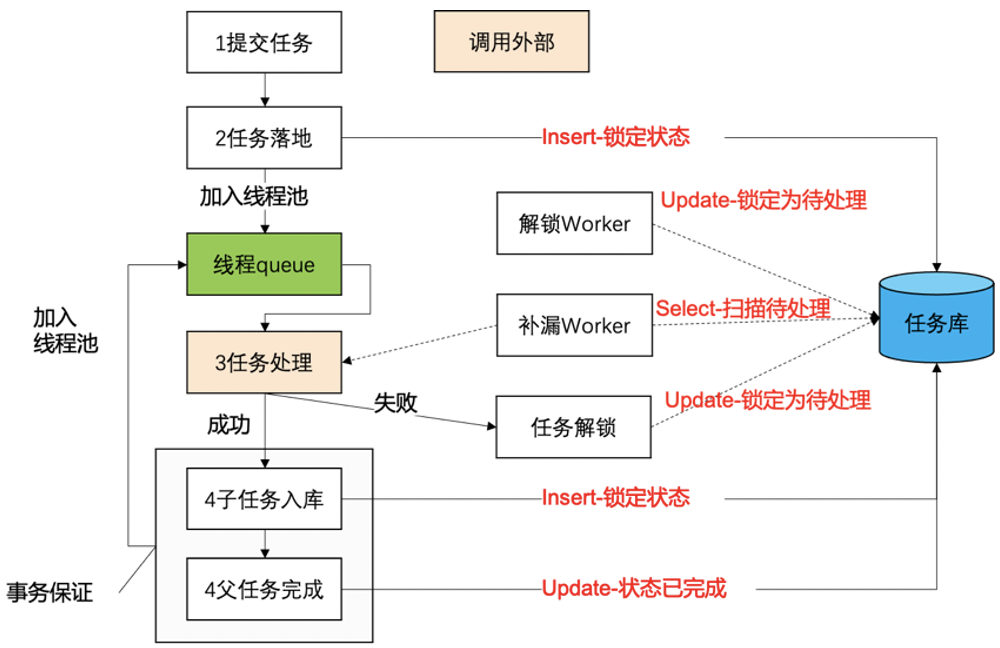
图4
第一步:同步调用提交任务,先把任务持久化到数据库,状态为「锁定处理」,保证这件事一定得到处理。
注:原来的最初版本,任务落库是待处理,然后由扫描Worker进行扫描,为了防止并发重复处理,扫描后进行单个任务锁定,锁定成功再进行处理。后来优化为落库任务直接标识状态为「锁定处理」,是为了性能考虑,省去重新扫描再抢占任务,在进程内直接通过线程异步处理。
锁定Sql参考:
UPDATE 任务表_分表号 SET 状态 = 100,modifyTime = now() WHERE id = #{id} AND 状态 = 0第二步:异步线程调用外部处理过程,调用外部处理完成后,接收返回子任务列表。通过数据库事务把父任务状态设置为已经完成,子任务落库。并把子任务加入线程池。
要点:保证子任务生成和父任务完成的事务性
第三步:子任务调度执行,并重新把新子任务落库,如果没有子任务返回,则整个流程结束。
异常处理Worker
异常解锁Worker来把长时间未处理完成的任务解锁,防止因为服务器重启,或线程池满造成的任务一直锁定无服务器执行。
补漏Worker防止服务器重启造成的线程池任务未执行完成,补漏程序重新锁定,触发执行。
任务状态转换过程
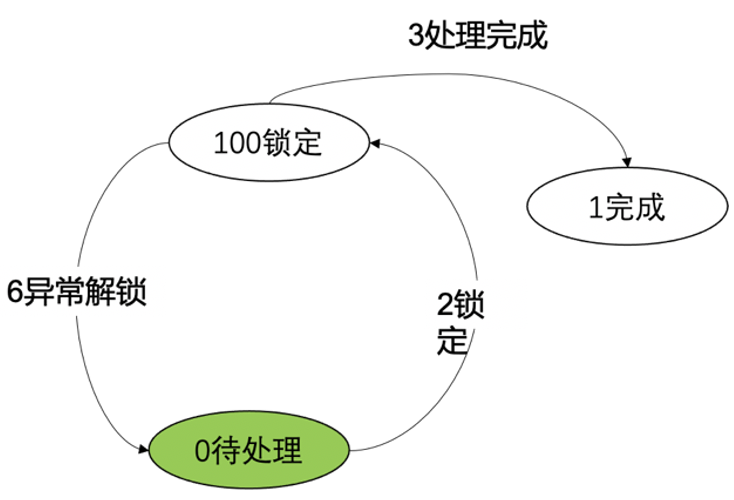
图5
2.5.2 任务引擎数据库设计
任务表数据库结构设计示例(仅做示例使用,真实使用需要完善)
任务引擎数据库容灾
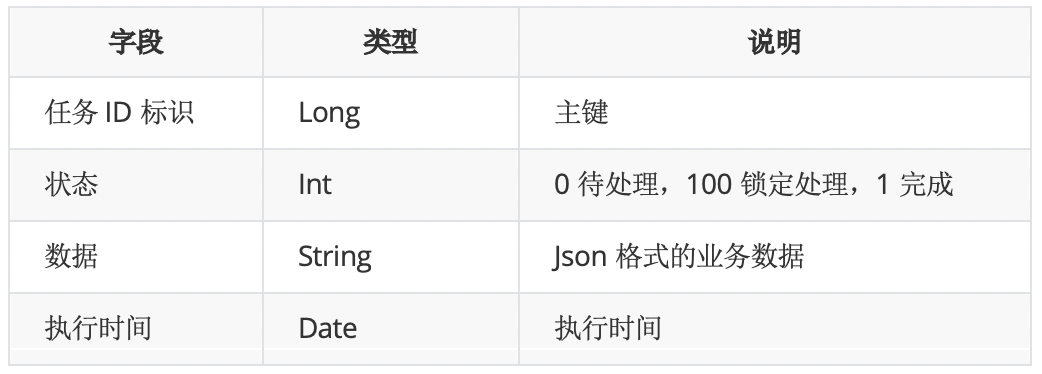
任务库使用分库分表,当一个库宕机,可以把路由到宕机库的流量重新散列到其他存活库中,可以手工配置,或通过系统监控来自动化容灾。如下图,当任务库2宕机后,可以通过修改配置,把任务库2流量路由到任务库1和3。补漏引擎继续扫描任务库2是因为当任务库2通过主从容灾恢复后,任务库2宕机时未来的及处理的任务可以得到补充处理。
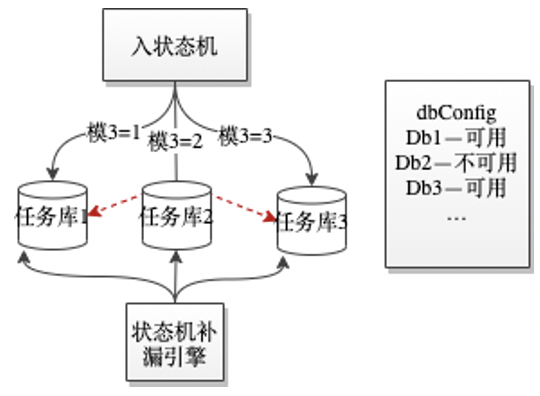
图6
任务引擎调度举例
比如用户购买了两个手机和一个电脑,手机和电脑分散在两个数据库,通过任务引擎先持久化任务,然后驱动拆分为两个子任务,并最终保证两个子任务一定成功,实现数据的最终一致性。整个执行过程的任务编排如下:
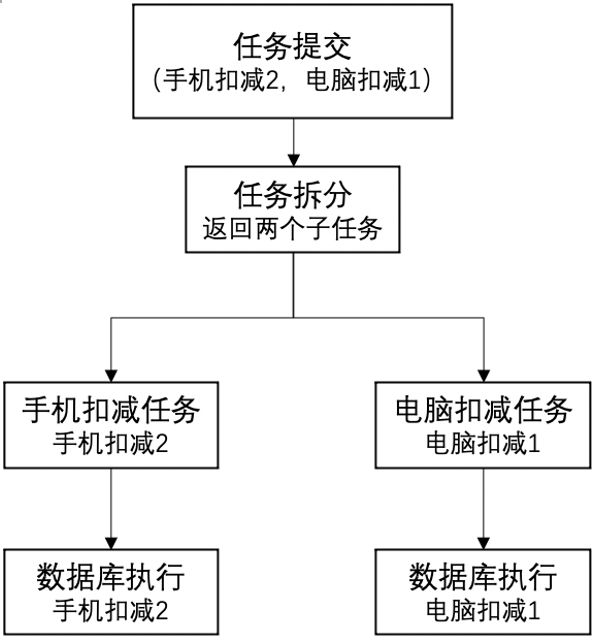
图7 任务引擎调度举例
任务引擎交互流程
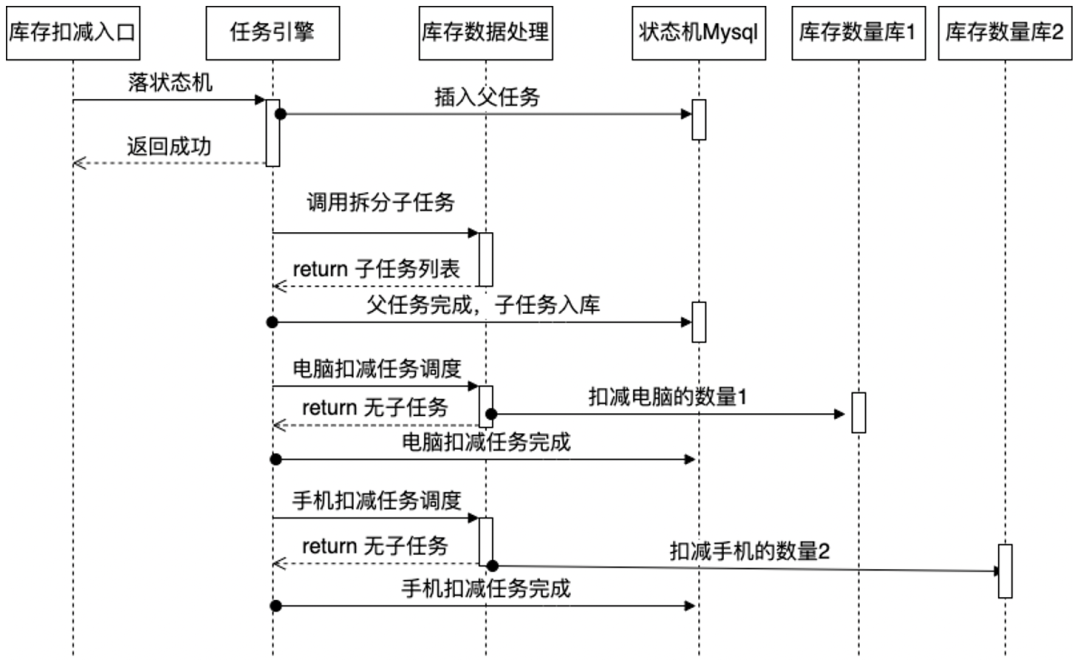
图8 任务引擎交互流程
03
总结
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
差异对比-异构数据的终极解决方案
只要有异构,一定会有差异的,为了保证差异的影响可控,终极方案还是要靠差异对比来解决。本文篇幅所限,不再展开,后续再单独成文。DB和Redis差异对比的大概过程为:接收库存变化消息,不断跟进对比Redis和DB的数据是否一致,如果连续稳定不一致,则进行数据修复,用DB数据来修改Redis的数据。
常见问题答疑
问:第一步超卖校验Redis内存扣减,第二步扣减数据的持久化,中间断了怎么办?(例:服务重启)
答:如果是服务重启,会在服务器重启之前停止这台服务器的服务;但此方案并不能保证数据的绝对一致,比如扣减redis后,应用服务器故障直接死机,这种情况下的处理就需要更复杂的方案才能保证实时一致(目前没有采取更复杂方案),可以通过另一个方案使用库存数据和用户的订单数据进行数据比对修复,达到最终一致性。
这篇关于电商库存系统的防超卖和高并发扣减方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







