本文主要是介绍决策树算法及相关内容简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、算法简介
1、决策树概念
决策树:本质上是一个树形结构,每个内部节点代表了一种属性判断,每个分支代表了一种结果的输出,每个叶节点代表一种分类结果,本质上是一颗由多个判断节点组成的树。
二、决策树分类原理
1、熵(entropy)
(1)概念
物理学上,熵是物体混乱程度的量度。
越有序,熵越低,越无序,熵越高。
(2)信息熵(entropy)
从信息的完整性上进行描述:当系统的有序状态一致时,数据集中的地方熵值低,分散的地方熵值高。
从信息有序性上进行描述:当系统数据量统一时,系统越有序,熵值越低,越无序,熵值越高。
信息熵计算公式:

2、信息增益
概念:以某特征划分数据集前后信息熵的差值,熵可以代表样本集合的不确定性,所以可用以某特征划分数据集前后信息熵差值的大小来衡量使用当前特征划分集合效果的好坏。
信息增益=entropy(前)- entropy(后)、
ps:ED3就是以信息熵增益最大为准则来选择划分属性的算法。
ED3缺点
(1)只能对离散型数据构造决策树
(2)信息增益准则偏好分组较多属性
信息增益大佬计算实例
3、信息增益率
信息增益准则偏好分组较多的属性,为了避免这种不利影响,决策树算法C4.5不使用信息增益,而是使用信息增益率。
信息增益率是信息增益与其对应属性固有值(分裂信息度量)的比值。
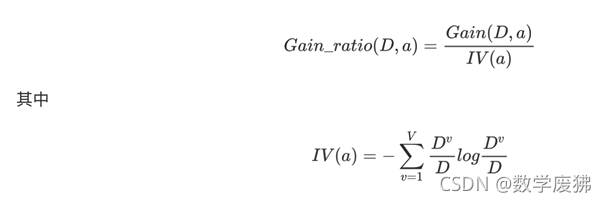
C4.5的优点
(1)使用信息增益率,解决了信息增益准则偏好分组较多属性的问题。
(2)使用了一种后剪枝方法,避免了树的高度无限制的增长,出现信息过拟合的情况。(C4.5不一定为二叉树)
(3)对缺失值的处理,一般会为缺失值附上训练实例中此属性的最常见值,C4.5选择为缺失值的每一种可能赋上一个概率。
缺点
对内存要求较高,低效。
4、基尼值与基尼指数
CART算法是一种著名的决策树算法,采用了严格的二叉树模型,使用基尼指数来选择划分属性
基尼值:数据集中任意抽取两个样本,他们类别标志不一致的概率,故Gini值越小,数据集纯度越高。



三、cart剪枝
1、原因
(1)噪声、样本冲突、即数据错误
(2)特征(属性)不能完全作为分类标准
(3)巧合的规律性(主要是由于样本数据集不够大)
2、常用方法
(1)预剪枝
①指定每个节点所包含的最小样本数
②指定最大深度
③当节点上的熵小于某个值时,不再划分
(2)后剪枝
在已经生成拟合决策树上进行剪枝,可得到简化版的剪枝决策树。(从下像上,只要结果不比当前结果优,就进行剪枝)
四、特征提取
定义:将任意数据(如图片、音频、视频、文本)转换为可用于机器学习的数据特征。
分类:字典特征提取,文本特征提取,图像特征提取
API
sklearn.feature_extraction
1、字典特征提取
DictVectorizer通过使用scikit-learn的estimators,将特征名称与特征值组成的映射字典构成的列表转换成Numpy数组或者Scipy.sparse矩阵。
当特征的值是字符串时,这个转换器将进行一个二进制One-hot编码。One-hot编码是将特征所有可能的字符串值构造成布尔型值。例如: 特征f有一个值ham,一个值spam,转换后会变成两个特征f=ham和f=spam。
转换器只会将字符串形式的特征值转换成One-hot编码,数值型的不会转换。
一个字典中样本没有的特征在结果矩阵中的值是0.
参数
dtype:特征值的类型。
separator:可选,string。当特征值为string时,用来连接特征名称和值的符号,默认为’=’。
例,当特征名为’f’,而特征值含有’pam’和’spam’时,one-hot对应的向量名为’f=pam’和’f=spam’
sparse:boolean,可选。默认为True,转换过程中生成一个scipy.sparse矩阵。当数据多表示为one-hot
类型时,占用内存过大,稀疏表示可以节约大量空间。
sort:boolean,可选,默认为True。转化完成后对feature_names_和vocabulary_按字典序排列。
属性
feature_names_:长度为n_features的列表,含有所有特征名称.
vocabulary_:字典类型,特征名映射到特征在list中的index的字典对象
方法
fit(X,y=None):学习一个将特征名称映射到索引的列表,返回值是其自身
fit_transform(X,y=None):学习一个将特征名称映射到索引的列表,返回值是为对应的特征向量,一般2维,等价于fit(X).transform(X)
get_feature_names():返回一个含有特征名称的列表,通过索引排序,如果含有one-hot表示的特征,则显示相应的特征名
get_params(deep=True):返回模型的参数(string到任何类型的映射)
inverse_transform(X,dict_type=<class ‘dict’>):
将转化好的特征向量恢复到转化之前的表示状态。X必须是通过transform或者fit_transform生成的向量。
X:shape(n_samples,n_features)
返回字典对象的列表,长度为n_samples。
restrict(support,indices=False):
对支持使用特征选择的模型进行特征限制,例如只选择前几个特征
support:矩阵类型,boolean或者索引列表,一般是feature
selectors.get_support()的返回值。
indices:boolean,可选,表示support是不是索引的列表
返回值是其自身(DictVectorizer)
set_params(**params):设置DictVectorizer的参数
API
transfer=sklearn.feature_extraction.DictVectorizer()
先实例化转化器,再使用fit方法
2、文本特征提取
(1)CountVectorizer
CountVectorizer可以将文本文档集合转换为token计数矩阵。(token可以理解成词)
CountVectorizer处理文本的步骤应该是先使用 preprocessor参数提供预处理器,对文本进行预处理。在使用tokenizer对文本进行拆分。再使用fit拟合得到词汇表,再使用transform转换为计数矩阵。
参数
input:
默认content 可选 filename、file、content
如果是filename,传给fit的参数必须是文件名列表
如果是file,传给fit的参数必须是文件对象,有read方法
如果是content,则是字符串序列或者是字节序列
encoding
默认是utf-8
decode_error:
默认是strict。当用来分析的字节序列中包含encoding指定的编码集中没有的字符时的指令。strict的意思是直接报错UnicodeDecodeError。ignore是忽视。replace是替换。
strip_accents:
默认是None。在文本预处理的过程去除掉重音(音调). ascii方法较快,仅作用于ASCII码。unicode码稍慢,适合任意字符。None就是不做这个操作。
analyzer:
默认是word。一般使用默认,可设置为string类型,如’word’, ‘char’, ‘char_wb’,还可设置为callable类型,比如函数是一个callable类型
preprocessor: 默认是None,可传入callable
tokenizer:
在保留预处理和N-gram生成步骤的同时重写字符串标记化步骤。仅适用于anlayzer = “word”.
ngram_range:tuple (min_n, max_n) 默认 (1, 1)
N值的范围的下界和上界用于提取不同的N-gram。n的所有值都将使用Min n=n<=Max n。
stop_words : string {‘english’}, list, or None (default)
english表示使用内置的英语单词停用表
如果是list列表,该列表中的词会作为停止词。仅适用于analyzer=word。
如果是None,就不会使用停止词。max_df参数可以被设置在(0.7, 1.0)的范围内,用来基于语料库内文档中术语的频率来自动检测和过滤停止词。
ps:在语句中,有一些词(如:大概、几乎、一些)对文章分类作用不大,为了减小噪音,可设置停止词(可以在网上找到现成的停止词库)
lowercase: 默认是True,将文本转换为小写。
token_pattern: 默认r"(?u)\b\w\w+\b"
使用正则表达式表示什么样的形式才是一个token,只有当analyzer=word是才有用。默认的正则表达式是至少2个或者更多的字母。标点符号被完全忽略或者只是作为分隔符。
max_df: 默认是1 [0, 1]之间的小数或者是整数。
当构建词汇表时,忽略那些文档频率严格高于给定阈值的术语(特定于语料库的停止词)。如果是浮点数,参数表示一个文件的比例。如果是整数,表示术语的绝对计数。如果vocabulary不是None,则忽略此参数。
min_df: 与max_df类似。 默认是1.
max_features: 默认是None, None或者是整数。
如果不是None,表示建立一个只考虑最前面的max_features个术语来表示语料库。如果vocabulary参数不是None的话,忽略这个参数。
vocabulary: 默认是None。Mapping或者Iterable
无论是Mapping还是字典,items是key, 索引是value,都是特征矩阵中的索引,或者是可迭代的terms。如果没有给出,则从输入文档中确定词汇表。映射中的索引不应该重复,并且不应该在0和最大索引之间有任何间隙。
binary:
如果为真,则所有非零计数设置为1。这对于模拟二进制事件而不是整数计数的离散概率模型是有用的。
dtype :
fit_transform或者transform返回的matrix的类型。
属性
vocabulary_: 词和词在向量化后的计数矩阵中列索引的映射关系。
stop_words_: 停止词集合。
方法
build_analyzer:
返回一个进行预处理和分词的分析器函数对象。
build_preprocessor:
返回一个在分词之前进行预处理的可调用方法。
build_tokenizer:
返回一个将字符串分为词语序列的方法
decode:
将输入转换为unicode字符表示
解码的策略参照vectorizer的参数。
fit(raw_documents, y=None):
学习出一个词汇字典。这个词汇字典的格式是{word, word在向量矩阵中的列的索引}
raw_documents是string,unicode,file对象构成的可迭代对象。
fit_transform:
学习词汇字典并转换为矩阵。等同于先调用fit,再调用transform,不过更有效率。
返回向量矩阵。[n_samples, n_features]。行表示文档,列表示特征。
get_feature_names:
特征名称列表
get_params:
获得向量器的参数。
get_stop_words:
获取stopword列表
inverse_transform(X):
返回每个文档中数量不是0的词语
返回结果是array组成的列表
set_params:
设置估计器参数
transform(raw_documents):
将文档转换成词汇计数矩阵。使用fit拟合的词汇表或者提供给构造函数的词汇表来提取传入文档的词语计数。
API
sklearn.feature_extraction.text.CountVectorizer()
ps:若想查看整体内容,没有sparse,可对使用toarray()方法查看整体内容。
transfer = feature_extraction.text.CountVectorizer()
newdata = transfer.fit_transform(data)
print(newdata.toarray())
在处理时,英文默认以空格分开,每个单词对应一个特征值,单个字母的单词(I)不计入特征,达到了分词的效果。但中文并不能直接按字分割,仍然以空格分割,所以处理中文时需要先进行分词。
jieba分词
jieba模块的作用 jieba是优秀的第三方中文词库 ,可以实现分词作用,处理汉字时方便快捷
这里可以使用jieba模块的cut()来对中文数据进行分词处理
大佬详细讲解
text=' '.join(list(jieba.cut(text)))
(2)TfidfVectorizer
TfidfVectorizer是为了统计一些词语在文章中的占比情况,反应一个词在一个语料库中的重要程度。
常用于文章分类、文本特征提取。
原理
把词转换为向量,TF是词频,idf是逆文本频率,idf表现一个词在所有文本中出现的频率,它出现的越多说明越不重要,idf即是一个词的重要程度体现,越高越重要。
注
在使用这个函数的时候,需要注意的是,它所输出的结果是一个scipy.sparse.csr.csr_matrix,我们在将结果输入到模型中的时候,需要注意模型是否支持这种格式,如果不支持,就要先将sparse metrix转化成numpy的格式。
参数
input:string{‘filename’, ‘file’, ‘content’}
如果是’filename’,序列作为参数传递给拟合器,预计为文件名列表,这需要读取原始内容进行分析
如果是’file’,序列项目必须有一个”read“的方法(类似文件的对象),被调用作为获取内存中的字节数
否则,输入预计为序列串,或字节数据项都预计可直接进行分析。
encoding:string, ‘utf-8’by default
如果给出要解析的字节或文件,此编码将用于解码
decode_error: {‘strict’, ‘ignore’, ‘replace’}
如果一个给出的字节序列包含的字符不是给定的编码,指示应该如何去做。默认情况下,它是’strict’,这意味着的UnicodeDecodeError将提高,其他值是’ignore’和’replace’
strip_accents: {‘ascii’, ‘unicode’, None}
在预处理步骤中去除编码规则(accents),”ASCII码“是一种快速的方法,仅适用于有一个直接的ASCII字符映射,"unicode"是一个稍慢一些的方法,None(默认)什么都不做
analyzer:string,{‘word’, ‘char’} or callable
定义特征为词(word)或n-gram字符,如果传递给它的调用被用于抽取未处理输入源文件的特征序列
preprocessor:callable or None(default)
当保留令牌和”n-gram“生成步骤时,覆盖预处理(字符串变换)的阶段
tokenizer:callable or None(default)
当保留预处理和n-gram生成步骤时,覆盖字符串令牌步骤
ngram_range: tuple(min_n, max_n)
要提取的n-gram的n-values的下限和上限范围,在min_n <= n <= max_n区间的n的全部值
stop_words:string {‘english’}, list, or None(default)
如果为english,用于英语内建的停用词列表
如果为list,该列表被假定为包含停用词,列表中的所有词都将从令牌中删除
如果None,不使用停用词。max_df可以被设置为范围[0.7, 1.0)的值,基于内部预料词频来自动检测和过滤停用词
lowercase:boolean, default True
在令牌标记前转换所有的字符为小写
token_pattern:string
正则表达式显示了”token“的构成,仅当analyzer == ‘word’时才被使用。两个或多个字母数字字符的正则表达式(标点符号完全被忽略,始终被视为一个标记分隔符)。
max_df: float in range [0.0, 1.0] or int, optional, 1.0 by default
当构建词汇表时,严格忽略高于给出阈值的文档频率的词条,语料指定的停用词。如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。
min_df:float in range [0.0, 1.0] or int, optional, 1.0 by default
当构建词汇表时,严格忽略低于给出阈值的文档频率的词条,语料指定的停用词。如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。
max_features: optional, None by default
如果不为None,构建一个词汇表,仅考虑max_features–按语料词频排序,如果词汇表不为None,这个参数被忽略
vocabulary:Mapping or iterable, optional
也是一个映射(Map)(例如,字典),其中键是词条而值是在特征矩阵中索引,或词条中的迭代器。如果没有给出,词汇表被确定来自输入文件。在映射中索引不能有重复,并且不能在0到最大索引值之间有间断。
binary:boolean, False by default
如果未True,所有非零计数被设置为1,这对于离散概率模型是有用的,建立二元事件模型,而不是整型计数
dtype:type, optional
通过fit_transform()或transform()返回矩阵的类型
norm:‘l1’, ‘l2’, or None,optional
范数用于标准化词条向量。None为不归一化
use_idf:boolean, optional
启动inverse-document-frequency重新计算权重
smooth_idf:boolean,optional
通过加1到文档频率平滑idf权重,为防止除零,加入一个额外的文档
sublinear_tf:boolean, optional
应用线性缩放TF,例如,使用1+log(tf)覆盖tf
例
text = ['君不见黄河之水天上来,奔流到海不复回。','君不见高堂明镜悲白发,朝如青丝暮成雪。','人生得意须尽欢,莫使金樽空对月。','天生我材必有用,千金散尽还复来。','烹羊宰牛且为乐,会须一饮三百杯。','岑夫子,丹丘生,将进酒,杯莫停。','与君歌一曲,请君为我倾耳听。','钟鼓馔玉不足贵,但愿长醉不复醒。','古来圣贤皆寂寞,惟有饮者留其名。','陈王昔时宴平乐,斗酒十千恣欢谑。','主人何为言少钱,径须沽取对君酌。','五花马、千金裘,呼儿将出换美酒,与尔同销万古愁。'
]
newtext = []
for i in text:temp = ' '.join(list(jieba.cut(i)))newtext.append(temp)
print(newtext)
transfer = feature_extraction.text.TfidfVectorizer()
a = transfer.fit_transform(newtext)
print(transfer.get_feature_names())
print(a)
print(a.toarray())
同时,在一些需要将TfidfVectorizer()函数的输出结果进行整合计算的时候,最好转化为numpy格式。
reviews, labels = load_data(train)
word_tfidf, char_tfidf = train_tfidf(all_text)
w = word_tfidf.transform(reviews).todense()
c = char_tfidf.transform(reviews).todense()
train_reviews = np.hstack((w,c))
print(len(labels))
print(len(reviews))
print(c.shape)
print(w.shape)
print(train_reviews.shape)
五、决策树
1、API
from sklearn.tree import DecisionTreeClassifier
DecisionTreeClassifier(criterion='gini''entropy',min_samples_split=2,min_samples_leaf=2,max_depth=5,random_state=555)
criterion=‘gini’:特征选择标准,默认为’gini‘(基尼系数),也可选择’entropy’(信息增益)。
min_samples_split=2:内部节点再划分所需最小样本数。
min_samples_leaf=1:叶节点最小样本数,若某一节点样本数小于此值,则会和兄弟节点一起被剪枝。
max_depth:决策树最大深度,默认不做限制。
random_state:随机种子。
2、案例
泰坦尼克号乘客生存预测
数据集:titanic
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
#导入数据集
train_data=pd.read_csv('titanictrain.csv')
test_data=pd.read_csv('titanictest.csv')
gender=pd.read_csv('titanicgender_submission.csv')
#查看、分析数据集
pd.set_option('display.max_columns',1000)
print(test_data.head())
print(train_data.head())
#print(test_data.describe())
#确认特征值、目标值
x=train_data[['Pclass','Sex','Age' ]]
x_last=test_data[['Pclass','Sex','Age' ]]
y=train_data[['Survived']]
#分割数据集
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=2,test_size=0.2)
#替换缺失值
x_train=x_train.copy()
x_train['Age'].fillna(value=x_train['Age'].mean(),inplace=True)
x_test=x_test.copy()
x_test['Age'].fillna(value=x_test['Age'].mean(),inplace=True)
x_last=x_last.copy()
x_last['Age'].fillna(value=x_last['Age'].mean(),inplace=True)
#特征工程(字典特征提取,将sex由string转换为float)
x_train=x_train.to_dict(orient='records')
x_test=x_test.to_dict(orient='records')
x_last=x_last.to_dict(orient='records')
transfer=DictVectorizer()
x_train=transfer.fit_transform(x_train)
x_test=transfer.fit_transform(x_test)
x_last=transfer.fit_transform(x_last)
#构建决策树
estimator=DecisionTreeClassifier(max_depth=10,min_samples_split=2)
estimator.fit(x_train,y_train)
#mx评估
y_pre=estimator.predict(x_test)
print(y_pre)
sco=estimator.score(x_test,y_test)
print(sco)
#使用模型预测
print(estimator.predict(x_last))
3、可视化
使用matplotlib.pyplot的plot_tree进行可视化
#保存模型并可视化
import matplotlib.pyplot as plt
from sklearn.tree import export_graphviz,plot_tree
export_graphviz(estimator,out_file='./titanic.dot',feature_names=['Age','Pclass','male','female'])
plt.figure(figsize=[100,80])
plot_tree(estimator,filled=True,feature_names=['Age','Pclass','male','female'])
plt.savefig('./titanic.png')
plt.show()
输出结果
这篇关于决策树算法及相关内容简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






