本文主要是介绍零基础入门金融风控-贷款违约预测-Task01,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有幸参加了阿里云举办的零基础入门金融风控-贷款违约预测训练营。收获颇多。
每天记录一些自己之前的知识盲点,需经常温习。
一、赛题理解:
该赛题是金融风控中关于贷款违约情况的预测。盲猜是个机器学习中监督学习的分类问题。从训练集和测试集的对比中可以得到标签label的字段。
1、首先观察训练集train.csv和testA.csv,将train.csv和testA.csv的shape分别打印出来,发现居然train.shape的列数比testA.shape的列数少两列。这不科学啊~
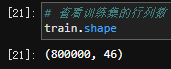
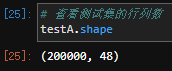
结果发现里面的n2有很多重复内容,果断删除~

删除以后的结果:
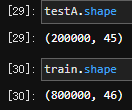
这次就对了,train.shape的列数比testA.shape的列数刚好多一个。通过对比得出,label即为isDefault。
是一个明显的二分类问题,0和1两类。但是目前还不清楚0和1分别代表什么。
2、小组开会,分析了各个字段,得出的结论:
| Field | Description | 备注 | 数据类型 | 数据示例 |
| id | 为贷款清单分配的唯一信用证标识 | 本次数据的主键,申请时生成 | int64 | |
| loanAmnt | 贷款金额 | 具体发放的金额,因为有可能产生罚息所以是浮点数 | float64 | |
| term | 贷款期限(year) | int64 | ||
| interestRate | 贷款利率 | float64 | ||
| installment | 分期付款金额 | 与还款方式有关:先本后息、先息后本、本息 | float64 | |
| grade | 贷款等级 | 与个人征信有关,征信等级 | object | E,D,D,A |
| subGrade | 贷款等级之子级 | 与个人征信有关,征信等级,跟上一行有信息重合,考虑删除一行 | object | E2,D2,D3,A4 |
| employmentTitle | 就业职称 | 已脱敏 | float64 | |
| employmentLength | 就业年限(年) | 这个数据有点脏 | object | 10+ years |
| homeOwnership | 借款人在登记时提供的房屋所有权状况 | 0:无;1:一套;2:两套 | int64 | 0,1,2 |
| annualIncome | 年收入 | 单位为元 | float64 | |
| verificationStatus | 验证状态 | 不太清楚是什么 | int64 | 0,1,2 |
| issueDate | 贷款发放的月份 | 贷款发放的年月 | object | 2014/1/1;2018/12/1 |
| purpose | 借款人在贷款申请时的贷款用途类别 | 已脱敏 | int64 | |
| postCode | 借款人在贷款申请中提供的邮政编码的前3位数字 | 在业务场景中会使用到:东三省、福建预期较多 | float64 | 159,59 |
| regionCode | 地区编码 | 跟上述数据关联性位置 | int64 | 48,7 |
| dti | 债务收入比 | 小额贷/收入(银行流水) | float64 | |
| delinquency_2years | 借款人过去2年信用档案中逾期30天以上的违约事件数 | 业务重点考虑点 | float64 | |
| ficoRangeLow | 借款人在贷款发放时的fico所属的下限范围 | 业内的一个评分,有范围,5个单位为一个范围 | float64 | 660 |
| ficoRangeHigh | 借款人在贷款发放时的fico所属的上限范围 | 业内的一个评分,有范围,6个单位为一个范围 | float64 | 705 |
| openAcc | 借款人信用档案中未结信用额度的数量 | 笔数 | float64 | |
| pubRec | 贬损公共记录的数量 | 公开的违规信息,可能是法院起诉等公开信息 | float64 | |
| pubRecBankruptcies | 公开记录清除的数量 | 公开的违规被清除信息 | float64 | |
| revolBal | 信贷周转余额合计 | 循环贷 | float64 | 19,723,220 |
| revolUtil | 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额 | float64 | ||
| totalAcc | 借款人信用档案中当前的信用额度总数 | ? | float64 | |
| initialListStatus | 贷款的初始列表状态 | ? 0为否 | int64 | 0,1 |
| applicationType | 表明贷款是个人申请还是与两个共同借款人的联合申请 | 是否有共借人 0为否 | int64 | 0,1 |
| earliesCreditLine | 借款人最早报告的信用额度开立的月份 | 年月 | object | |
| title | 借款人提供的贷款名称 | 已脱敏 | float64 | |
| policyCode | 公开可用的策略_代码=1新产品不公开可用的策略_代码=2 | 训练集数据均为1 | float64 | 1 |
| n系列匿名特征 | 匿名特征n0-n14,为一些贷款人行为计数特征的处理 | float64 |
3、评测标准
二分类问题很自然可以联想到混淆矩阵,进而有准确率、精确率、召回率、F1值、PR曲线、ROC曲线等一系列指标。其中,ROC曲线下的面积称为AUC(Area Under Curve,曲线下面积),该值介于0.5~1之间,且越大越好。
天池赛题的评价标准恰好为AUC指标。计算AUC值需要sklearn.metric中的roc_auc_score函数。
为了赛题的可解释性,需要将数据进行可视化,并且尽可能计算出相关的数据,逐步分析结果。
4、结果提交格式
结果提交格式保留了传统的天池比赛和Kaggle比赛的提交形式,采用.csv格式进行提交。第一列为id,第二列为预测的label,即isDeafult。
有一点需要注意,不能用pandas自动生成的index。故生成.csv文件的代码应为:pd.to_csv('submission.csv', index = False)。
5、个人关于本次比赛的初步想法
赛题含有强烈的金融行业的垂直属性,还需要咨询相关行业的专家分析各个字段的含义,明确可以删除的列,需要填充的列。这个训练集的特征工程比较难,且很费时。是块儿最难啃的骨头。
二分类可选的模型很多。可以考虑先采用逻辑回归LR做个baseline形式的代码,然后逐步通过KNN、SVM、GBDT和XGBoost等算法进行训练、预测。
这篇关于零基础入门金融风控-贷款违约预测-Task01的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






