本文主要是介绍基于支持向量机SVM和朴素贝叶斯NBM情感分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概述
使用大约十万条的微博评论作为训练数据,数据1表示为积极评论,0表示消极评论,利用pandas、jieba对数据进行前期处理,TFIDF将处理后的数据进行向量化,然后利用支持向量机和朴素贝叶斯对处理后的数据集进行训练。算法实现上利用python的sklearn库进行实现和训练,工具使用juypter notebook实现。
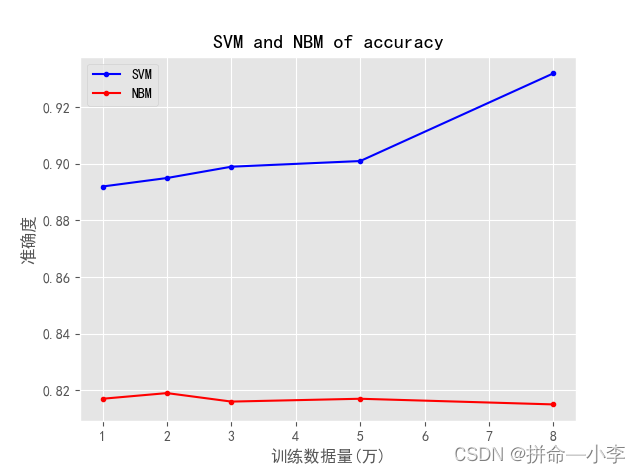
从训练的结果上来看,很明显支持向量机的训练结果是好于朴素贝叶斯算法的,SVM模型会随着数据量的增大准确度也会增大,但是实际使用过程中,朴素贝叶斯模型对非原始数据判断更加准确,而支持向量机对原始数据判断更加准确。可以说NBM的适应性要好于SVM,训练时间上,相同数据集NBM的训练速度远远快于SVM,各有利弊,下图是使用训练好的模型对非原始数据集进行的判断结果。

二、实现
注意:实现使用juypter notebook实现,所以下面也是按照顺序去执行的,切记啊;
- 数据读取
使用python的pandas读取数据集数据,数据格式如下图所示,数据总量十万多,分为消极和积极的数据集,数据来源为微博评论数据。
#读取训练数据集
import pandas as pd
test = pd.read_csv(".\\weibo_senti_100k.csv")
test_data = pd.DataFrame(test)
- 数据处理
通过观察数据集,我们发现数据中存在很多特殊符号以及无关紧要的人称和其他词语,所以我们需要进行一个停用词去除。并打乱数据集,防止训练过拟合。
####打乱数据集####
re_test_data = test_data.sample(frac=1).reset_index(drop=True)####去除特殊符号并分词####
import jieba_fast as jieba
import re
# 使用jieba进行分词
def chinese_word_cut(mytext):# 去除[@用户]避免影响后期预测精度 mytext = re.sub(r'@\w+','',mytext)# 去除数字字母的字符串mytext = re.sub(r'[a-zA-Z0-9]','',mytext)return " ".join(jieba.cut(mytext))
# apply的方法是将数据着行处理
re_test_data['cut_review'] = re_test_data.review.apply(chinese_word_cut)####停用词处理####
import re
# 获取停用词列表
def get_custom_stopwords(stop_words_file):with open(stop_words_file,encoding='utf-8') as f:stopwords = f.read()stopwords_list = stopwords.split('\n')custom_stopwords_list = [i for i in stopwords_list]return custom_stopwords_list
cachedStopWords = get_custom_stopwords(".\\stopwords.txt")
# 去除停用词方法
def remove_stropwords(mytext):return " ".join([word for word in mytext.split() if word not in cachedStopWords])
re_test_data['remove_strop_word'] = re_test_data.cut_review.apply(remove_stropwords)- 数据保存
将处理后的数据进行保存
####保存数据####
# 截取处理后的评论数据和标签
re_data = re_test_data.loc[:,['remove_strop_word','label']]
# 将数据保存为新的csv
re_data.to_csv ("re_sentiment_data.csv" , encoding = "utf_8_sig’")- 数据分割
读取处理后的数据并进行分割处理,分割方式使用的是sklearn的方法进行随机分割,分割为训练数据集X_train,y_train;测试数据集x_test,y_test;
####数据分割####
X = re_test_data['remove_strop_word']
y = re_test_data.label
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)- 向量化,训练
代码中我将SVM和NBM两种模型训练都写出来了,需要讲解的是Pipeline是将多个模型进行连接的一个模块。
####使用NBM进行训练
%%time
# 加载模型及保存模型
from sklearn.externals import joblib
# 朴素贝叶斯算法
from sklearn.naive_bayes import MultinomialNB
# TFIDF模型
from sklearn.feature_extraction.text import TfidfVectorizer
# 管道模型可将两个算法进行连接
from sklearn.pipeline import Pipeline
# 将TFIDF模型和朴素贝叶斯算法连接
TFIDF_NB_Sentiment_Model = Pipeline([('TFIDF', TfidfVectorizer()),('NB', MultinomialNB())
])
# 取三万条数据进行训练
nbm = TFIDF_NB_Sentiment_Model.fit(X_train[:80000],y_train[:80000])
nb_train_score = TFIDF_NB_Sentiment_Model.score(X_test,y_test)
joblib.dump(TFIDF_NB_Sentiment_Model, 'tfidf_nb_sentiment.model')
print(nb_train_score)####或####使用SVM进行训练####
%%time
from sklearn.svm import SVCTFIDF_SVM_Sentiment_Model = Pipeline([('TFIDF', TfidfVectorizer()),('SVM', SVC(C=0.95,kernel="linear",probability=True))
])
TFIDF_SVM_Sentiment_Model.fit(X_train[:30000],y_train[:30000])
svm_test_score = TFIDF_SVM_Sentiment_Model.score(X_test,y_test)
joblib.dump(TFIDF_SVM_Sentiment_Model, 'tfidf_svm1_sentiment.model')
print(svm_test_score)- 预测
训练好的模型之后,我们就可以进行预测了
import re
from sklearn.externals import joblib
# 获取停用词列表
def get_custom_stopwords(stop_words_file):with open(stop_words_file,encoding='utf-8') as f:stopwords = f.read()stopwords_list = stopwords.split('\n')custom_stopwords_list = [i for i in stopwords_list]return custom_stopwords_list# 去除停用词方法
def remove_stropwords(mytext,cachedStopWords):return " ".join([word for word in mytext.split() if word not in cachedStopWords])# 处理否定词不的句子
def Jieba_Intensify(text):word = re.search(r"不[\u4e00-\u9fa5 ]",text)if word!=None:text = re.sub(r"(不 )|(不[\u4e00-\u9fa5]{1} )",word[0].strip(),text)return text# 判断句子消极还是积极
def IsPoOrNeg(text):# 加载训练好的模型
# model = joblib.load('tfidf_nb_sentiment.model')model = joblib.load('tfidf_svm1_sentiment.model')# 获取停用词列表 cachedStopWords = get_custom_stopwords(".\\stopwords.txt")# 去除停用词 text = remove_stropwords(text,cachedStopWords)# jieba分词 seg_list = jieba.cut(text, cut_all=False)text = " ".join(seg_list)# 否定不处理text = Jieba_Intensify(text)y_pre =model.predict([text])proba = model.predict_proba([text])[0]if y_pre[0]==1:print(text,":此话极大可能是积极情绪(概率:)"+str(proba[1]))else:print(text,":此话极大可能是消极情绪(概率:)"+str(proba[0]))IsPoOrNeg("我好开心")预测结果如图
![]()
需要源码和数据集请+我哦~


这篇关于基于支持向量机SVM和朴素贝叶斯NBM情感分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







