本文主要是介绍【MySQL数据库原理】数据库批量导入美团NLP分类数据集Meituan-Dianping/asap,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 数据集简单介绍
- 完整代码实现
- 参考资料
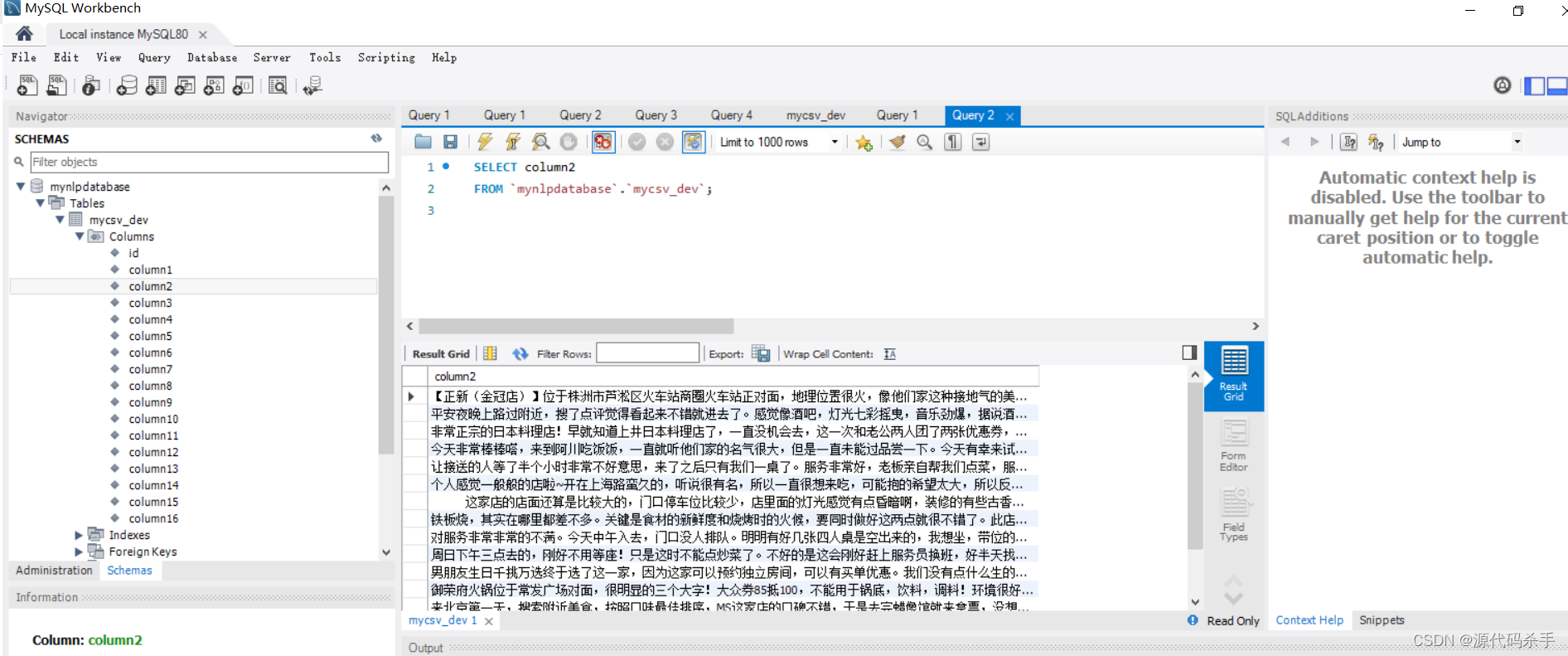
数据集简单介绍
美团点评数据集 (Meituan-Dianping/asap) 是一个中文自然语言处理 (NLP) 数据集,由美团点评公司收集和发布。该数据集用于评估和开发中文文本分类和情感分析模型,包括情感极性分类、食物安全文本分类和自定义分类等任务。
数据集包含两个部分:训练集和测试集。训练集共包含20万条评论,其中13.5万条正向评论和6.5万条负向评论。测试集包含5万条评论,其中3.5万条正向评论和1.5万条负向评论。所有的评论都来自美团点评网站上的真实用户,包括用户对餐厅、美食、酒店、旅游景点、电影等的评论。
该数据集的标注方式为情感极性分类,分为正向和负向两个类别。数据集的分布均匀,类别之间的比例为正向评论与负向评论的比例为 2:1。每个样本的标签是人工标注的,该数据集的标注精度很高。
此外,该数据集还提供了一些其他的信息,如评论内容、所属分类、商户名称、评论时间等。
Meituan-Dianping/asap 数据集已被广泛用于中文情感分析、文本分类等任务的研究和评测。通过使用该数据集进行实验和比较,研究人员可以更好地评估和改进其模型的性能。
该数据集可以通过美团点评官方网站或者 GitHub 上进行下载和使用。
数据集参考地址:https://github.com/Meituan-Dianping/asap
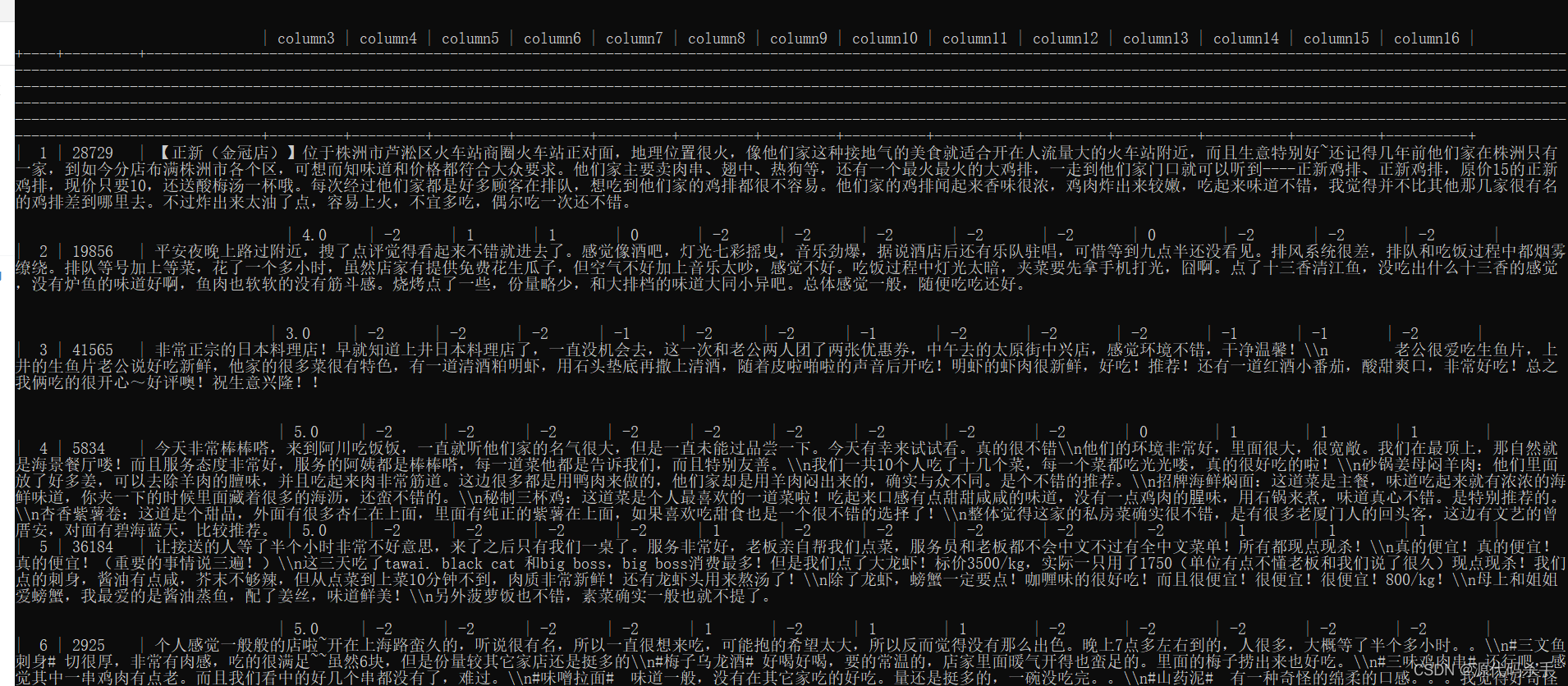
下面完整代码使用的是dev.csv:
完整代码实现
import mysql.connector # 导入mysql连接器模块
import pandas as pd # 导入pandas模块
import math # 导入math模块# 定义函数,读取csv文件并转换为列表
def read_csv(filepath):data = pd.read_csv(filepath) # 读取csv文件data_list = data.values.tolist() # 将读取的数据转换为列表return data_list# 定义函数,创建数据库
def create_database(dbname, host, user, password):mydb = mysql.connector.connect(host=host, # 数据库主机地址user=user, # 数据库用户名password=password # 数据库密码)mycursor = mydb.cursor() # 创建游标对象mycursor.execute(f"DROP DATABASE IF EXISTS {dbname};") # 如果数据库已经存在则删除mycursor.execute(f"CREATE DATABASE {dbname}") # 创建数据库mydb.close() # 关闭数据库连接# 定义函数,连接数据库
def connect_database(dbname, host, user, password):mydb = mysql.connector.connect(host=host, # 数据库主机地址user=user, # 数据库用户名password=password, # 数据库密码database=dbname # 数据库名称)return mydb # 返回数据库连接对象# 定义函数,创建表
def create_table(mydb, tablename, columns):mycursor = mydb.cursor() # 创建游标对象cols = ', '.join([f"{col} VARCHAR(1000)" for col in columns]) # 创建表的列信息# mycursor.execute(f"ALTER TABLE {tablename} {retcs}")# mycursor.execute(f"OPTIMIZE TABLE {tablename}")mycursor.execute(f"CREATE TABLE IF NOT EXISTS {tablename} (id INT AUTO_INCREMENT PRIMARY KEY, {cols})") # 创建表# retcs = "ALTER TABLE mycsv_dev " + retcs# optable = "OPTIMIZE TABLE mycsv_dev"# id为主键列,自动递增# 定义函数,插入数据
def insert_data(mydb, tablename, data):mycursor = mydb.cursor() # 创建游标对象columns = [f"column{i+1}" for i in range(len(data))] # 创建表的列名cols = ', '.join(columns) # 将列名转换为字符串vals = ', '.join(['%s' for i in range(len(data[0]))]) # 创建占位符sql = f"INSERT INTO {tablename} ({cols}) VALUES ({vals})" # 创建插入数据的SQL语句for row in data:mycursor.execute(sql, row) # 执行SQL语句,插入数据mydb.commit() # 提交事务# 定义函数,生成数据
def generate_data():x_list,y_list,z_list = [],[],[]for i in range(3):i = 0.5*i*(math.pi)+4 # 生成数据x = math.sin(i)y = math.cos(i)z = math.tan(i)x_list.append(x)y_list.append(y)z_list.append(z)data1 = x_listdata2 = y_listdata3 = z_listdata = [data1, data2, data3]return data# 读取csv文件
data = read_csv('dev.csv')datas = []# 生成行数据
for i in range(16):datas.append(data[i][0:16])# datas.append(data[0][0:4])
# datas.append(data[1][0:4])
# datas.append(data[2][0:4])
# datas.append(data[3][0:4])print(datas)
if __name__ == '__main__':# 创建数据库create_database('mynlpdatabase', 'localhost', 'root', '密码')# 连接数据库mydb = connect_database('mynlpdatabase', 'localhost', 'root', '密码')# 创建表的列columnlist = []retcs = ""for cs in range(16):dps = "column"+str(cs+1)columnlist.append(dps)# ALTER TABLE my_table MODIFY COLUMN column1 TEXT;strsql = "MODIFY COLUMN column"+str(cs+1)+" BLOB"retcs += strsql + ","print("columnlist:",columnlist)print("strsql:", retcs[:-1])# create_table(mydb, 'mycsv_dev', columnlist)create_table(mydb, 'mycsv_dev', columnlist)## # # 插入数据# data = generate_data()insert_data(mydb, 'mycsv_dev', datas)#print("记录插入成功.")运行结果为前面的图片截图。
参考资料
[1] “ASAP is a large-scale Chinese restaurant review dataset for Aspect category Sentiment Analysis (ACSA) and review rating Prediction (RP). ASAP includes 46, 730 genuine user reviews from the Dianping App, a leading Online-to-Offline (O2O) e-commerce platform. Besides a 5-star scale rating, each review is manually annotated according to its …”
URL: https://github.com/Meituan-Dianping/asap
[2] “一、简介. 情感分析在电子商务中引起了越来越多的关注。. 用户评论背后的情感倾向对商业智能具有重要价值。. aspect类别情感分析(ACSA)和评论评分预测(RP)是检测从细到粗的情感倾向的两个基本任务。. ACSA和RP是高度相关的,通常在现实世界的电子商务 …”
URL: https://zhuanlan.zhihu.com/p/425981216
[3] “[2] Bu J, Ren L, Zheng S, et al. ASAP: A Chinese Review Dataset Towards Aspect Category Sentiment Analysis and Rating Prediction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.”
URL: https://tech.meituan.com/2021/10/20/%E6%83%85%E6%84%9F%E5%88%86%E6%9E%90%E6%8A%80%E6%9C%AF%E5%9C%A8%E7%BE%8E%E5%9B%A2%E7%9A%84%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%BA%94%E7%94%A8.html
[4] “在ASAP数据集中平均每条评论包含5.8个属性,是RESTAURANT数据集的4.7倍,相对于RESTAURANT数据集具有更大的挑战性。 属性级情感分析多任务学习框架: 在该类问题上,业界主流技术方案根据模型结构不同可以分为两种,分别为基于非预训练模型的方案和基于预训练模型的方案。”
URL: https://blog.csdn.net/qq_27590277/article/details/120916034
[5] “美团研究院. 美团研究院是美团设立的社会科学研究机构,旨在依托美团发展服务业的实践探索和海量的数据,围绕国民经济、产业经济、社会发展和改革开放中的前沿问题,构建开放合作的研究平台,深入开展学术研究、政策研究和专题研究,输出高质量研究 …”
URL: https://about.meituan.com/institute
[6] “作为与开放平台长期合作的餐饮服务商,在与美团业务对接期间一直保持紧密合作,其最大的感触是,从2017年以来,开放平台一直尽力保证系统接口稳定运行,团队执行力强,以顺畅的运营和沟通渠道推动了高效率的业态。”
URL: https://developer.meituan.com/isv
[7] “ASAP自动短文评分 [Kaggle] 共八个作文集,每一集作文都围绕一个主题展开。. 短文的平均长度为150到550个字。. 一些文章依赖于主题信息,另一些则是自由发挥。. 所有文章都是由7年级到10年级的学生撰写的,并经相关人员手工评分,有些还进行了双重评分(100 MB).”
URL: https://yuanzhuo.bnu.edu.cn/article/34
[8] “1.概述. 美团网的爬虫整体其实比较简单,通过开发者模式找到真实数据请求地址后, 用requests请求的数据格式是标准的json字符串 ,非常好处理。. 在本文我们将介绍两种常见的获取数据的方式,其一是 通过搜索获取结果 ,其二是 通过筛选获取结果 。. 两种 …”
URL: https://cloud.tencent.com/developer/article/1856418
[9] “美团到店餐饮算法团队在跨域迁移学习的长期实践中,基于多场景的业务背景,提出了分层信息抽取网络,提升了多场景多任务的建模效果。相关技术方案形成的学术论文已经被国际数据工程会议ICDE 2023收录,本文详细阐述了多场景&多任务学习的解决方案,希望能给从事相关方向研究的同学带来 …”
URL: https://tech.meituan.com/
[10] “数据集的简单预处理:. 降采样将频率降到128Hz,并选取了40个通道数据,其中包含了32个脑电通道。. 并将其带通滤波至4-45Hz。. 每个样本数据长 63s,其中包含了3s的基线时间。. 实验数据一般选取官网可下载的预处理 ( 降采样,去除眼电等噪声) 之后的数据(两个 …”
URL: https://blog.csdn.net/qq_45874683/article/details/118966083
这篇关于【MySQL数据库原理】数据库批量导入美团NLP分类数据集Meituan-Dianping/asap的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






