本文主要是介绍Python教程;一起爬取娱乐圈的排行榜数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
想关注你的爱豆最近在娱乐圈发展的怎么样吗?本文和你一起爬取娱乐圈的排行榜数据,来看看你的爱豆现在排名变化情况,有几次登顶,几次进了前十名呀。
一、网站原始信息
我们先来看下原始的网站页面
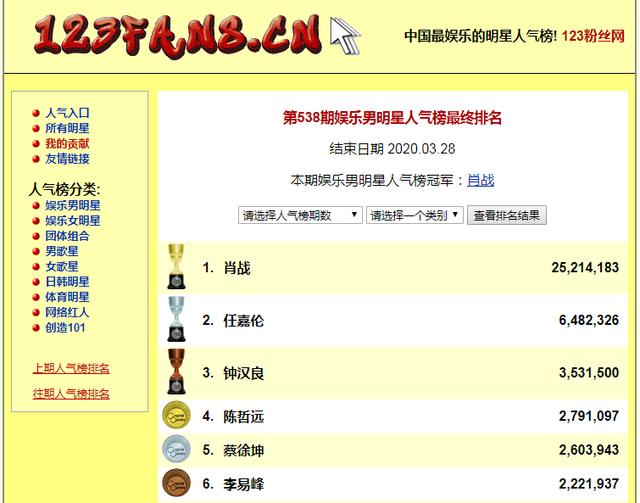
如果我们想一个一个复制这些数据,再进行分析,估计要花一天的时间,才可以把明星的各期排行数据处理好。估计会处理到崩溃,还有可能会因为人为原因出错。
而用爬虫,半个小时不到就可以处理好这些数据。接下来看看怎么把这些数据用Python爬下来吧。
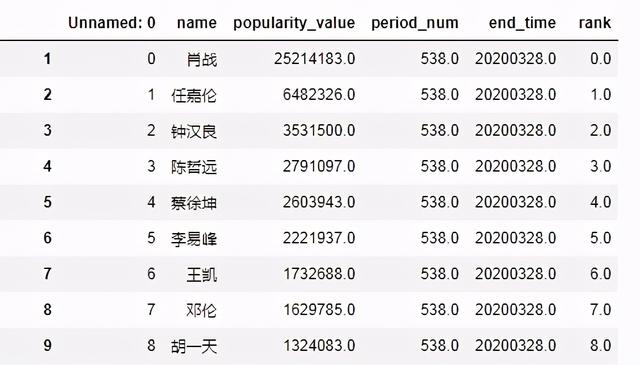
二、先来看下爬取后数据的部分截图
1 男明星人气榜数据
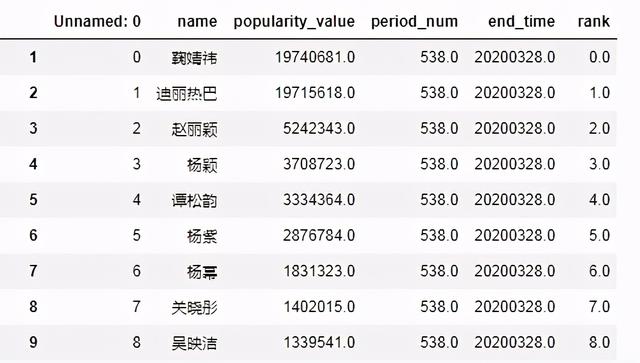
2 女明星人气榜数据
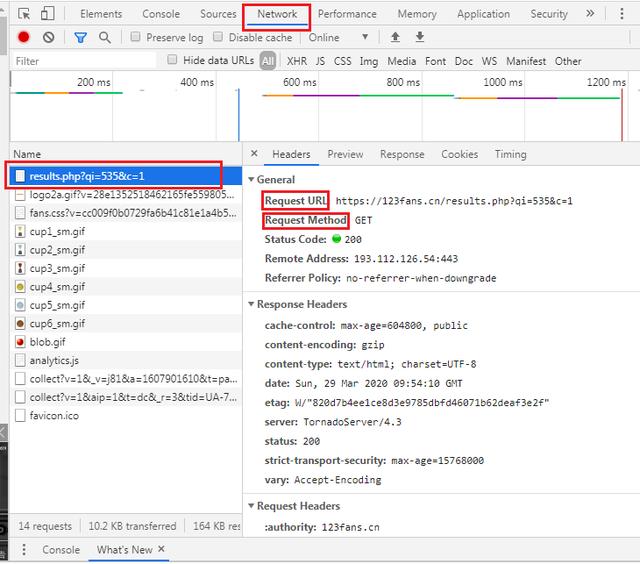
三、如何获取123粉丝网的爬虫信息
以下是获取代码用到信息的具体步骤:
- step1:浏览器(一般用火狐和Google我用的360)中打开123粉丝网
- step2:按键盘F12 -> ctrl+r
- step3: 点击results.php -> 到Headers中找到代码所需的参数
四、分步爬虫代码解析
1 用Python中的Requests库获取网页信息
新手学习,Python 教程/工具/方法/解疑+V:itz992#爬取当前页信息,并用BeautifulSoup解析成标准格式
import requests #导入requests模块
import bs4url = "https://123fans.cn/lastresults.php?c=1"
headers = {'User-Agent':'Mozilla/5.0 (Windows N这篇关于Python教程;一起爬取娱乐圈的排行榜数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








